Learned Compression of Encoding Distributions

0
Sign in to get full access
Overview
- This paper introduces a novel approach for compressing encoding distributions, which is a fundamental problem in the field of deep learning.
- The proposed method can be used to efficiently store and transmit complex probability distributions, such as those learned by neural networks.
- The authors demonstrate the effectiveness of their approach on a range of tasks, including image and language modeling, and show that it outperforms existing compression techniques.
Plain English Explanation
The paper discusses a new way to compress the information stored in deep learning models. Deep learning models often learn complex probability distributions, which describe the likelihood of different patterns or outputs occurring. Towards Task-Compatible Compressible Representations, Adaptive Compression for Federated Learning via Side Information, and Robustly Overfitting Latents for Flexible Neural Image Compression have explored similar problems.
The authors' approach allows these probability distributions to be compressed efficiently, so they can be stored or transmitted more easily. This could be useful for applications like running deep learning models on mobile devices with limited storage, or sharing model parameters between different computers in a distributed system. The authors show that their method outperforms existing techniques for compressing these probability distributions, making it a promising new tool for deep learning researchers and engineers.
Technical Explanation
The core idea of the proposed method is to learn a compressed representation of the encoding distribution, rather than the encodings themselves. The authors use a neural network to map the original high-dimensional encoding distribution to a lower-dimensional latent space, which can then be stored or transmitted more efficiently.
To train this compression model, the authors use a combination of adversarial training and variational inference techniques. The adversarial component encourages the compressed latent representations to capture the important statistical properties of the original encoding distribution, while the variational inference component ensures the latent space is well-behaved and easy to sample from.
The authors evaluate their approach on a range of tasks, including Correcting Diffusion-based Perceptual Image Compression with Privileged Information and Multiscale Augmented Normalizing Flows for Image Compression. They show that their method outperforms existing compression techniques, while preserving the key statistical properties of the original encoding distributions.
Critical Analysis
The authors present a compelling approach for compressing encoding distributions, which could have significant practical applications in deep learning. However, the paper does not address some important caveats and limitations:
- The compression model is trained in an unsupervised manner, which means it may not preserve the most relevant statistical properties for a given downstream task. Incorporating task-specific information into the compression process could lead to even better results.
- The performance of the compression model is heavily dependent on the quality of the original encoding distributions. If these distributions are noisy or biased, the compressed representations may also be affected.
- The authors only evaluate their method on a limited set of tasks and datasets. Further testing on a wider range of applications would be necessary to fully assess the generalizability of the approach.
Overall, the paper introduces an interesting new technique for compressing encoding distributions, but more research is needed to address these potential issues and explore the broader implications of this work.
Conclusion
This paper presents a novel method for efficiently compressing the encoding distributions learned by deep learning models. By mapping these high-dimensional distributions to a lower-dimensional latent space, the authors demonstrate a way to store and transmit complex probabilistic information more effectively. While the approach shows promising results, there are some limitations that warrant further investigation. Nonetheless, this work represents an important step forward in the ongoing effort to improve the efficiency and flexibility of deep learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learned Compression of Encoding Distributions
Mateen Ulhaq, Ivan V. Baji'c
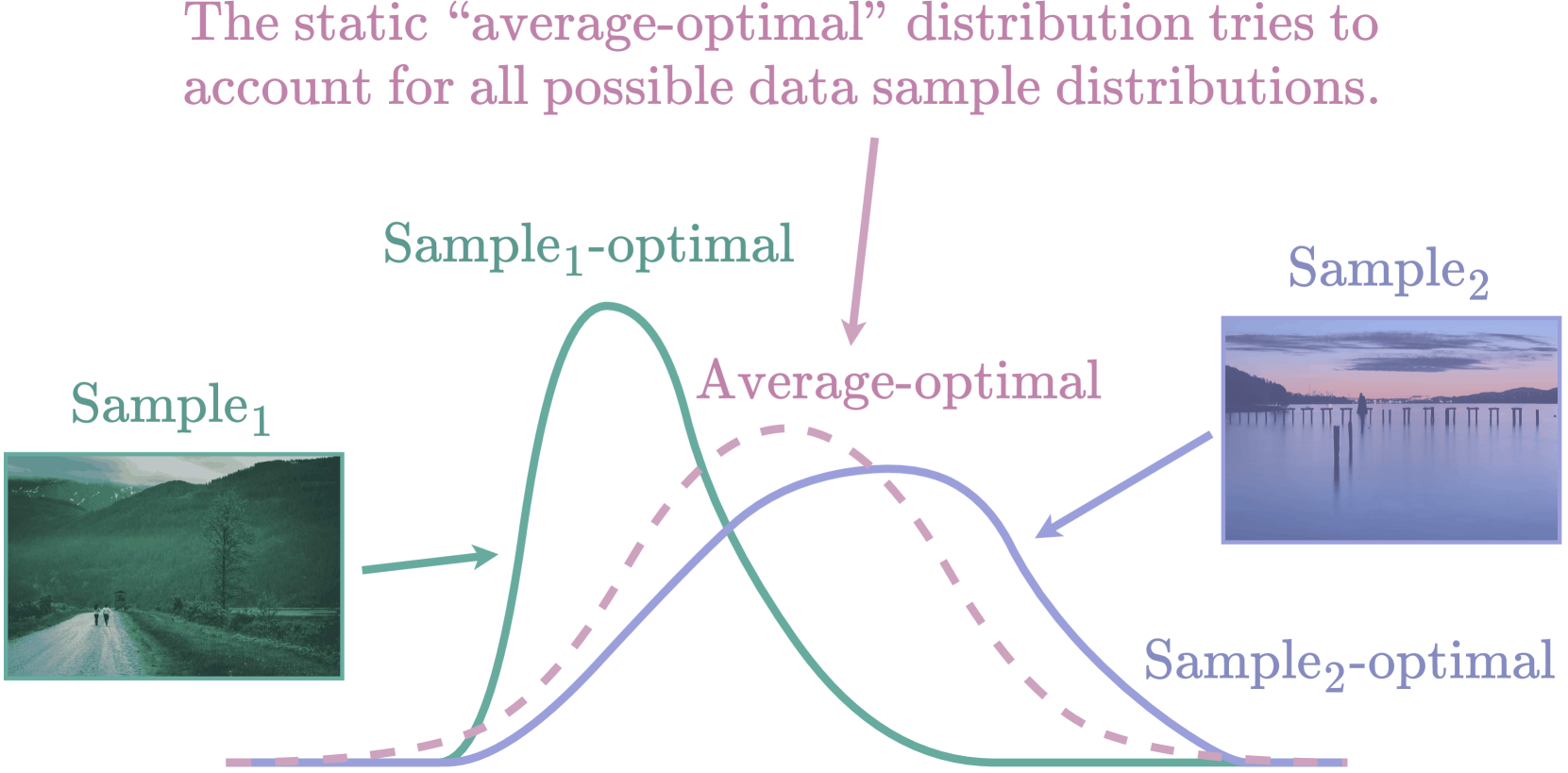
The entropy bottleneck introduced by Ball'e et al. is a common component used in many learned compression models. It encodes a transformed latent representation using a static distribution whose parameters are learned during training. However, the actual distribution of the latent data may vary wildly across different inputs. The static distribution attempts to encompass all possible input distributions, thus fitting none of them particularly well. This unfortunate phenomenon, sometimes known as the amortization gap, results in suboptimal compression. To address this issue, we propose a method that dynamically adapts the encoding distribution to match the latent data distribution for a specific input. First, our model estimates a better encoding distribution for a given input. This distribution is then compressed and transmitted as an additional side-information bitstream. Finally, the decoder reconstructs the encoding distribution and uses it to decompress the corresponding latent data. Our method achieves a Bj{o}ntegaard-Delta (BD)-rate gain of -7.10% on the Kodak test dataset when applied to the standard fully-factorized architecture. Furthermore, considering computational complexity, the transform used by our method is an order of magnitude cheaper in terms of Multiply-Accumulate (MAC) operations compared to related side-information methods such as the scale hyperprior.
Read more6/21/2024

0
New!Learned Compression for Images and Point Clouds
Mateen Ulhaq
Over the last decade, deep learning has shown great success at performing computer vision tasks, including classification, super-resolution, and style transfer. Now, we apply it to data compression to help build the next generation of multimedia codecs. This thesis provides three primary contributions to this new field of learned compression. First, we present an efficient low-complexity entropy model that dynamically adapts the encoding distribution to a specific input by compressing and transmitting the encoding distribution itself as side information. Secondly, we propose a novel lightweight low-complexity point cloud codec that is highly specialized for classification, attaining significant reductions in bitrate compared to non-specialized codecs. Lastly, we explore how motion within the input domain between consecutive video frames is manifested in the corresponding convolutionally-derived latent space.
Read more9/16/2024
⛏️
0
Disentangled Representation Learning with Transmitted Information Bottleneck
Zhuohang Dang, Minnan Luo, Chengyou Jia, Guang Dai, Jihong Wang, Xiaojun Chang, Jingdong Wang
Encoding only the task-related information from the raw data, ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose textbf{DisTIB} (textbf{T}ransmitted textbf{I}nformation textbf{B}ottleneck for textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
Read more8/15/2024

0
Towards Task-Compatible Compressible Representations
Anderson de Andrade, Ivan Baji'c
We identify an issue in multi-task learnable compression, in which a representation learned for one task does not positively contribute to the rate-distortion performance of a different task as much as expected, given the estimated amount of information available in it. We interpret this issue using the predictive $mathcal{V}$-information framework. In learnable scalable coding, previous work increased the utilization of side-information for input reconstruction by also rewarding input reconstruction when learning this shared representation. We evaluate the impact of this idea in the context of input reconstruction more rigorously and extended it to other computer vision tasks. We perform experiments using representations trained for object detection on COCO 2017 and depth estimation on the Cityscapes dataset, and use them to assist in image reconstruction and semantic segmentation tasks. The results show considerable improvements in the rate-distortion performance of the assisted tasks. Moreover, using the proposed representations, the performance of the base tasks are also improved. Results suggest that the proposed method induces simpler representations that are more compatible with downstream processes.
Read more7/16/2024