Multiscale Augmented Normalizing Flows for Image Compression

0
🖼️
Sign in to get full access
Overview
- Current learning-based image compression methods struggle to achieve high image quality due to their non-invertible design.
- Compressive autoencoder architectures, which are commonly used, only approximate the inverse of the encoding transform.
- Invertible latent variable models, like augmented normalizing flows, can enable perfect reconstruction without quantization.
- Many traditional image and video codecs use dynamic block partitioning to vary compression based on content, inspiring the use of hierarchical latent spaces in learning-based compression.
Plain English Explanation
Image compression is the process of reducing the size of digital images while preserving their quality. Many modern AI-powered image compression methods use an encoder-decoder architecture, where an encoder transforms the image into a compact representation and a decoder reconstructs the original image from this representation.
However, the decoder in these models is often just an approximate inverse of the encoder, which can lead to quality issues, especially at high compression levels. Invertible models, like augmented normalizing flows, provide a way to achieve perfect reconstruction if no quantization (rounding) is applied to the compressed representation.
Inspired by traditional image and video codecs that use variable block sizes to adapt compression to image content, some researchers have explored using hierarchical latent spaces in learning-based compression. This allows the model to allocate more bits to important image regions and fewer bits to less critical areas, leading to more efficient compression.
Technical Explanation
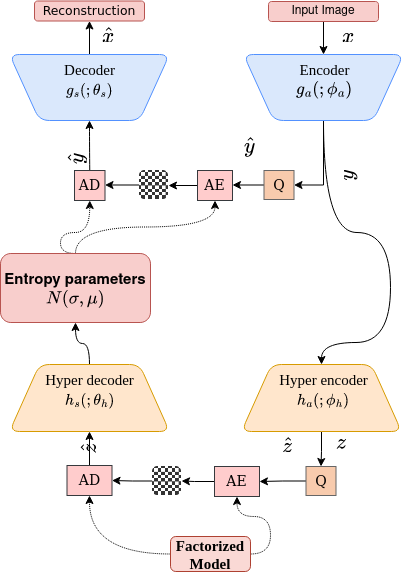
This paper presents a novel concept that adapts the hierarchical latent space approach for use with augmented normalizing flows, an invertible latent variable model. Augmented normalizing flows are a type of invertible neural network that can achieve lossless compression if no quantization is applied.
By incorporating a hierarchical latent space into the augmented normalizing flow architecture, the model can vary the amount of compression applied to different regions of the image based on their content. This allows the model to achieve higher overall compression rates without sacrificing image quality, compared to single-scale models.
The authors' best-performing model achieved average rate savings of more than 7% over comparable single-scale models, demonstrating the effectiveness of this approach for high-fidelity image compression.
Critical Analysis
While the hierarchical latent space approach shows promising results, the paper does not address the potential impact of quantization on the reconstruction quality. Invertible models like augmented normalizing flows can achieve lossless compression, but in practice, some quantization is usually necessary to achieve practical compression ratios, which could degrade the image quality.
Additionally, the paper focuses on static image compression and does not explore the implications for video compression, where the use of hierarchical latent spaces could offer additional benefits in terms of exploiting temporal redundancy.
Further research is needed to fully understand the trade-offs and limitations of this approach, as well as its applicability to a wider range of image and video compression scenarios.
Conclusion
This paper presents a novel concept that combines the benefits of invertible latent variable models and hierarchical latent spaces for efficient image compression. By allowing the model to adapt the compression level to different image regions, the approach can achieve higher overall compression rates without sacrificing image quality.
The results demonstrate the potential of this technique for high-fidelity image compression, which could have important applications in areas such as medical imaging, remote sensing, and digital archiving. However, further research is needed to fully explore the limitations and broader implications of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Multiscale Augmented Normalizing Flows for Image Compression
Marc Windsheimer, Fabian Brand, Andr'e Kaup
Most learning-based image compression methods lack efficiency for high image quality due to their non-invertible design. The decoding function of the frequently applied compressive autoencoder architecture is only an approximated inverse of the encoding transform. This issue can be resolved by using invertible latent variable models, which allow a perfect reconstruction if no quantization is performed. Furthermore, many traditional image and video coders apply dynamic block partitioning to vary the compression of certain image regions depending on their content. Inspired by this approach, hierarchical latent spaces have been applied to learning-based compression networks. In this paper, we present a novel concept, which adapts the hierarchical latent space for augmented normalizing flows, an invertible latent variable model. Our best performing model achieved average rate savings of more than 7% over comparable single-scale models.
Read more5/24/2024

0
Approximately Invertible Neural Network for Learned Image Compression
Yanbo Gao, Meng Fu, Shuai Li, Chong Lv, Xun Cai, Hui Yuan, Mao Ye
Learned image compression have attracted considerable interests in recent years. It typically comprises an analysis transform, a synthesis transform, quantization and an entropy coding model. The analysis transform and synthesis transform are used to encode an image to latent feature and decode the quantized feature to reconstruct the image, and can be regarded as coupled transforms. However, the analysis transform and synthesis transform are designed independently in the existing methods, making them unreliable in high-quality image compression. Inspired by the invertible neural networks in generative modeling, invertible modules are used to construct the coupled analysis and synthesis transforms. Considering the noise introduced in the feature quantization invalidates the invertible process, this paper proposes an Approximately Invertible Neural Network (A-INN) framework for learned image compression. It formulates the rate-distortion optimization in lossy image compression when using INN with quantization, which differentiates from using INN for generative modelling. Generally speaking, A-INN can be used as the theoretical foundation for any INN based lossy compression method. Based on this formulation, A-INN with a progressive denoising module (PDM) is developed to effectively reduce the quantization noise in the decoding. Moreover, a Cascaded Feature Recovery Module (CFRM) is designed to learn high-dimensional feature recovery from low-dimensional ones to further reduce the noise in feature channel compression. In addition, a Frequency-enhanced Decomposition and Synthesis Module (FDSM) is developed by explicitly enhancing the high-frequency components in an image to address the loss of high-frequency information inherent in neural network based image compression. Extensive experiments demonstrate that the proposed A-INN outperforms the existing learned image compression methods.
Read more9/2/2024
0
Universal End-to-End Neural Network for Lossy Image Compression
Bouzid Arezki, Fangchen Feng, Anissa Mokraoui
This paper presents variable bitrate lossy image compression using a VAE-based neural network. An adaptable image quality adjustment strategy is proposed. The key innovation involves adeptly adjusting the input scale exclusively during the inference process, resulting in an exceptionally efficient rate-distortion mechanism. Through extensive experimentation, across diverse VAE-based compression architectures (CNN, ViT) and training methodologies (MSE, SSIM), our approach exhibits remarkable universality. This success is attributed to the inherent generalization capacity of neural networks. Unlike methods that adjust model architecture or loss functions, our approach emphasizes simplicity, reducing computational complexity and memory requirements. The experiments not only highlight the effectiveness of our approach but also indicate its potential to drive advancements in variable-rate neural network lossy image compression methodologies.
Read more9/11/2024

0
Robustly overfitting latents for flexible neural image compression
Yura Perugachi-Diaz, Arwin Gansekoele, Sandjai Bhulai
Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models. We extend this idea by introducing SGA+, which contains three different methods that build upon SGA. We show how our method improves the overall compression performance in terms of the R-D trade-off, compared to its predecessors. Additionally, we show how refinement of the latents with our best-performing method improves the compression performance on both the Tecnick and CLIC dataset. Our method is deployed for a pre-trained hyperprior and for a more flexible model. Further, we give a detailed analysis of our proposed methods and show that they are less sensitive to hyperparameter choices. Finally, we show how each method can be extended to three- instead of two-class rounding.
Read more5/27/2024