Learning Adaptive Fusion Bank for Multi-modal Salient Object Detection

0

Sign in to get full access
Overview
- This research paper proposes a novel approach called the Learning Adaptive Fusion Bank (LAFB) for multi-modal salient object detection (SOD).
- The key idea is to adaptively fuse multi-modal features, such as RGB, depth, and infrared, to improve SOD performance.
- The LAFB framework includes an adaptive fusion bank that learns to dynamically weight and combine the different modalities based on the input data.
- The authors also introduce an indirect interactive guidance module to further enhance the SOD performance.
Plain English Explanation
The paper tackles the problem of salient object detection, which is the task of identifying the most important or visually striking objects in an image. Traditional approaches often rely on a single type of visual information, such as color or texture. However, in many real-world scenarios, different types of visual data (e.g., color, depth, infrared) may be available, and effectively combining these "multi-modal" cues can lead to better salient object detection.
The researchers developed a system called the Learning Adaptive Fusion Bank (LAFB) that can dynamically weighted and fuse these multi-modal features to improve salient object detection. The key idea is to let the model learn how to best combine the different types of visual information, rather than relying on a fixed fusion strategy. This adaptive fusion approach allows the model to perform well across a wide range of scenarios.
Additionally, the researchers introduced an "indirect interactive guidance" module, which helps the model better understand the relationships between different salient objects in the image. This further enhances the model's ability to accurately detect salient objects.
Overall, this research advances the state-of-the-art in salient object detection by leveraging multi-modal data and adaptive fusion techniques. By combining complementary visual cues in an intelligent way, the LAFB model can outperform previous approaches, paving the way for more robust and accurate salient object detection in real-world applications.
Technical Explanation
The paper proposes a Learning Adaptive Fusion Bank (LAFB) framework for multi-modal salient object detection (SOD). The core of the LAFB is an adaptive fusion bank that learns to dynamically weight and combine features from different modalities, such as RGB, depth, and infrared.
The fusion bank consists of a set of parallel fusion modules, each with its own learnable fusion weights. This allows the model to adaptively adjust the contribution of each modality based on the input. The authors also introduce an indirect interactive guidance module, which models the relationships between salient objects to further improve SOD performance.
The LAFB framework is evaluated on several multi-modal SOD benchmarks, demonstrating state-of-the-art results. Compared to previous methods that use fixed fusion strategies, the adaptive fusion approach of LAFB leads to significant performance gains, showcasing the benefits of learning how to effectively combine multi-modal cues.
Critical Analysis
The paper presents a well-designed and compelling approach to multi-modal salient object detection. The key strength of the LAFB framework is its ability to adaptively fuse features from different modalities, allowing the model to effectively leverage complementary visual information.
However, one potential limitation is the computational complexity of the fusion bank, which consists of multiple parallel fusion modules. While this adaptive fusion strategy improves performance, it may also increase the model's inference time and memory requirements, which could be a concern for real-time or resource-constrained applications.
Additionally, the authors note that the LAFB framework assumes the availability of multi-modal data during training and inference. In scenarios where only a subset of modalities is available, the model's performance may degrade. Further research could explore strategies to handle missing modalities or to learn modality-agnostic representations.
Overall, the LAFB framework represents a valuable contribution to the field of multi-modal salient object detection. By adaptively fusing complementary visual cues, the model achieves state-of-the-art results and sets the stage for further advancements in this area.
Conclusion
This research paper introduces the Learning Adaptive Fusion Bank (LAFB), a novel approach for multi-modal salient object detection. The key innovation is the adaptive fusion bank, which learns to dynamically weight and combine features from different modalities, such as RGB, depth, and infrared.
The LAFB framework also includes an indirect interactive guidance module to further enhance salient object detection performance. Experimental results demonstrate that the LAFB outperforms previous multi-modal SOD methods, highlighting the benefits of adaptive feature fusion and modeling the relationships between salient objects.
This work advances the state-of-the-art in salient object detection by leveraging multi-modal data and intelligent fusion techniques. The LAFB framework has the potential to enable more robust and accurate salient object detection in a wide range of real-world applications, such as image understanding, robotics, and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Adaptive Fusion Bank for Multi-modal Salient Object Detection
Kunpeng Wang, Zhengzheng Tu, Chenglong Li, Cheng Zhang, Bin Luo
Multi-modal salient object detection (MSOD) aims to boost saliency detection performance by integrating visible sources with depth or thermal infrared ones. Existing methods generally design different fusion schemes to handle certain issues or challenges. Although these fusion schemes are effective at addressing specific issues or challenges, they may struggle to handle multiple complex challenges simultaneously. To solve this problem, we propose a novel adaptive fusion bank that makes full use of the complementary benefits from a set of basic fusion schemes to handle different challenges simultaneously for robust MSOD. We focus on handling five major challenges in MSOD, namely center bias, scale variation, image clutter, low illumination, and thermal crossover or depth ambiguity. The fusion bank proposed consists of five representative fusion schemes, which are specifically designed based on the characteristics of each challenge, respectively. The bank is scalable, and more fusion schemes could be incorporated into the bank for more challenges. To adaptively select the appropriate fusion scheme for multi-modal input, we introduce an adaptive ensemble module that forms the adaptive fusion bank, which is embedded into hierarchical layers for sufficient fusion of different source data. Moreover, we design an indirect interactive guidance module to accurately detect salient hollow objects via the skip integration of high-level semantic information and low-level spatial details. Extensive experiments on three RGBT datasets and seven RGBD datasets demonstrate that the proposed method achieves the outstanding performance compared to the state-of-the-art methods. The code and results are available at https://github.com/Angknpng/LAFB.
Read more6/4/2024

0
Modality Prompts for Arbitrary Modality Salient Object Detection
Nianchang Huang, Yang Yang, Qiang Zhang, Jungong Han, Jin Huang
This paper delves into the task of arbitrary modality salient object detection (AM SOD), aiming to detect salient objects from arbitrary modalities, eg RGB images, RGB-D images, and RGB-D-T images. A novel modality-adaptive Transformer (MAT) will be proposed to investigate two fundamental challenges of AM SOD, ie more diverse modality discrepancies caused by varying modality types that need to be processed, and dynamic fusion design caused by an uncertain number of modalities present in the inputs of multimodal fusion strategy. Specifically, inspired by prompt learning's ability of aligning the distributions of pre-trained models to the characteristic of downstream tasks by learning some prompts, MAT will first present a modality-adaptive feature extractor (MAFE) to tackle the diverse modality discrepancies by introducing a modality prompt for each modality. In the training stage, a new modality translation contractive (MTC) loss will be further designed to assist MAFE in learning those modality-distinguishable modality prompts. Accordingly, in the testing stage, MAFE can employ those learned modality prompts to adaptively adjust its feature space according to the characteristics of the input modalities, thus being able to extract discriminative unimodal features. Then, MAFE will present a channel-wise and spatial-wise fusion hybrid (CSFH) strategy to meet the demand for dynamic fusion. For that, CSFH dedicates a channel-wise dynamic fusion module (CDFM) and a novel spatial-wise dynamic fusion module (SDFM) to fuse the unimodal features from varying numbers of modalities and meanwhile effectively capture cross-modal complementary semantic and detail information, respectively. Moreover, CSFH will carefully align CDFM and SDFM to different levels of unimodal features based on their characteristics for more effective complementary information exploitation.
Read more5/7/2024
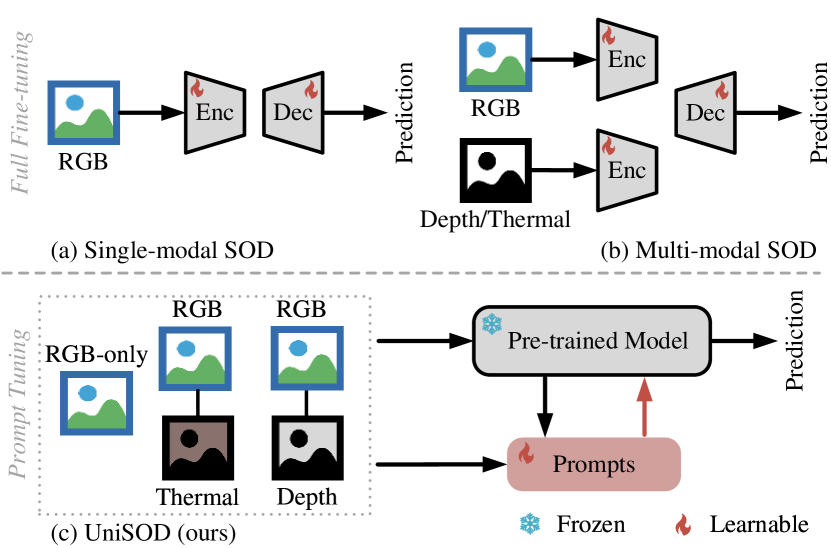
0
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Kunpeng Wang, Chenglong Li, Zhengzheng Tu, Zhengyi Liu, Bin Luo
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD, which fully exploits the overlapping prior knowledge between different tasks. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which adaptively performs structural switching based on single-modal and multi-modal inputs without human intervention. Through end-to-end joint training, UniSOD achieves overall performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.The code and results are available at https://github.com/Angknpng/UniSOD.
Read more6/6/2024
🔎
0
Salient Object Detection From Arbitrary Modalities
Nianchang Huang, Yang Yang, Ruida Xi, Qiang Zhang, Jungong Han, Jin Huang
Toward desirable saliency prediction, the types and numbers of inputs for a salient object detection (SOD) algorithm may dynamically change in many real-life applications. However, existing SOD algorithms are mainly designed or trained for one particular type of inputs, failing to be generalized to other types of inputs. Consequentially, more types of SOD algorithms need to be prepared in advance for handling different types of inputs, raising huge hardware and research costs. Differently, in this paper, we propose a new type of SOD task, termed Arbitrary Modality SOD (AM SOD). The most prominent characteristics of AM SOD are that the modality types and modality numbers will be arbitrary or dynamically changed. The former means that the inputs to the AM SOD algorithm may be arbitrary modalities such as RGB, depths, or even any combination of them. While, the latter indicates that the inputs may have arbitrary modality numbers as the input type is changed, e.g. single-modality RGB image, dual-modality RGB-Depth (RGB-D) images or triple-modality RGB-Depth-Thermal (RGB-D-T) images. Accordingly, a preliminary solution to the above challenges, i.e. a modality switch network (MSN), is proposed in this paper. In particular, a modality switch feature extractor (MSFE) is first designed to extract discriminative features from each modality effectively by introducing some modality indicators, which will generate some weights for modality switching. Subsequently, a dynamic fusion module (DFM) is proposed to adaptively fuse features from a variable number of modalities based on a novel Transformer structure. Finally, a new dataset, named AM-XD, is constructed to facilitate research on AM SOD. Extensive experiments demonstrate that our AM SOD method can effectively cope with changes in the type and number of input modalities for robust salient object detection.
Read more5/10/2024