Unified-modal Salient Object Detection via Adaptive Prompt Learning

0
Sign in to get full access
Overview
- This paper proposes a new approach for salient object detection that can handle input from different modalities, such as images, text, and audio.
- The key idea is to use adaptive prompt learning, which allows the model to adjust its prompts based on the input modality, to achieve unified-modal salient object detection.
- The model is designed to be efficient and can be applied to a variety of salient object detection tasks, including Modality-agnostic Salient Object Detection, Unified Unsupervised Salient Object Detection, and Salient Object Detection from Arbitrary Modalities.
Plain English Explanation
Salient object detection is the task of identifying the most important or interesting objects in an image or other visual data. Traditional approaches to this problem have often been limited to a single input modality, such as just images.
The researchers in this paper wanted to develop a more flexible and versatile system that could handle input from different modalities, like images, text, and audio. Their key insight was to use a technique called "adaptive prompt learning," which allows the model to adjust its internal prompts or instructions based on the specific input modality.
By using this adaptive prompt learning approach, the model is able to unify its handling of different input modalities, rather than having to use separate models or approaches for each one. This makes the system more efficient and broadly applicable to a variety of salient object detection tasks, such as Modality-agnostic Salient Object Detection, Unified Unsupervised Salient Object Detection, and Salient Object Detection from Arbitrary Modalities.
The key benefit of this approach is that it allows for more flexible and powerful salient object detection systems that can handle a wider range of inputs, opening up new possibilities for applications in areas like computer vision, image analysis, and content understanding.
Technical Explanation
The researchers propose a new unified-modal salient object detection framework that can handle input from different modalities, including images, text, and audio. The core of their approach is adaptive prompt learning, which allows the model to adjust its internal prompts or instructions based on the specific input modality.
The model consists of a modality-specific encoder that processes the input data, and a shared salient object detection module that generates the final salient object detection output. The modality-specific encoder uses a series of adaptive prompts to transform the input into a common representation that can be processed by the shared module.
The adaptive prompts are learned during training, and they allow the model to effectively handle different input modalities without requiring separate models or approaches for each one. This unified-modal approach makes the system more efficient and broadly applicable to a variety of salient object detection tasks, including Modality-agnostic Salient Object Detection, Unified Unsupervised Salient Object Detection, and Salient Object Detection from Arbitrary Modalities.
The researchers evaluate their model on several benchmark datasets and demonstrate its effectiveness in comparison to state-of-the-art approaches. They also show that the model can be efficiently fine-tuned for specific tasks using External Prompt Features and General Visual Salient Camouflaged Object Detection, further expanding its applicability.
Critical Analysis
The researchers provide a thorough evaluation of their unified-modal salient object detection framework, demonstrating its effectiveness across a range of benchmark datasets and tasks. However, the paper does not address some potential limitations or areas for further research:
- The adaptive prompts are learned during training, which may limit the model's ability to handle completely novel input modalities that were not seen during the training process. Exploring more dynamic or generative prompt learning approaches could help address this.
- The paper focuses on relatively simple input modalities like images, text, and audio, but the model's performance on more complex or multimodal inputs (e.g., video, sensor data) is not evaluated. Assessing the model's scalability and robustness to diverse inputs would be valuable.
- While the paper shows that the model can be efficiently fine-tuned for specific tasks, the extent to which the learned representations and prompts are transferable to other salient object detection problems is not fully explored.
Overall, the unified-modal salient object detection framework presented in this paper is a promising step towards more flexible and efficient visual analysis systems. However, further research is needed to address the potential limitations and expand the model's capabilities to handle increasingly complex and diverse inputs.
Conclusion
This paper introduces a novel unified-modal salient object detection framework that can effectively handle input from different modalities, such as images, text, and audio. The key innovation is the use of adaptive prompt learning, which allows the model to adjust its internal prompts based on the specific input modality, enabling a more unified and efficient approach to salient object detection.
The researchers demonstrate the effectiveness of their model on several benchmark datasets and show its applicability to a variety of salient object detection tasks, including Modality-agnostic Salient Object Detection, Unified Unsupervised Salient Object Detection, and Salient Object Detection from Arbitrary Modalities.
The unified-modal nature of the proposed framework opens up new possibilities for more flexible and powerful visual analysis systems, with potential applications in areas such as computer vision, image understanding, and content analysis. While the paper highlights several promising aspects of the research, further exploration of the model's limitations and transferability to more complex inputs could further strengthen the contributions of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Kunpeng Wang, Chenglong Li, Zhengzheng Tu, Zhengyi Liu, Bin Luo
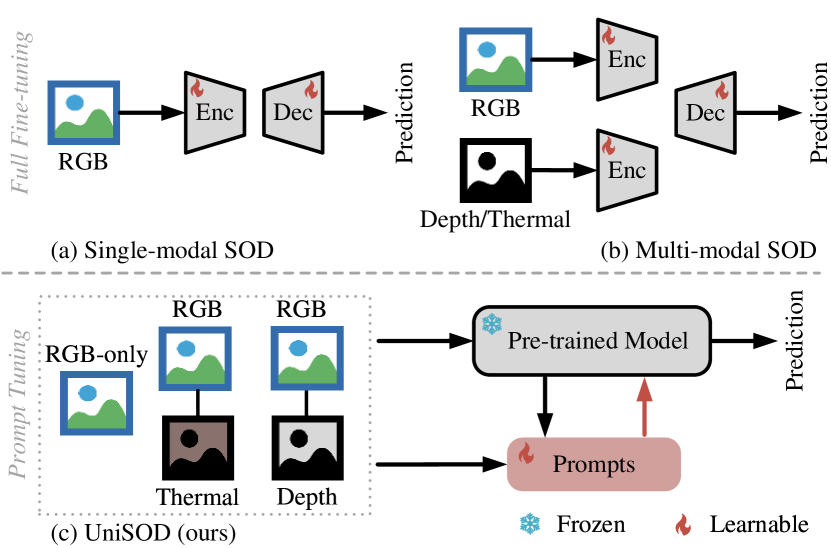
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD, which fully exploits the overlapping prior knowledge between different tasks. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which adaptively performs structural switching based on single-modal and multi-modal inputs without human intervention. Through end-to-end joint training, UniSOD achieves overall performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.The code and results are available at https://github.com/Angknpng/UniSOD.
Read more6/6/2024

0
Modality Prompts for Arbitrary Modality Salient Object Detection
Nianchang Huang, Yang Yang, Qiang Zhang, Jungong Han, Jin Huang
This paper delves into the task of arbitrary modality salient object detection (AM SOD), aiming to detect salient objects from arbitrary modalities, eg RGB images, RGB-D images, and RGB-D-T images. A novel modality-adaptive Transformer (MAT) will be proposed to investigate two fundamental challenges of AM SOD, ie more diverse modality discrepancies caused by varying modality types that need to be processed, and dynamic fusion design caused by an uncertain number of modalities present in the inputs of multimodal fusion strategy. Specifically, inspired by prompt learning's ability of aligning the distributions of pre-trained models to the characteristic of downstream tasks by learning some prompts, MAT will first present a modality-adaptive feature extractor (MAFE) to tackle the diverse modality discrepancies by introducing a modality prompt for each modality. In the training stage, a new modality translation contractive (MTC) loss will be further designed to assist MAFE in learning those modality-distinguishable modality prompts. Accordingly, in the testing stage, MAFE can employ those learned modality prompts to adaptively adjust its feature space according to the characteristics of the input modalities, thus being able to extract discriminative unimodal features. Then, MAFE will present a channel-wise and spatial-wise fusion hybrid (CSFH) strategy to meet the demand for dynamic fusion. For that, CSFH dedicates a channel-wise dynamic fusion module (CDFM) and a novel spatial-wise dynamic fusion module (SDFM) to fuse the unimodal features from varying numbers of modalities and meanwhile effectively capture cross-modal complementary semantic and detail information, respectively. Moreover, CSFH will carefully align CDFM and SDFM to different levels of unimodal features based on their characteristics for more effective complementary information exploitation.
Read more5/7/2024
🤷
0
Unified Unsupervised Salient Object Detection via Knowledge Transfer
Yao Yuan, Wutao Liu, Pan Gao, Qun Dai, Jie Qin
Recently, unsupervised salient object detection (USOD) has gained increasing attention due to its annotation-free nature. However, current methods mainly focus on specific tasks such as RGB and RGB-D, neglecting the potential for task migration. In this paper, we propose a unified USOD framework for generic USOD tasks. Firstly, we propose a Progressive Curriculum Learning-based Saliency Distilling (PCL-SD) mechanism to extract saliency cues from a pre-trained deep network. This mechanism starts with easy samples and progressively moves towards harder ones, to avoid initial interference caused by hard samples. Afterwards, the obtained saliency cues are utilized to train a saliency detector, and we employ a Self-rectify Pseudo-label Refinement (SPR) mechanism to improve the quality of pseudo-labels. Finally, an adapter-tuning method is devised to transfer the acquired saliency knowledge, leveraging shared knowledge to attain superior transferring performance on the target tasks. Extensive experiments on five representative SOD tasks confirm the effectiveness and feasibility of our proposed method. Code and supplement materials are available at https://github.com/I2-Multimedia-Lab/A2S-v3.
Read more7/16/2024
🔎
0
Salient Object Detection From Arbitrary Modalities
Nianchang Huang, Yang Yang, Ruida Xi, Qiang Zhang, Jungong Han, Jin Huang
Toward desirable saliency prediction, the types and numbers of inputs for a salient object detection (SOD) algorithm may dynamically change in many real-life applications. However, existing SOD algorithms are mainly designed or trained for one particular type of inputs, failing to be generalized to other types of inputs. Consequentially, more types of SOD algorithms need to be prepared in advance for handling different types of inputs, raising huge hardware and research costs. Differently, in this paper, we propose a new type of SOD task, termed Arbitrary Modality SOD (AM SOD). The most prominent characteristics of AM SOD are that the modality types and modality numbers will be arbitrary or dynamically changed. The former means that the inputs to the AM SOD algorithm may be arbitrary modalities such as RGB, depths, or even any combination of them. While, the latter indicates that the inputs may have arbitrary modality numbers as the input type is changed, e.g. single-modality RGB image, dual-modality RGB-Depth (RGB-D) images or triple-modality RGB-Depth-Thermal (RGB-D-T) images. Accordingly, a preliminary solution to the above challenges, i.e. a modality switch network (MSN), is proposed in this paper. In particular, a modality switch feature extractor (MSFE) is first designed to extract discriminative features from each modality effectively by introducing some modality indicators, which will generate some weights for modality switching. Subsequently, a dynamic fusion module (DFM) is proposed to adaptively fuse features from a variable number of modalities based on a novel Transformer structure. Finally, a new dataset, named AM-XD, is constructed to facilitate research on AM SOD. Extensive experiments demonstrate that our AM SOD method can effectively cope with changes in the type and number of input modalities for robust salient object detection.
Read more5/10/2024