Learning at a Glance: Towards Interpretable Data-limited Continual Semantic Segmentation via Semantic-Invariance Modelling

0

Sign in to get full access
Overview
- Continual Semantic Segmentation: Updating a model to handle new tasks or classes over time
- Limited Data: Learning new tasks with only a small amount of training data
- Interpretability: Making the model's decision-making process transparent and understandable
- Disentangled Distillation: A technique to transfer knowledge from a larger model to a smaller one
Plain English Explanation
The paper proposes a method for continual semantic segmentation that can learn new tasks or classes over time with limited training data. The key idea is to model the semantic-invariance of the model, which means identifying the aspects of the model that should stay consistent as it learns new information.
This semantic-invariance modeling allows the model to efficiently learn new tasks without forgetting previous ones. The method also incorporates disentangled distillation, which transfers knowledge from a larger model to a smaller one in a way that preserves the model's interpretability.
The goal is to create a continual learning system that can adapt to new tasks or classes with limited data, while still maintaining transparency in how the model makes decisions. This could be useful for applications like autonomous driving, where the model needs to handle new road conditions or object classes over time.
Technical Explanation
The paper introduces a method called "Learning at a Glance" for continual semantic segmentation with limited data. The key components are:
-
Semantic-Invariance Modeling: The model explicitly learns to preserve the semantically-relevant features as it adapts to new tasks. This allows the model to efficiently learn new information without forgetting previous knowledge.
-
Disentangled Distillation: The model transfers knowledge from a larger teacher model to a smaller student model in a way that preserves the model's interpretability. This is done by separating the semantic and non-semantic components of the model.
-
Limited-Data Training: The model can learn new tasks or classes with only a small amount of training data by leveraging the preserved semantic-invariance.
The authors evaluate their method on several continual semantic segmentation benchmarks, showing that it outperforms existing approaches in terms of performance, parameter efficiency, and interpretability.
Critical Analysis
The paper presents a compelling approach to continual semantic segmentation with limited data. The focus on preserving semantic-invariance and disentangled distillation is a novel and promising direction.
However, the paper does not fully address the challenge of negative transfer, where learning new tasks can actually degrade performance on previous ones. The authors mention this issue but do not provide a comprehensive solution.
Additionally, the interpretability of the model is not rigorously evaluated beyond qualitative visualizations. More quantitative metrics or human studies would be helpful to better understand the practical implications of the model's transparency.
Overall, the paper makes a valuable contribution to the field of continual semantic segmentation, but there are still opportunities for further research and development.
Conclusion
The "Learning at a Glance" method presents a novel approach to continual semantic segmentation that can learn new tasks or classes with limited data while preserving the model's interpretability. By modeling semantic-invariance and using disentangled distillation, the method can efficiently adapt to new information without forgetting previous knowledge.
This work has important implications for applications that require flexible and transparent machine learning models, such as autonomous driving or medical image analysis. Further research is needed to address the challenges of negative transfer and to more rigorously evaluate the model's interpretability, but the paper's insights represent a significant step forward in the field of continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning at a Glance: Towards Interpretable Data-limited Continual Semantic Segmentation via Semantic-Invariance Modelling
Bo Yuan, Danpei Zhao, Zhenwei Shi
Continual semantic segmentation (CSS) based on incremental learning (IL) is a great endeavour in developing human-like segmentation models. However, current CSS approaches encounter challenges in the trade-off between preserving old knowledge and learning new ones, where they still need large-scale annotated data for incremental training and lack interpretability. In this paper, we present Learning at a Glance (LAG), an efficient, robust, human-like and interpretable approach for CSS. Specifically, LAG is a simple and model-agnostic architecture, yet it achieves competitive CSS efficiency with limited incremental data. Inspired by human-like recognition patterns, we propose a semantic-invariance modelling approach via semantic features decoupling that simultaneously reconciles solid knowledge inheritance and new-term learning. Concretely, the proposed decoupling manner includes two ways, i.e., channel-wise decoupling and spatial-level neuron-relevant semantic consistency. Our approach preserves semantic-invariant knowledge as solid prototypes to alleviate catastrophic forgetting, while also constraining sample-specific contents through an asymmetric contrastive learning method to enhance model robustness during IL steps. Experimental results in multiple datasets validate the effectiveness of the proposed method. Furthermore, we introduce a novel CSS protocol that better reflects realistic data-limited CSS settings, and LAG achieves superior performance under multiple data-limited conditions.
Read more7/23/2024
🤯
0
A Survey on Continual Semantic Segmentation: Theory, Challenge, Method and Application
Bo Yuan, Danpei Zhao
Continual learning, also known as incremental learning or life-long learning, stands at the forefront of deep learning and AI systems. It breaks through the obstacle of one-way training on close sets and enables continuous adaptive learning on open-set conditions. In the recent decade, continual learning has been explored and applied in multiple fields especially in computer vision covering classification, detection and segmentation tasks. Continual semantic segmentation (CSS), of which the dense prediction peculiarity makes it a challenging, intricate and burgeoning task. In this paper, we present a review of CSS, committing to building a comprehensive survey on problem formulations, primary challenges, universal datasets, neoteric theories and multifarious applications. Concretely, we begin by elucidating the problem definitions and primary challenges. Based on an in-depth investigation of relevant approaches, we sort out and categorize current CSS models into two main branches including data-replay and data-free sets. In each branch, the corresponding approaches are similarity-based clustered and thoroughly analyzed, following qualitative comparison and quantitative reproductions on relevant datasets. Besides, we also introduce four CSS specialities with diverse application scenarios and development tendencies. Furthermore, we develop a benchmark for CSS encompassing representative references, evaluation results and reproductions, which is available at~url{https://github.com/YBIO/SurveyCSS}. We hope this survey can serve as a reference-worthy and stimulating contribution to the advancement of the life-long learning field, while also providing valuable perspectives for related fields.
Read more7/23/2024
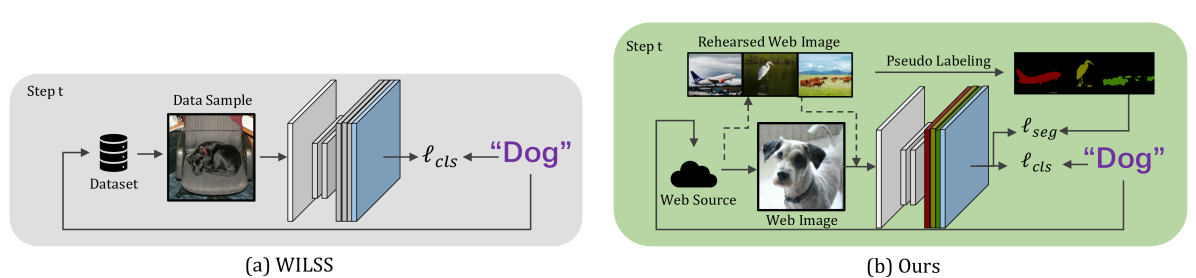
0
Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation
Chang Liu, Giulia Rizzoli, Pietro Zanuttigh, Fu Li, Yi Niu
Current weakly-supervised incremental learning for semantic segmentation (WILSS) approaches only consider replacing pixel-level annotations with image-level labels, while the training images are still from well-designed datasets. In this work, we argue that widely available web images can also be considered for the learning of new classes. To achieve this, firstly we introduce a strategy to select web images which are similar to previously seen examples in the latent space using a Fourier-based domain discriminator. Then, an effective caption-driven reharsal strategy is proposed to preserve previously learnt classes. To our knowledge, this is the first work to rely solely on web images for both the learning of new concepts and the preservation of the already learned ones in WILSS. Experimental results show that the proposed approach can reach state-of-the-art performances without using manually selected and annotated data in the incremental steps.
Read more9/4/2024
🌐
0
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network
Francesco Barbato, Elena Camuffo, Simone Milani, Pietro Zanuttigh
State-of-the-art multimodal semantic segmentation strategies combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. This strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions that make the acquired information unreliable. This problem is exacerbated when continual learning scenarios are considered since they have stringent data reliability constraints. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. We also introduce an ad-hoc class-incremental continual learning scheme, proving our approach's effectiveness and reliability even in safety-critical settings, such as autonomous driving. We evaluate our approach on the SemanticKITTI dataset, achieving impressive performances.
Read more6/26/2024