Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation

0
Sign in to get full access
Overview
- This paper explores a weakly-supervised incremental learning approach for semantic segmentation, which aims to continuously expand the model's knowledge by learning from web-based language data.
- The key idea is to leverage language information, such as image captions and object descriptions, to guide the model's incremental learning process and enable it to segment new objects and scenes without requiring extensive annotated data.
- The proposed approach is evaluated on several benchmarks and shows promising results in expanding the model's segmentation capabilities over time.
Plain English Explanation
Semantic segmentation is the task of dividing an image into meaningful regions, such as identifying different objects, people, or structures. This is a challenging problem, as it requires the model to understand the contents of the image in great detail.
Traditional approaches to semantic segmentation rely on large datasets of images with detailed annotations, which can be time-consuming and expensive to create. The paper introduces a new method that aims to overcome this limitation by leveraging language data from the web.
The key idea is to use language information, such as image captions and object descriptions, to guide the model's learning process. Instead of relying solely on annotated images, the model can continuously expand its knowledge by learning from web-based language data, which is more readily available.
This "weakly-supervised" approach allows the model to learn new concepts and segmentation capabilities over time, without needing to be retrained from scratch on a massive dataset. The authors demonstrate that this approach can lead to significant improvements in the model's segmentation performance on a variety of benchmarks.
By combining language and vision, this research opens up new possibilities for building more flexible and adaptable semantic segmentation models that can continually learn and expand their knowledge.
Technical Explanation
The paper proposes a Weakly-Supervised Semantic Segmentation via Dual Stream framework that leverages language information to guide the incremental learning of a semantic segmentation model.
The core idea is to use a Tendency-Driven Mutual Exclusivity mechanism to selectively incorporate new language-based knowledge into the model's segmentation capabilities. This allows the model to "learn from the web" by continuously expanding its understanding of objects and scenes without requiring extensive annotated data.
The approach is further extended by Enhancing Weakly-Supervised Semantic Segmentation with Multi-Modal information, which integrates both image and language data to improve the model's segmentation performance.
To handle the challenge of Organizing Background to Explore Latent Classes in an incremental learning setting, the authors propose a novel technique that enables the model to effectively segment both foreground objects and background regions.
The Classifier-Free Incremental Learning Framework is used to make the overall approach more scalable and efficient, allowing the model to continuously expand its knowledge without the need for full retraining.
Through extensive experiments on several benchmark datasets, the authors demonstrate the effectiveness of their approach in enabling weakly-supervised incremental learning for semantic segmentation, outperforming previous state-of-the-art methods.
Critical Analysis
The paper presents a compelling approach to overcoming the data annotation bottleneck in semantic segmentation by leveraging web-based language data. The authors have made several technical contributions to enable this weakly-supervised incremental learning framework, such as the Tendency-Driven Mutual Exclusivity mechanism and the Organizing Background techniques.
One potential limitation of the approach is its reliance on the availability and quality of the language data used to guide the incremental learning process. The performance of the model may be sensitive to the coverage and accuracy of the web-based language resources, which could vary across different domains and applications.
Additionally, the paper does not address potential biases or ethical considerations that may arise from using web-based language data, which could lead to undesirable biases or stereotypes being learned by the model. Further research may be needed to ensure the fairness and robustness of the approach.
While the experimental results are promising, the authors could have provided more insights into the limitations or failure cases of their method, as well as potential avenues for further improvement. Exploring the tradeoffs between the model's segmentation performance and the level of human supervision required would also be valuable for understanding the practical implications of the approach.
Conclusion
This paper presents a novel weakly-supervised incremental learning approach for semantic segmentation that leverages language information from the web to continuously expand the model's knowledge and segmentation capabilities. By combining vision and language, the proposed framework offers a promising direction for building more flexible and adaptable semantic segmentation models that can learn from diverse data sources.
The technical contributions, such as the Tendency-Driven Mutual Exclusivity mechanism and the Organizing Background techniques, demonstrate the potential of this approach and open up new avenues for further research in the field of continual learning and multi-modal learning. As the authors have shown, this line of work could have significant implications for reducing the data annotation burden and enabling more widespread adoption of semantic segmentation in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation
Chang Liu, Giulia Rizzoli, Pietro Zanuttigh, Fu Li, Yi Niu
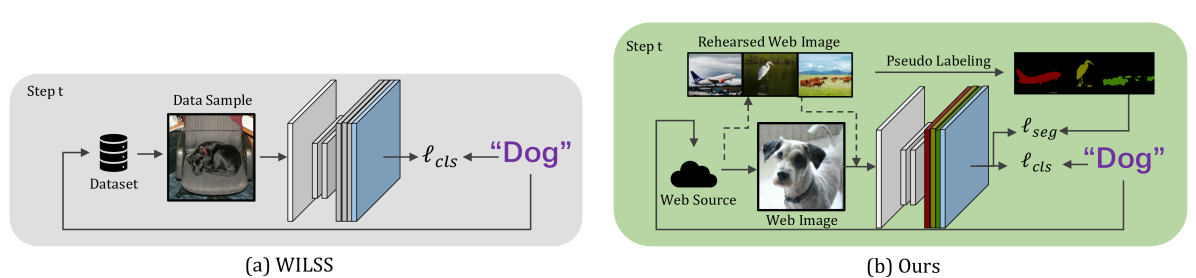
Current weakly-supervised incremental learning for semantic segmentation (WILSS) approaches only consider replacing pixel-level annotations with image-level labels, while the training images are still from well-designed datasets. In this work, we argue that widely available web images can also be considered for the learning of new classes. To achieve this, firstly we introduce a strategy to select web images which are similar to previously seen examples in the latent space using a Fourier-based domain discriminator. Then, an effective caption-driven reharsal strategy is proposed to preserve previously learnt classes. To our knowledge, this is the first work to rely solely on web images for both the learning of new concepts and the preservation of the already learned ones in WILSS. Experimental results show that the proposed approach can reach state-of-the-art performances without using manually selected and annotated data in the incremental steps.
Read more9/4/2024

0
Tendency-driven Mutual Exclusivity for Weakly Supervised Incremental Semantic Segmentation
Chongjie Si, Xuehui Wang, Xiaokang Yang, Wei Shen
Weakly Incremental Learning for Semantic Segmentation (WILSS) leverages a pre-trained segmentation model to segment new classes using cost-effective and readily available image-level labels. A prevailing way to solve WILSS is the generation of seed areas for each new class, serving as a form of pixel-level supervision. However, a scenario usually arises where a pixel is concurrently predicted as an old class by the pre-trained segmentation model and a new class by the seed areas. Such a scenario becomes particularly problematic in WILSS, as the lack of pixel-level annotations on new classes makes it intractable to ascertain whether the pixel pertains to the new class or not. To surmount this issue, we propose an innovative, tendency-driven relationship of mutual exclusivity, meticulously tailored to govern the behavior of the seed areas and the predictions generated by the pre-trained segmentation model. This relationship stipulates that predictions for the new and old classes must not conflict whilst prioritizing the preservation of predictions for the old classes, which not only addresses the conflicting prediction issue but also effectively mitigates the inherent challenge of incremental learning - catastrophic forgetting. Furthermore, under the auspices of this tendency-driven mutual exclusivity relationship, we generate pseudo masks for the new classes, allowing for concurrent execution with model parameter updating via the resolution of a bi-level optimization problem. Extensive experiments substantiate the effectiveness of our framework, resulting in the establishment of new benchmarks and paving the way for further research in this field.
Read more4/22/2024

0
Learning at a Glance: Towards Interpretable Data-limited Continual Semantic Segmentation via Semantic-Invariance Modelling
Bo Yuan, Danpei Zhao, Zhenwei Shi
Continual semantic segmentation (CSS) based on incremental learning (IL) is a great endeavour in developing human-like segmentation models. However, current CSS approaches encounter challenges in the trade-off between preserving old knowledge and learning new ones, where they still need large-scale annotated data for incremental training and lack interpretability. In this paper, we present Learning at a Glance (LAG), an efficient, robust, human-like and interpretable approach for CSS. Specifically, LAG is a simple and model-agnostic architecture, yet it achieves competitive CSS efficiency with limited incremental data. Inspired by human-like recognition patterns, we propose a semantic-invariance modelling approach via semantic features decoupling that simultaneously reconciles solid knowledge inheritance and new-term learning. Concretely, the proposed decoupling manner includes two ways, i.e., channel-wise decoupling and spatial-level neuron-relevant semantic consistency. Our approach preserves semantic-invariant knowledge as solid prototypes to alleviate catastrophic forgetting, while also constraining sample-specific contents through an asymmetric contrastive learning method to enhance model robustness during IL steps. Experimental results in multiple datasets validate the effectiveness of the proposed method. Furthermore, we introduce a novel CSS protocol that better reflects realistic data-limited CSS settings, and LAG achieves superior performance under multiple data-limited conditions.
Read more7/23/2024

0
Weakly-supervised Semantic Segmentation via Dual-stream Contrastive Learning of Cross-image Contextual Information
Qi Lai, Chi-Man Vong
Weakly supervised semantic segmentation (WSSS) aims at learning a semantic segmentation model with only image-level tags. Despite intensive research on deep learning approaches over a decade, there is still a significant performance gap between WSSS and full semantic segmentation. Most current WSSS methods always focus on a limited single image (pixel-wise) information while ignoring the valuable inter-image (semantic-wise) information. From this perspective, a novel end-to-end WSSS framework called DSCNet is developed along with two innovations: i) pixel-wise group contrast and semantic-wise graph contrast are proposed and introduced into the WSSS framework; ii) a novel dual-stream contrastive learning (DSCL) mechanism is designed to jointly handle pixel-wise and semantic-wise context information for better WSSS performance. Specifically, the pixel-wise group contrast learning (PGCL) and semantic-wise graph contrast learning (SGCL) tasks form a more comprehensive solution. Extensive experiments on PASCAL VOC and MS COCO benchmarks verify the superiority of DSCNet over SOTA approaches and baseline models.
Read more5/9/2024