Learning-Based Verification of Stochastic Dynamical Systems with Neural Network Policies
2406.00826
0
0
🧠
Abstract
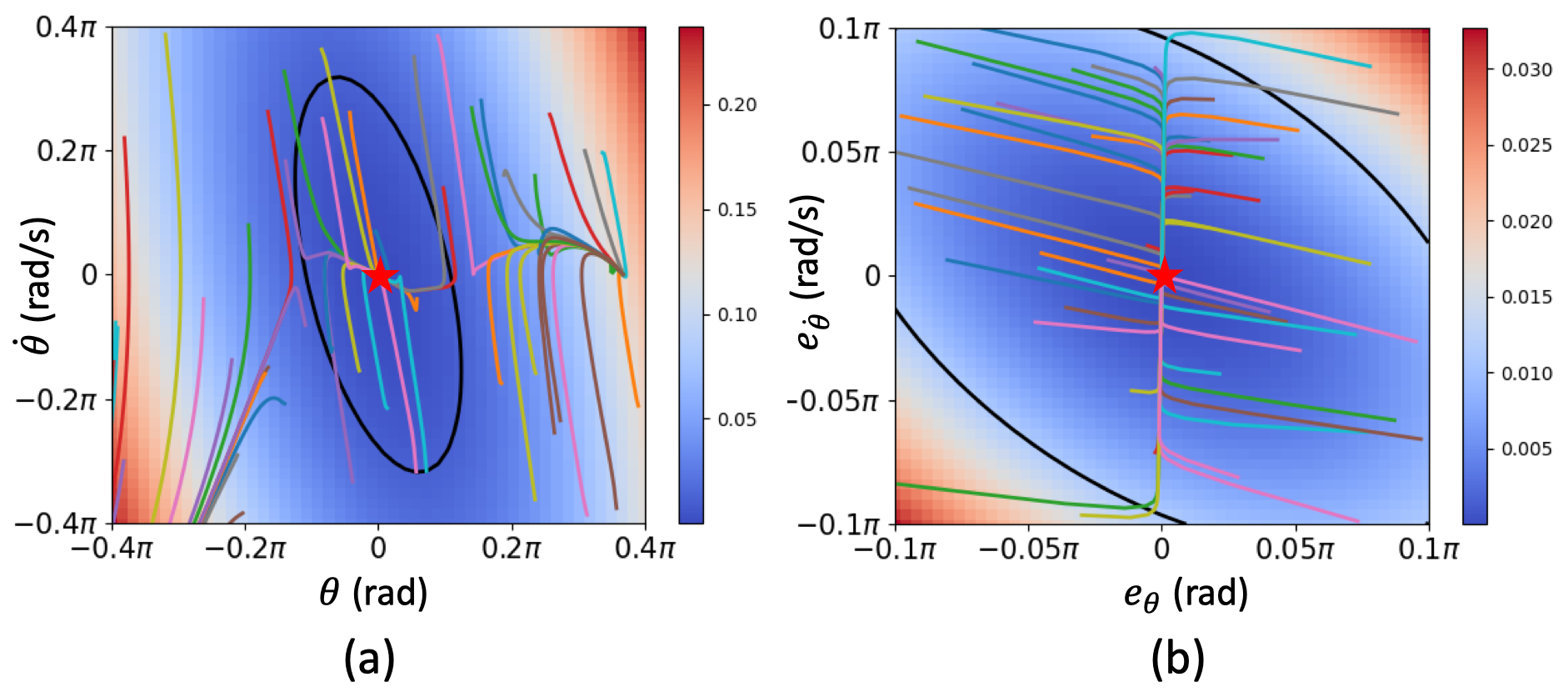
We consider the verification of neural network policies for reach-avoid control tasks in stochastic dynamical systems. We use a verification procedure that trains another neural network, which acts as a certificate proving that the policy satisfies the task. For reach-avoid tasks, it suffices to show that this certificate network is a reach-avoid supermartingale (RASM). As our main contribution, we significantly accelerate algorithmic approaches for verifying that a neural network is indeed a RASM. The main bottleneck of these approaches is the discretization of the state space of the dynamical system. The following two key contributions allow us to use a coarser discretization than existing approaches. First, we present a novel and fast method to compute tight upper bounds on Lipschitz constants of neural networks based on weighted norms. We further improve these bounds on Lipschitz constants based on the characteristics of the certificate network. Second, we integrate an efficient local refinement scheme that dynamically refines the state space discretization where necessary. Our empirical evaluation shows the effectiveness of our approach for verifying neural network policies in several benchmarks and trained with different reinforcement learning algorithms.
Create account to get full access
Overview
- This paper explores the verification of neural network policies for reach-avoid control tasks in stochastic dynamical systems.
- The researchers use a verification procedure that trains another neural network, which acts as a "certificate" proving that the policy satisfies the task.
- For reach-avoid tasks, the certificate network must be a "reach-avoid supermartingale" (RASM).
- The key contributions are methods to significantly accelerate the verification that a neural network is a RASM.
Plain English Explanation
The paper discusses a way to verify that a neural network-based control policy is "safe" for use in real-world systems. The goal is to ensure the policy can reliably perform a "reach-avoid" task, where the system must reach a desired state while avoiding unsafe regions.
To do this, the researchers train a separate neural network that acts as a "certificate" - it proves the original policy satisfies the reach-avoid requirements. This certificate network must have a special mathematical property called a "reach-avoid supermartingale" (RASM).
The main challenge is efficiently verifying that a neural network is a valid RASM. The researchers present two key innovations to speed up this verification process:
-
A new method to quickly compute tight upper bounds on the "Lipschitz constant" of a neural network. This constant describes how much the network's output can change for a given change in its input. Link to paper on Lyapunov-stable neural control
-
An efficient "local refinement" scheme that dynamically adjusts the discretization of the system's state space, focusing verification efforts where they are most needed. Link to paper on distributionally robust policy learning with Lyapunov certificates
By using these techniques, the researchers can more quickly verify that a neural network policy is "safe" for real-world deployment, an important step towards formally verifying deep reinforcement learning controllers and scalable verification of image-based neural networks.
Technical Explanation
The paper presents a verification procedure for neural network policies in stochastic dynamical systems. The key idea is to train a separate "certificate" neural network that proves the original policy satisfies a reach-avoid task. For this, the certificate network must be a reach-avoid supermartingale (RASM).
The main challenge is efficiently verifying that a neural network is a valid RASM. Existing approaches rely on discretizing the system's state space, which can become computationally expensive. The researchers address this in two ways:
-
They develop a novel method to compute tight upper bounds on the Lipschitz constants of neural networks. This is done using weighted norms and exploiting the specific structure of the certificate network.
-
They integrate an efficient local refinement scheme into the verification process. This dynamically adjusts the state space discretization, focusing computational effort where it is most needed.
The researchers evaluate their approach on several benchmark problems, with neural network policies trained using different reinforcement learning algorithms. The results show their techniques significantly accelerate the verification process compared to existing methods.
Critical Analysis
The paper presents a thorough and well-executed approach to verifying the safety of neural network control policies. The key innovations around Lipschitz constant estimation and dynamic state space discretization are technically sound and well-motivated.
That said, the paper does not explore the limitations of its approach in depth. For example, it is unclear how the method would scale to very high-dimensional systems or highly complex neural network architectures. The researchers also do not discuss potential failure modes of the verification process or how sensitive the results might be to hyperparameter choices.
Additionally, while the paper demonstrates the effectiveness of the approach on several benchmarks, more real-world validation would be needed to assess its practicality for industrial-scale applications. Link to paper on verified safe reinforcement learning with neural networks
Overall, this is a valuable contribution to the field of formal verification for reinforcement learning systems. However, further research is needed to better understand the limitations and robustness of the proposed techniques.
Conclusion
This paper presents a significant advancement in the verification of neural network control policies for reach-avoid tasks in stochastic dynamical systems. By introducing novel methods for computing tight Lipschitz constant bounds and dynamically refining the state space discretization, the researchers have demonstrated a substantial improvement in the efficiency of the verification process.
These techniques are an important step towards the broader goal of formally verifying deep reinforcement learning controllers and enabling the safe deployment of neural network-based control systems in real-world applications. The critical analysis highlights areas for future research to further strengthen the robustness and scalability of the approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Verified Safe Reinforcement Learning for Neural Network Dynamic Models
Junlin Wu, Huan Zhang, Yevgeniy Vorobeychik
0
0
Learning reliably safe autonomous control is one of the core problems in trustworthy autonomy. However, training a controller that can be formally verified to be safe remains a major challenge. We introduce a novel approach for learning verified safe control policies in nonlinear neural dynamical systems while maximizing overall performance. Our approach aims to achieve safety in the sense of finite-horizon reachability proofs, and is comprised of three key parts. The first is a novel curriculum learning scheme that iteratively increases the verified safe horizon. The second leverages the iterative nature of gradient-based learning to leverage incremental verification, reusing information from prior verification runs. Finally, we learn multiple verified initial-state-dependent controllers, an idea that is especially valuable for more complex domains where learning a single universal verified safe controller is extremely challenging. Our experiments on five safe control problems demonstrate that our trained controllers can achieve verified safety over horizons that are as much as an order of magnitude longer than state-of-the-art baselines, while maintaining high reward, as well as a perfect safety record over entire episodes.
5/28/2024
Lyapunov-stable Neural Control for State and Output Feedback: A Novel Formulation for Efficient Synthesis and Verification
Lujie Yang, Hongkai Dai, Zhouxing Shi, Cho-Jui Hsieh, Russ Tedrake, Huan Zhang
0
0
Learning-based neural network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers such as sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. Source code at https://github.com/Verified-Intelligence/Lyapunov_Stable_NN_Controllers
6/6/2024

Distributionally Robust Policy and Lyapunov-Certificate Learning
Kehan Long, Jorge Cortes, Nikolay Atanasov
0
0
This article presents novel methods for synthesizing distributionally robust stabilizing neural controllers and certificates for control systems under model uncertainty. A key challenge in designing controllers with stability guarantees for uncertain systems is the accurate determination of and adaptation to shifts in model parametric uncertainty during online deployment. We tackle this with a novel distributionally robust formulation of the Lyapunov derivative chance constraint ensuring a monotonic decrease of the Lyapunov certificate. To avoid the computational complexity involved in dealing with the space of probability measures, we identify a sufficient condition in the form of deterministic convex constraints that ensures the Lyapunov derivative constraint is satisfied. We integrate this condition into a loss function for training a neural network-based controller and show that, for the resulting closed-loop system, the global asymptotic stability of its equilibrium can be certified with high confidence, even with Out-of-Distribution (OoD) model uncertainties. To demonstrate the efficacy and efficiency of the proposed methodology, we compare it with an uncertainty-agnostic baseline approach and several reinforcement learning approaches in two control problems in simulation.
4/8/2024
Formally Verifying Deep Reinforcement Learning Controllers with Lyapunov Barrier Certificates
Udayan Mandal, Guy Amir, Haoze Wu, Ieva Daukantas, Fletcher Lee Newell, Umberto J. Ravaioli, Baoluo Meng, Michael Durling, Milan Ganai, Tobey Shim, Guy Katz, Clark Barrett
0
0
Deep reinforcement learning (DRL) is a powerful machine learning paradigm for generating agents that control autonomous systems. However, the black box nature of DRL agents limits their deployment in real-world safety-critical applications. A promising approach for providing strong guarantees on an agent's behavior is to use Neural Lyapunov Barrier (NLB) certificates, which are learned functions over the system whose properties indirectly imply that an agent behaves as desired. However, NLB-based certificates are typically difficult to learn and even more difficult to verify, especially for complex systems. In this work, we present a novel method for training and verifying NLB-based certificates for discrete-time systems. Specifically, we introduce a technique for certificate composition, which simplifies the verification of highly-complex systems by strategically designing a sequence of certificates. When jointly verified with neural network verification engines, these certificates provide a formal guarantee that a DRL agent both achieves its goals and avoids unsafe behavior. Furthermore, we introduce a technique for certificate filtering, which significantly simplifies the process of producing formally verified certificates. We demonstrate the merits of our approach with a case study on providing safety and liveness guarantees for a DRL-controlled spacecraft.
5/24/2024