Learning Differentially Private Diffusion Models via Stochastic Adversarial Distillation

0

Sign in to get full access
Overview
- Explores a novel approach to learning differentially private diffusion models through stochastic adversarial distillation
- Proposes a framework to train a differentially private diffusion model by distilling knowledge from a non-private teacher model
- Demonstrates the effectiveness of the approach on various datasets and provides insights into the trade-offs between privacy and utility
Plain English Explanation
This paper presents a way to create differentially private diffusion models, which are a type of generative model that can generate new data samples that resemble the training data. The key idea is to "distill" the knowledge from a non-private teacher diffusion model into a private student model, using a technique called adversarial distillation.
The process works by training the student model to mimic the behavior of the teacher model, while also maintaining differential privacy. This means that the student model can generate new samples that are similar to the training data, but with the added benefit of protecting the privacy of the original data.
The researchers demonstrate that this approach can effectively train differentially private diffusion models across various datasets, and they explore the trade-offs between the level of privacy and the quality of the generated samples as discussed in this related work.
Technical Explanation
The paper proposes a framework called Stochastic Adversarial Distillation (StAD) for learning differentially private diffusion models. The key components are:
- Teacher Diffusion Model: A non-private diffusion model trained on the original data, which serves as the "teacher" model.
- Student Diffusion Model: The differentially private diffusion model being trained, which aims to mimic the teacher model.
- Adversarial Distillation: The student model is trained to minimize the difference between its own samples and those of the teacher model, using an adversarial training approach as seen in this related work.
- Differential Privacy: The student model is trained with differential privacy constraints to ensure that the private training data cannot be inferred from the model's outputs.
The researchers evaluate their approach on various datasets and demonstrate that the StAD framework can effectively train differentially private diffusion models while maintaining high sample quality compared to the non-private teacher model.
Critical Analysis
The paper presents a promising approach to learning differentially private diffusion models, but it also acknowledges some limitations:
- The trade-off between privacy and utility: As the level of differential privacy increases, the quality of the generated samples from the student model may decrease. The researchers explore this trade-off but note that further research is needed to optimize the balance.
- The dependence on a non-private teacher model: The approach relies on having access to a high-quality, non-private teacher model, which may not always be available or feasible to train.
- The computational complexity: The adversarial training process used in the StAD framework can be computationally intensive, which may limit its scalability to larger datasets or more complex models.
Additionally, while the paper provides a thorough technical evaluation, it would be valuable to see more discussion on the potential real-world applications and societal implications of this technology, as well as any ethical considerations that may arise from deploying differentially private generative models.
Conclusion
This paper introduces a novel approach called Stochastic Adversarial Distillation (StAD) for learning differentially private diffusion models. The key idea is to distill the knowledge from a non-private teacher diffusion model into a private student model, using an adversarial training process while maintaining differential privacy constraints.
The researchers demonstrate the effectiveness of their approach on various datasets, showcasing the ability to train differentially private diffusion models that can generate high-quality samples while protecting the privacy of the original training data. This work advances the field of differentially private generative models and opens up new possibilities for applications that require both data utility and privacy preservation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Differentially Private Diffusion Models via Stochastic Adversarial Distillation
Bochao Liu, Pengju Wang, Shiming Ge
While the success of deep learning relies on large amounts of training datasets, data is often limited in privacy-sensitive domains. To address this challenge, generative model learning with differential privacy has emerged as a solution to train private generative models for desensitized data generation. However, the quality of the images generated by existing methods is limited due to the complexity of modeling data distribution. We build on the success of diffusion models and introduce DP-SAD, which trains a private diffusion model by a stochastic adversarial distillation method. Specifically, we first train a diffusion model as a teacher and then train a student by distillation, in which we achieve differential privacy by adding noise to the gradients from other models to the student. For better generation quality, we introduce a discriminator to distinguish whether an image is from the teacher or the student, which forms the adversarial training. Extensive experiments and analysis clearly demonstrate the effectiveness of our proposed method.
Read more8/28/2024
0
Differentially Private Fine-Tuning of Diffusion Models
Yu-Lin Tsai, Yizhe Li, Zekai Chen, Po-Yu Chen, Chia-Mu Yu, Xuebin Ren, Francois Buet-Golfouse
The integration of Differential Privacy (DP) with diffusion models (DMs) presents a promising yet challenging frontier, particularly due to the substantial memorization capabilities of DMs that pose significant privacy risks. Differential privacy offers a rigorous framework for safeguarding individual data points during model training, with Differential Privacy Stochastic Gradient Descent (DP-SGD) being a prominent implementation. Diffusion method decomposes image generation into iterative steps, theoretically aligning well with DP's incremental noise addition. Despite the natural fit, the unique architecture of DMs necessitates tailored approaches to effectively balance privacy-utility trade-off. Recent developments in this field have highlighted the potential for generating high-quality synthetic data by pre-training on public data (i.e., ImageNet) and fine-tuning on private data, however, there is a pronounced gap in research on optimizing the trade-offs involved in DP settings, particularly concerning parameter efficiency and model scalability. Our work addresses this by proposing a parameter-efficient fine-tuning strategy optimized for private diffusion models, which minimizes the number of trainable parameters to enhance the privacy-utility trade-off. We empirically demonstrate that our method achieves state-of-the-art performance in DP synthesis, significantly surpassing previous benchmarks on widely studied datasets (e.g., with only 0.47M trainable parameters, achieving a more than 35% improvement over the previous state-of-the-art with a small privacy budget on the CelebA-64 dataset). Anonymous codes available at https://anonymous.4open.science/r/DP-LORA-F02F.
Read more6/4/2024

0
Learning Privacy-Preserving Student Networks via Discriminative-Generative Distillation
Shiming Ge, Bochao Liu, Pengju Wang, Yong Li, Dan Zeng
While deep models have proved successful in learning rich knowledge from massive well-annotated data, they may pose a privacy leakage risk in practical deployment. It is necessary to find an effective trade-off between high utility and strong privacy. In this work, we propose a discriminative-generative distillation approach to learn privacy-preserving deep models. Our key idea is taking models as bridge to distill knowledge from private data and then transfer it to learn a student network via two streams. First, discriminative stream trains a baseline classifier on private data and an ensemble of teachers on multiple disjoint private subsets, respectively. Then, generative stream takes the classifier as a fixed discriminator and trains a generator in a data-free manner. After that, the generator is used to generate massive synthetic data which are further applied to train a variational autoencoder (VAE). Among these synthetic data, a few of them are fed into the teacher ensemble to query labels via differentially private aggregation, while most of them are embedded to the trained VAE for reconstructing synthetic data. Finally, a semi-supervised student learning is performed to simultaneously handle two tasks: knowledge transfer from the teachers with distillation on few privately labeled synthetic data, and knowledge enhancement with tangent-normal adversarial regularization on many triples of reconstructed synthetic data. In this way, our approach can control query cost over private data and mitigate accuracy degradation in a unified manner, leading to a privacy-preserving student model. Extensive experiments and analysis clearly show the effectiveness of the proposed approach.
Read more9/5/2024
🔮
0
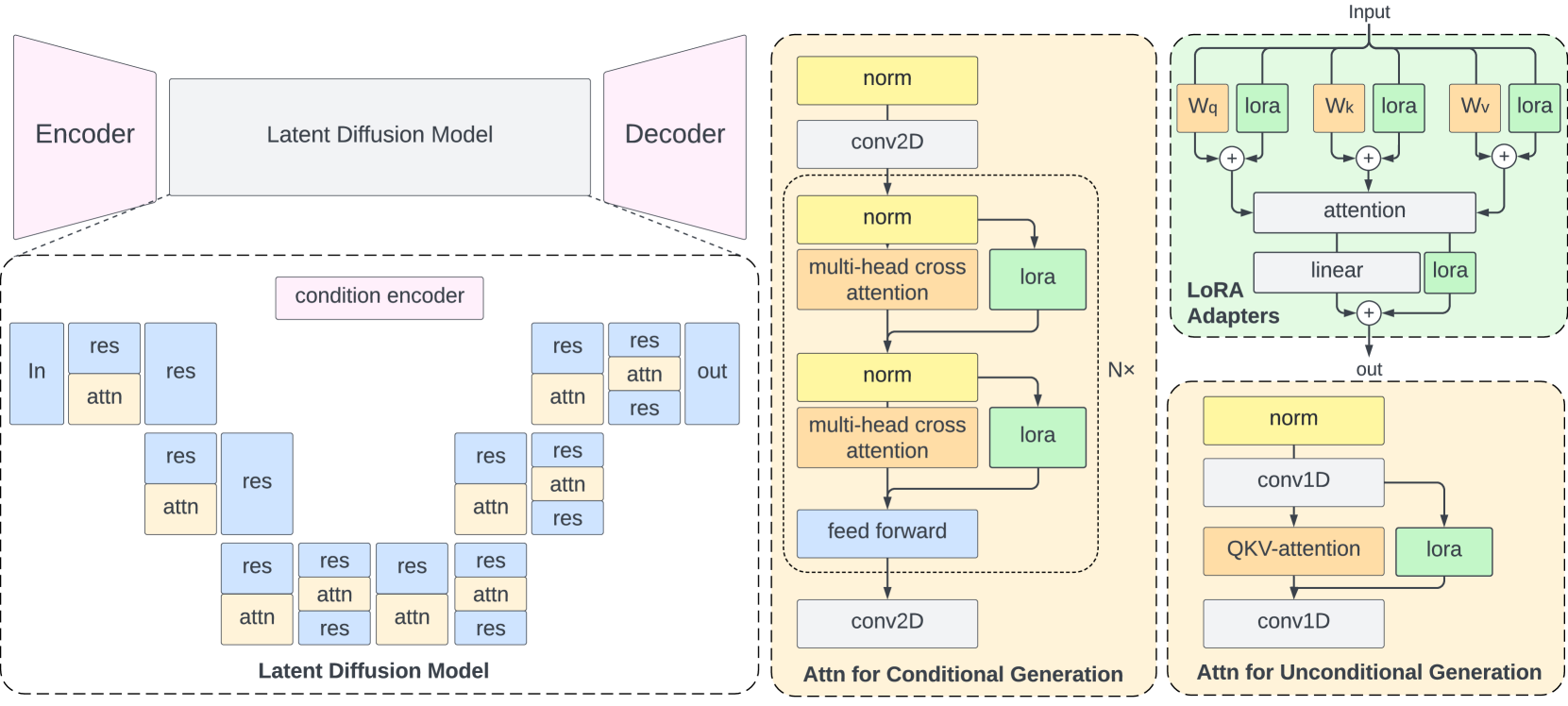
Differentially Private Latent Diffusion Models
Michael F. Liu, Saiyue Lyu, Margarita Vinaroz, Mijung Park
Diffusion models (DMs) are one of the most widely used generative models for producing high quality images. However, a flurry of recent papers points out that DMs are least private forms of image generators, by extracting a significant number of near-identical replicas of training images from DMs. Existing privacy-enhancing techniques for DMs, unfortunately, do not provide a good privacy-utility tradeoff. In this paper, we aim to improve the current state of DMs with differential privacy (DP) by adopting the textit{Latent} Diffusion Models (LDMs). LDMs are equipped with powerful pre-trained autoencoders that map the high-dimensional pixels into lower-dimensional latent representations, in which DMs are trained, yielding a more efficient and fast training of DMs. Rather than fine-tuning the entire LDMs, we fine-tune only the $textit{attention}$ modules of LDMs with DP-SGD, reducing the number of trainable parameters by roughly $90%$ and achieving a better privacy-accuracy trade-off. Our approach allows us to generate realistic, high-dimensional images (256x256) conditioned on text prompts with DP guarantees, which, to the best of our knowledge, has not been attempted before. Our approach provides a promising direction for training more powerful, yet training-efficient differentially private DMs, producing high-quality DP images. Our code is available at https://anonymous.4open.science/r/DP-LDM-4525.
Read more7/22/2024