Learning Privacy-Preserving Student Networks via Discriminative-Generative Distillation

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Discriminative-Generative Distillation" for learning privacy-preserving student networks.
- The method combines discriminative and generative training to distill knowledge from a complex teacher model into a simpler student model while preserving privacy.
- Experiments demonstrate the effectiveness of this approach in achieving high accuracy while satisfying strong differential privacy guarantees.
Plain English Explanation
The paper introduces a new way to train smaller, simpler machine learning models from more complex "teacher" models, while also preserving the privacy of the training data.
The key idea is to use a combination of discriminative and generative training techniques to distill the knowledge from the teacher model into the student model. This allows the student model to learn the important patterns and insights from the teacher, while also satisfying strict differential privacy requirements that protect the privacy of the original training data.
The researchers demonstrate that this "Discriminative-Generative Distillation" approach can achieve high accuracy on various tasks, while also providing strong privacy guarantees - a valuable capability for applications where both model performance and data privacy are critical.
Technical Explanation
The paper proposes a novel "Discriminative-Generative Distillation" (DGD) framework for training privacy-preserving student networks. The key aspects of the technical approach are:
-
Discriminative Training: The student network is trained using a discriminative loss function to mimic the output predictions of the teacher network. This allows the student to learn the important decision boundaries and classification patterns from the teacher.
-
Generative Training: In parallel, the student network is also trained using a generative adversarial network (GAN) loss. This encourages the student to generate synthetic data samples that are statistically similar to the original training data, without directly accessing the raw data.
-
Differentially Private Training: Both the discriminative and generative training of the student network are performed under strict differential privacy constraints. This ensures that the student model does not leak any sensitive information about the original training data.
The paper conducts extensive experiments on various benchmark datasets and tasks, demonstrating that the DGD approach can achieve high accuracy for the student model while satisfying strong differential privacy guarantees. This highlights the effectiveness of combining discriminative and generative distillation techniques for learning privacy-preserving student networks.
Critical Analysis
One potential limitation of the DGD approach is the complexity involved in training the student network using both discriminative and generative objectives simultaneously. The authors note that this can be computationally intensive and may require careful hyperparameter tuning.
Additionally, the paper does not explore the performance of the DGD approach on more complex or high-dimensional datasets, such as large-scale image or natural language processing tasks. Further research may be needed to understand the scalability and generalization of the method to a wider range of applications.
While the paper provides strong empirical evidence for the privacy-preserving capabilities of the DGD approach, it would be valuable to conduct a more thorough analysis of the privacy-utility tradeoffs and potential vulnerabilities of the method. This could help researchers and practitioners better understand the practical limitations and appropriate use cases for this technology.
Conclusion
The "Discriminative-Generative Distillation" (DGD) framework presented in this paper offers a promising approach for learning privacy-preserving student networks from complex teacher models. By combining discriminative and generative training techniques, the method can effectively distill knowledge while satisfying strong differential privacy guarantees.
The authors demonstrate the effectiveness of this approach on various benchmark tasks, highlighting its potential for applications where both model performance and data privacy are crucial. While the method has some limitations, this research contributes valuable insights to the ongoing efforts in developing privacy-preserving machine learning solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Privacy-Preserving Student Networks via Discriminative-Generative Distillation
Shiming Ge, Bochao Liu, Pengju Wang, Yong Li, Dan Zeng
While deep models have proved successful in learning rich knowledge from massive well-annotated data, they may pose a privacy leakage risk in practical deployment. It is necessary to find an effective trade-off between high utility and strong privacy. In this work, we propose a discriminative-generative distillation approach to learn privacy-preserving deep models. Our key idea is taking models as bridge to distill knowledge from private data and then transfer it to learn a student network via two streams. First, discriminative stream trains a baseline classifier on private data and an ensemble of teachers on multiple disjoint private subsets, respectively. Then, generative stream takes the classifier as a fixed discriminator and trains a generator in a data-free manner. After that, the generator is used to generate massive synthetic data which are further applied to train a variational autoencoder (VAE). Among these synthetic data, a few of them are fed into the teacher ensemble to query labels via differentially private aggregation, while most of them are embedded to the trained VAE for reconstructing synthetic data. Finally, a semi-supervised student learning is performed to simultaneously handle two tasks: knowledge transfer from the teachers with distillation on few privately labeled synthetic data, and knowledge enhancement with tangent-normal adversarial regularization on many triples of reconstructed synthetic data. In this way, our approach can control query cost over private data and mitigate accuracy degradation in a unified manner, leading to a privacy-preserving student model. Extensive experiments and analysis clearly show the effectiveness of the proposed approach.
Read more9/5/2024

0
Learning Differentially Private Diffusion Models via Stochastic Adversarial Distillation
Bochao Liu, Pengju Wang, Shiming Ge
While the success of deep learning relies on large amounts of training datasets, data is often limited in privacy-sensitive domains. To address this challenge, generative model learning with differential privacy has emerged as a solution to train private generative models for desensitized data generation. However, the quality of the images generated by existing methods is limited due to the complexity of modeling data distribution. We build on the success of diffusion models and introduce DP-SAD, which trains a private diffusion model by a stochastic adversarial distillation method. Specifically, we first train a diffusion model as a teacher and then train a student by distillation, in which we achieve differential privacy by adding noise to the gradients from other models to the student. For better generation quality, we introduce a discriminator to distinguish whether an image is from the teacher or the student, which forms the adversarial training. Extensive experiments and analysis clearly demonstrate the effectiveness of our proposed method.
Read more8/28/2024
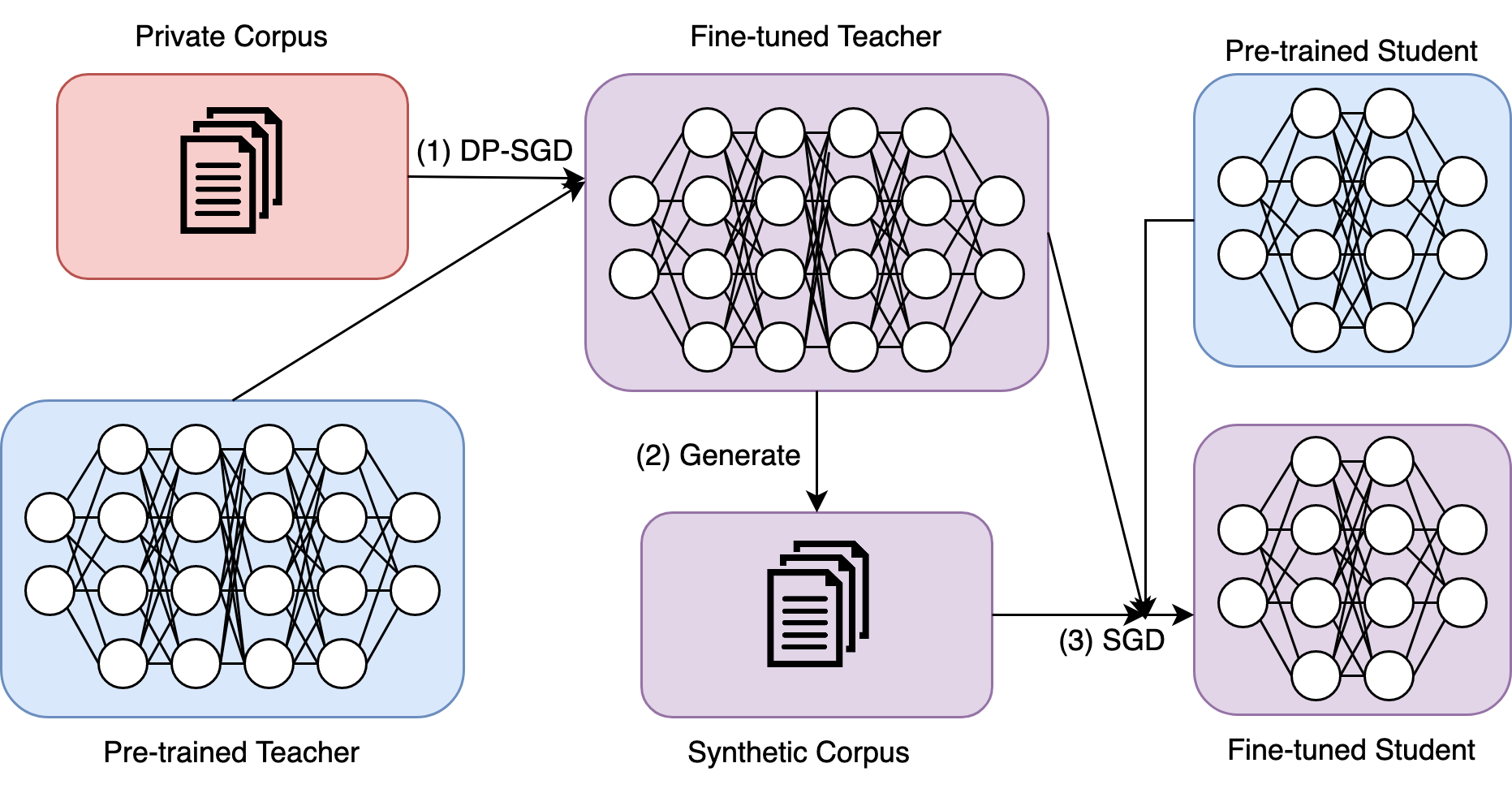
0
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
Read more6/6/2024
🐍
0
Robust and Resource-Efficient Data-Free Knowledge Distillation by Generative Pseudo Replay
Kuluhan Binici, Shivam Aggarwal, Nam Trung Pham, Karianto Leman, Tulika Mitra
Data-Free Knowledge Distillation (KD) allows knowledge transfer from a trained neural network (teacher) to a more compact one (student) in the absence of original training data. Existing works use a validation set to monitor the accuracy of the student over real data and report the highest performance throughout the entire process. However, validation data may not be available at distillation time either, making it infeasible to record the student snapshot that achieved the peak accuracy. Therefore, a practical data-free KD method should be robust and ideally provide monotonically increasing student accuracy during distillation. This is challenging because the student experiences knowledge degradation due to the distribution shift of the synthetic data. A straightforward approach to overcome this issue is to store and rehearse the generated samples periodically, which increases the memory footprint and creates privacy concerns. We propose to model the distribution of the previously observed synthetic samples with a generative network. In particular, we design a Variational Autoencoder (VAE) with a training objective that is customized to learn the synthetic data representations optimally. The student is rehearsed by the generative pseudo replay technique, with samples produced by the VAE. Hence knowledge degradation can be prevented without storing any samples. Experiments on image classification benchmarks show that our method optimizes the expected value of the distilled model accuracy while eliminating the large memory overhead incurred by the sample-storing methods.
Read more7/30/2024