Learning a Distributed Hierarchical Locomotion Controller for Embodied Cooperation

0

Sign in to get full access
Overview
- This paper presents a distributed hierarchical locomotion controller that enables cooperation between embodied agents.
- The approach combines high-level decision making with low-level motor control, allowing for coordinated and adaptive locomotion.
- The authors demonstrate the effectiveness of their method through experiments involving multi-agent scenarios and comparisons to baseline approaches.
Plain English Explanation
This research focuses on developing a control system that allows multiple robotic or virtual agents to work together and move around effectively. The key idea is to have a hierarchical structure, where there is a high-level decision-making component that coordinates the overall behavior, and a lower-level component that handles the details of how each agent moves its body.
The high-level part decides what actions the agents should take, such as where to move and how to coordinate with each other. The low-level part then figures out the specific motor commands needed to execute those actions, taking into account each agent's physical capabilities and constraints.
By separating the decision-making and physical control, this approach allows the agents to engage in cooperative behaviors, like moving in formation or helping each other accomplish tasks. The authors test their method in simulation, showing that the agents can coordinate their movements effectively compared to simpler controllers.
Technical Explanation
The paper introduces a distributed hierarchical locomotion controller for embodied cooperation. The core innovation is a two-level architecture that decouples high-level decision-making from low-level motor control.
At the higher level, a "hierarchical world model" reasons about the agents' goals and coordinated actions. This module uses reinforcement learning to learn policies that optimize for cooperative behavior.
The lower level "composite distributed learning" module handles the details of locomotion for each individual agent. It learns to generate motor commands that execute the higher-level decisions while respecting the agents' physical constraints.
The authors evaluate their approach in a multi-agent scenario where the agents must navigate and cooperate to achieve a shared objective. They compare their method to baseline controllers and demonstrate its advantages in terms of coordination, adaptability, and task performance.
Critical Analysis
The paper makes a compelling case for the benefits of a hierarchical control architecture for embodied cooperation. By separating high-level decision-making from low-level motor control, the approach enables more flexible and adaptive behaviors compared to monolithic controllers.
However, the authors acknowledge some limitations in their current implementation. For example, the learning process may be computationally intensive, and the agents' perception of their environment and teammates could be improved.
Additionally, the experiments were conducted in simulation, so further research would be needed to validate the approach's effectiveness in real-world robotic systems. Factors like sensor noise, communication delays, and physical constraints could introduce additional challenges.
Overall, this work represents a promising step towards more intelligent and cooperative embodied agents. The hierarchical design offers a flexible and scalable framework that could be extended to a wide range of multi-agent applications.
Conclusion
This paper presents a novel approach to controlling the locomotion of embodied agents in a cooperative setting. By separating high-level decision-making from low-level motor control, the authors have developed a hierarchical system that allows for coordinated and adaptive behaviors.
The key contributions of this work include the distributed hierarchical architecture, the use of reinforcement learning to optimize cooperative policies, and the demonstration of the approach's effectiveness in multi-agent scenarios.
While the current implementation has some limitations, this research represents an important step forward in the field of embodied cooperation. The ability for agents to work together seamlessly has numerous applications, from search and rescue operations to assistive robotics. Further advancements in this area could lead to significant breakthroughs in how we design and deploy intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning a Distributed Hierarchical Locomotion Controller for Embodied Cooperation
Chuye Hong, Kangyao Huang, Huaping Liu
In this work, we propose a distributed hierarchical locomotion control strategy for whole-body cooperation and demonstrate the potential for migration into large numbers of agents. Our method utilizes a hierarchical structure to break down complex tasks into smaller, manageable sub-tasks. By incorporating spatiotemporal continuity features, we establish the sequential logic necessary for causal inference and cooperative behaviour in sequential tasks, thereby facilitating efficient and coordinated control strategies. Through training within this framework, we demonstrate enhanced adaptability and cooperation, leading to superior performance in task completion compared to the original methods. Moreover, we construct a set of environments as the benchmark for embodied cooperation.
Read more7/10/2024

0
CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jiawei Gao, Ziqin Wang, Zeqi Xiao, Jingbo Wang, Tai Wang, Jinkun Cao, Xiaolin Hu, Si Liu, Jifeng Dai, Jiangmiao Pang
Recent years have seen significant advancements in humanoid control, largely due to the availability of large-scale motion capture data and the application of reinforcement learning methodologies. However, many real-world tasks, such as moving large and heavy furniture, require multi-character collaboration. Given the scarcity of data on multi-character collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce Cooperative Human-Object Interaction (CooHOI), a novel framework that addresses multi-character objects transporting through a two-phase learning paradigm: individual skill acquisition and subsequent transfer. Initially, a single agent learns to perform tasks using the Adversarial Motion Priors (AMP) framework. Following this, the agent learns to collaborate with others by considering the shared dynamics of the manipulated object during parallel training using Multi Agent Proximal Policy Optimization (MAPPO). When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-character HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-character interactions, and can be seamlessly extended to include more participants and a wide range of object types
Read more6/21/2024
0
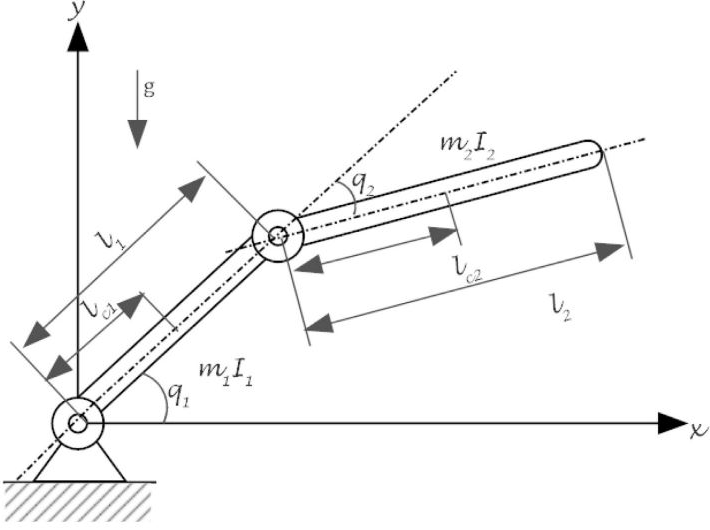
Composite Distributed Learning and Synchronization of Nonlinear Multi-Agent Systems with Complete Uncertain Dynamics
Emadodin Jandaghi, Dalton L. Stein, Adam Hoburg, Paolo Stegagno, Mingxi Zhou, Chengzhi Yuan
This paper addresses the problem of composite synchronization and learning control in a network of multi-agent robotic manipulator systems with heterogeneous nonlinear uncertainties under a leader-follower framework. A novel two-layer distributed adaptive learning control strategy is introduced, comprising a first-layer distributed cooperative estimator and a second-layer decentralized deterministic learning controller. The first layer is to facilitate each robotic agent's estimation of the leader's information. The second layer is responsible for both controlling individual robot agents to track desired reference trajectories and accurately identifying/learning their nonlinear uncertain dynamics. The proposed distributed learning control scheme represents an advancement in the existing literature due to its ability to manage robotic agents with completely uncertain dynamics including uncertain mass matrices. This allows the robotic control to be environment-independent which can be used in various settings, from underwater to space where identifying system dynamics parameters is challenging. The stability and parameter convergence of the closed-loop system are rigorously analyzed using the Lyapunov method. Numerical simulations validate the effectiveness of the proposed scheme.
Read more5/10/2024
0
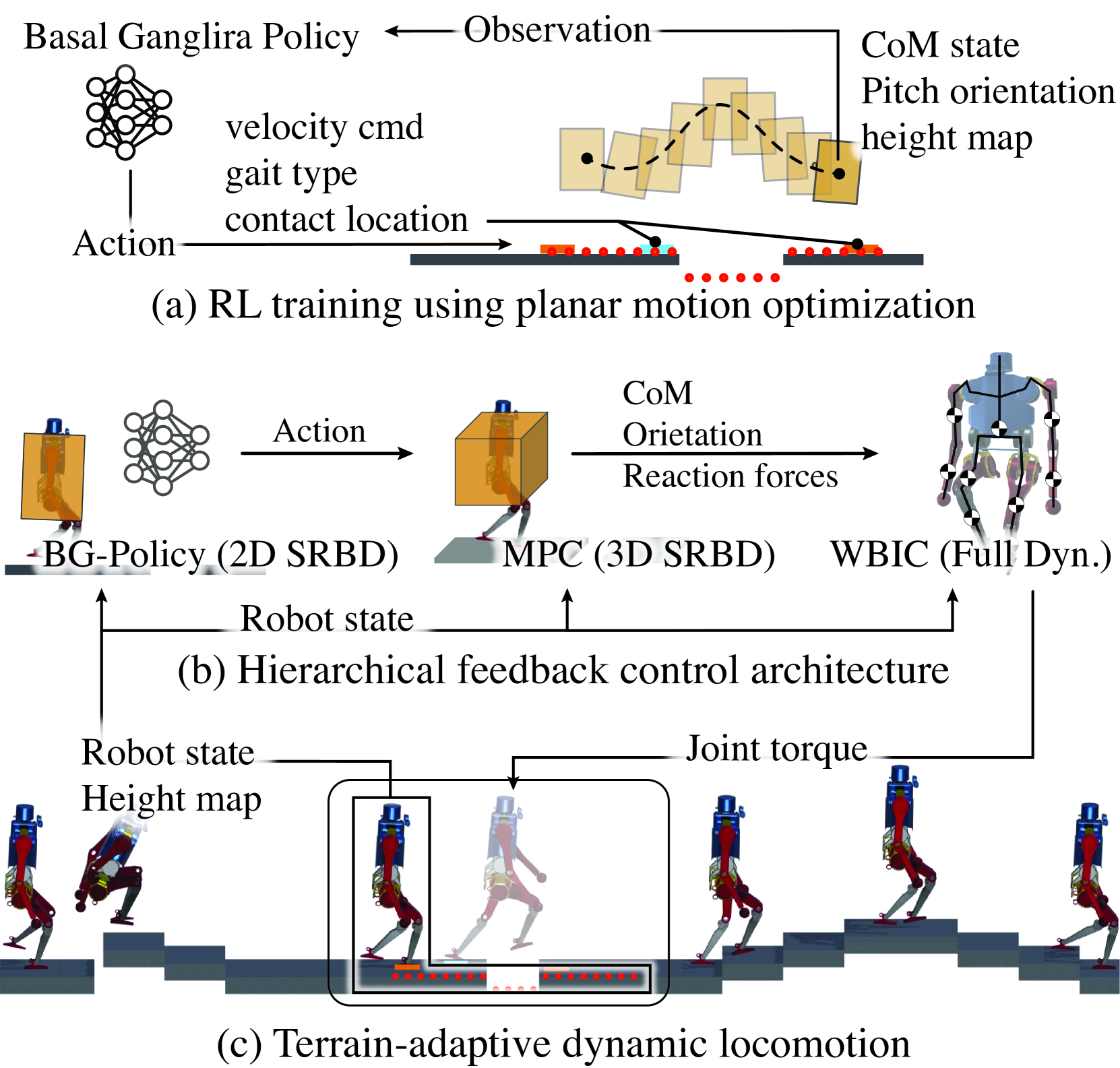
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Read more7/30/2024