Aggregating Local and Global Features via Selective State Spaces Model for Efficient Image Deblurring

0

Sign in to get full access
Introduction
The provided text discusses the challenge of image deblurring, which aims to recover a sharp image from a blurry one. Conventional approaches have explicitly incorporated various priors or hand-crafted features to constrain the solution space, but designing such priors is challenging and lacks generalizability.
Deep learning-based methods, such as encoder-decoder architectures, multi-stage networks, dual networks, and generative models, have been developed as a more data-driven approach. However, the convolution operation in these models has limitations in capturing long-range dependencies.
To address these limitations, transformer-based models have been applied to image deblurring, as they can better model non-local information. However, the attention mechanism in transformers incurs high computational costs, especially for high-resolution images. Some methods have tried to alleviate this by applying self-attention across channels instead of spatial dimensions or using non-overlapping window-based self-attention, but these approaches still struggle to fully exploit the spatial information.
The paper proposes a new network called ALGNet for image deblurring. Structured state space models like Mamba can efficiently capture long-range dependencies, but they tend to neglect local pixel information and have issues with channel redundancy. To address these limitations, ALGNet has several key components:
-
An efficient global block that uses selective structured state spaces to capture long-range dependency information important for high-quality deblurring.
-
A local block that models local connectivity using simplified channel attention, addressing the problems of local pixel forgetting and channel redundancy in the state space equation.
-
An aggregate method that emphasizes the importance of the local block by recalibrating the weights when combining the global and local components.
-
Multiple scales of input and output to help with training.
The paper claims that ALGNet achieves state-of-the-art performance on image deblurring while being computationally efficient compared to existing methods.
Related Work
The provided text discusses various approaches to image deblurring, a challenging problem due to its ill-posed nature.
The first section covers hand-crafted prior-based methods, which rely on manually designed image priors to constrain the set of plausible solutions. However, designing such priors is a challenging task that often leads to complicated optimization problems.
The second section discusses CNN-based methods, which use deep neural networks to learn image priors instead of manually designing them. These methods have shown better performance than the hand-crafted prior-based approaches. However, the local receptive fields of convolutional operations limit the models' ability to efficiently eliminate long-range degradation.
The third section covers Transformer-based methods, which leverage the global receptive field of the Transformer architecture to achieve superior performance compared to CNN-based baselines. However, the quadratic time complexity of the attention mechanism in Transformers results in significant computational overhead, especially for high-resolution images.
To address the limitations of both CNN-based and Transformer-based methods, the text introduces state space models as an efficient framework for capturing long-range dependencies with linear complexity. Various state space model approaches, such as S4, S5, Mega, SGConv, and LongConv, are discussed.
The work presented in this paper leverages a selective structured state space model to capture long-range dependency information, while also addressing issues of local pixel forgetting and channel redundancy.
Method
The proposed ALGNet pipeline first outlines the overall framework. It then describes the details of the ALGBlock, which includes a global block, a local block, and a features aggregation (FA) component. The global block and local block are key parts of the ALGBlock design.

The overall pipeline of the proposed ALGNet adopts a single U-shaped architecture for image restoration. The pipeline initially applies a convolution to acquire shallow features, which then undergo a four-scale encoder sub-network. The low-resolution degraded images are incorporated into the main path through concatenation. The resulting deepest features feed into a four-scale decoder, gradually restoring features to the original size. Finally, the network refines features to generate a residual image, which is added to the degraded image to obtain the restored image.
The network is optimized using a loss function that combines character, edge, and frequency domain losses. The character loss is a Charbonnier loss, the edge loss measures the Laplacian difference, and the frequency domain loss measures the difference in the Fourier transform.
To capture long-range dependencies efficiently, the network includes a global block with linear complexity, which expands and aggregates features through parallel branches. Additionally, a local block is designed to model local connectivity and facilitate the expressive power of different channels.
Finally, a features aggregation module is introduced to emphasize the importance of the local block by recalibrating the weights when aggregating the global and local features for restoration.
V Experiments
The paper describes the experimental details and results of the proposed ALGNet method for image deblurring tasks.
The key points are:
-
Datasets: The authors train ALGNet on the GoPro dataset for image motion deblurring, and evaluate it on the HIDE and RealBlur datasets as well. For single-image defocus deblurring, they use the DPDD dataset.
-
Training details: ALGNet is trained using the Adam optimizer with a gradually decreasing learning rate. Data augmentation techniques like flips are used.
-
Image motion deblurring results: On the GoPro dataset, ALGNet-B outperforms state-of-the-art methods like NAFNet-64 by 0.43 dB in PSNR. Even though trained only on GoPro, ALGNet achieves a 0.19 dB gain over Restormer-Local on the HIDE dataset, demonstrating good generalization. ALGNet also performs best on the real-world RealBlur dataset.
-
Single-image defocus deblurring results: ALGNet outperforms leading methods on the DPDD dataset across various metrics, especially in outdoor scenes where it has a 0.15 dB PSNR improvement over IRNeXt.
-
Ablation studies validate the effectiveness of ALGNet's global block, local block, and feature attention (FA) components, which together lead to significant performance gains.
-
Efficiency analysis shows ALGNet achieves state-of-the-art deblurring performance with up to 84.7% reduction in computational cost and 1.5x faster inference compared to prior methods.
Conclusion
The paper proposes an efficient image deblurring network that uses a selective structured state spaces model to aggregate enriched and accurate features. The key component is the Aggregate Local and Global Block (ALGBlock), which consists of global and local components. The global block uses the selective structured state spaces model to capture long-range dependency information. The local block models local connectivity using simplified channel attention, addressing issues of local pixel forgetting and channel redundancy in the state space equation. The paper also presents an aggregate method that emphasizes the importance of the local block in restoration. Experimental results show the proposed method outperforms state-of-the-art approaches on widely used benchmarks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aggregating Local and Global Features via Selective State Spaces Model for Efficient Image Deblurring
Hu Gao, Depeng Dang
Image deblurring aims to restore a high-quality image from its corresponding blurred. The emergence of CNNs and Transformers has enabled significant progress. However, these methods often face the dilemma between eliminating long-range degradation perturbations and maintaining computational efficiency. While the selective state space model (SSM) shows promise in modeling long-range dependencies with linear complexity, it also encounters challenges such as local pixel forgetting and channel redundancy. To address this issue, we propose an efficient image deblurring network that leverages selective state spaces model to aggregate enriched and accurate features. Specifically, we introduce an aggregate local and global information block (ALGBlock) designed to effectively capture and integrate both local invariant properties and non-local information. The ALGBlock comprises two primary modules: a module for capturing local and global features (CLGF), and a feature aggregation module (FA). The CLGF module is composed of two branches: the global branch captures long-range dependency features via a selective state spaces model, while the local branch employs simplified channel attention to model local connectivity, thereby reducing local pixel forgetting and channel redundancy. In addition, we design a FA module to accentuate the local part by recalibrating the weight during the aggregation of the two branches for restoration. Experimental results demonstrate that the proposed method outperforms state-of-the-art approaches on widely used benchmarks.
Read more4/8/2024
0
Multi-Scale Representation Learning for Image Restoration with State-Space Model
Yuhong He, Long Peng, Qiaosi Yi, Chen Wu, Lu Wang
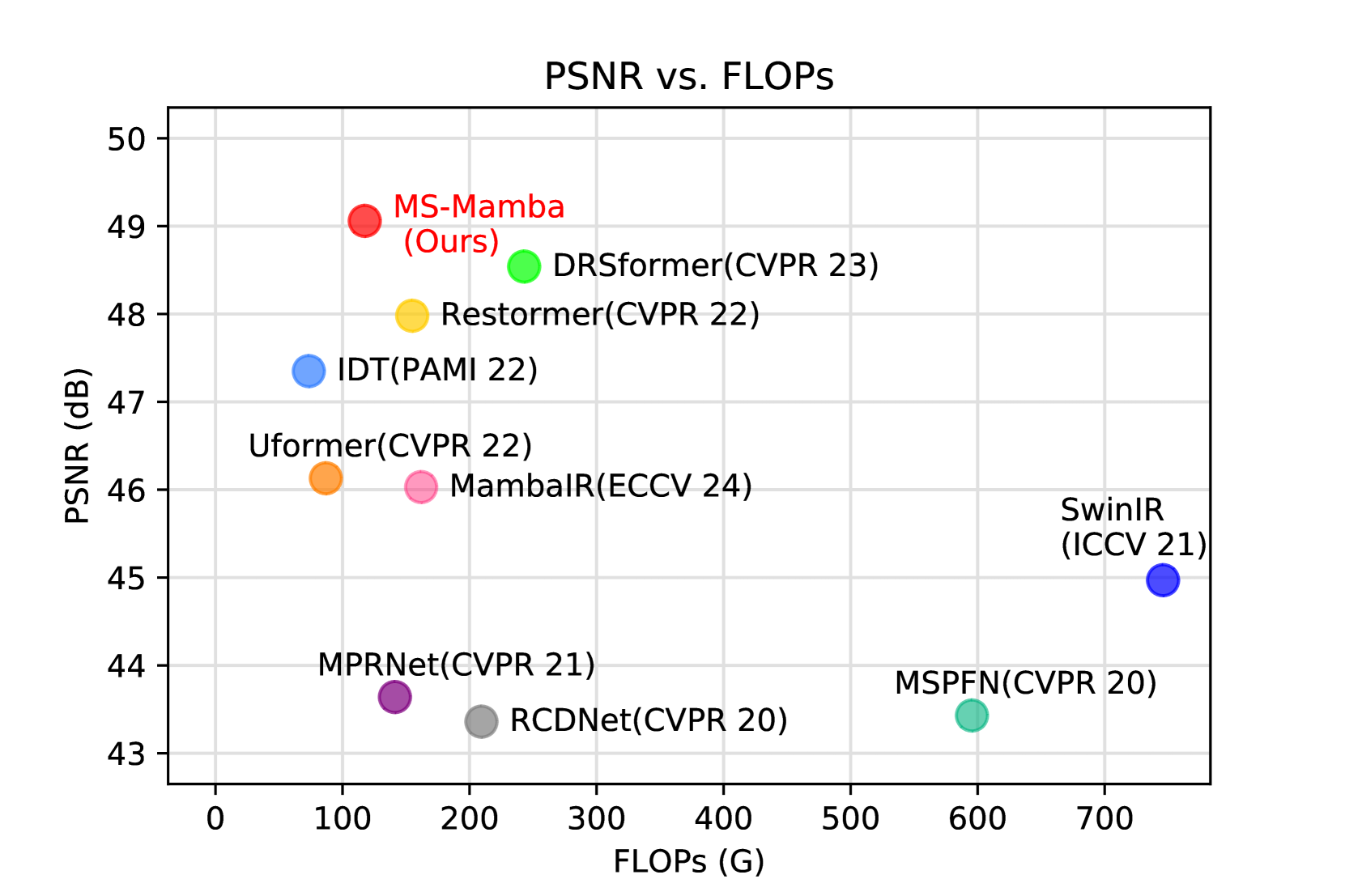
Image restoration endeavors to reconstruct a high-quality, detail-rich image from a degraded counterpart, which is a pivotal process in photography and various computer vision systems. In real-world scenarios, different types of degradation can cause the loss of image details at various scales and degrade image contrast. Existing methods predominantly rely on CNN and Transformer to capture multi-scale representations. However, these methods are often limited by the high computational complexity of Transformers and the constrained receptive field of CNN, which hinder them from achieving superior performance and efficiency in image restoration. To address these challenges, we propose a novel Multi-Scale State-Space Model-based (MS-Mamba) for efficient image restoration that enhances the capacity for multi-scale representation learning through our proposed global and regional SSM modules. Additionally, an Adaptive Gradient Block (AGB) and a Residual Fourier Block (RFB) are proposed to improve the network's detail extraction capabilities by capturing gradients in various directions and facilitating learning details in the frequency domain. Extensive experiments on nine public benchmarks across four classic image restoration tasks, image deraining, dehazing, denoising, and low-light enhancement, demonstrate that our proposed method achieves new state-of-the-art performance while maintaining low computational complexity. The source code will be publicly available.
Read more8/20/2024
📈
0
Efficient Visual State Space Model for Image Deblurring
Lingshun Kong, Jiangxin Dong, Ming-Hsuan Yang, Jinshan Pan
Convolutional neural networks (CNNs) and Vision Transformers (ViTs) have achieved excellent performance in image restoration. ViTs typically yield superior results in image restoration compared to CNNs due to their ability to capture long-range dependencies and input-dependent characteristics. However, the computational complexity of Transformer-based models grows quadratically with the image resolution, limiting their practical appeal in high-resolution image restoration tasks. In this paper, we propose a simple yet effective visual state space model (EVSSM) for image deblurring, leveraging the benefits of state space models (SSMs) to visual data. In contrast to existing methods that employ several fixed-direction scanning for feature extraction, which significantly increases the computational cost, we develop an efficient visual scan block that applies various geometric transformations before each SSM-based module, capturing useful non-local information and maintaining high efficiency. Extensive experimental results show that the proposed EVSSM performs favorably against state-of-the-art image deblurring methods on benchmark datasets and real-captured images.
Read more5/24/2024
🖼️
0
Image Super-resolution Reconstruction Network based on Enhanced Swin Transformer via Alternating Aggregation of Local-Global Features
Yuming Huang, Yingpin Chen, Changhui Wu, Hanrong Xie, Binhui Song, Hui Wang
The Swin Transformer image super-resolution reconstruction network only relies on the long-range relationship of window attention and shifted window attention to explore features. This mechanism has two limitations. On the one hand, it only focuses on global features while ignoring local features. On the other hand, it is only concerned with spatial feature interactions while ignoring channel features and channel interactions, thus limiting its non-linear mapping ability. To address the above limitations, this paper proposes enhanced Swin Transformer modules via alternating aggregation of local-global features. In the local feature aggregation stage, we introduce a shift convolution to realize the interaction between local spatial information and channel information. Then, a block sparse global perception module is introduced in the global feature aggregation stage. In this module, we reorganize the spatial information first, then send the recombination information into a dense layer to implement the global perception. After that, a multi-scale self-attention module and a low-parameter residual channel attention module are introduced to realize information aggregation at different scales. Finally, the proposed network is validated on five publicly available datasets. The experimental results show that the proposed network outperforms the other state-of-the-art super-resolution networks.
Read more4/9/2024