Learning from Partial Label Proportions for Whole Slide Image Segmentation

0
Sign in to get full access
Overview
- Proposes a weakly-supervised learning approach for whole slide image segmentation using partial label proportions
- Aims to address the challenge of obtaining fully labeled training data for medical image segmentation tasks
- Explores leveraging partial label information, where the proportion of each class in an image is known but not the exact pixel-level labels
Plain English Explanation
In medical image analysis, segmenting whole slide images (WSIs) into different tissue regions is an important task. However, obtaining fully labeled training data for this can be challenging and time-consuming. This paper explores a new approach that uses partial label proportions instead of full pixel-level labels.
The idea is that rather than needing to painstakingly label every pixel in an image, you only need to know the approximate proportion of each tissue type present. For example, you might know that an image contains roughly 40% tumor, 30% normal tissue, and 30% stroma, without needing to delineate the exact boundaries.
The researchers develop a weakly-supervised learning approach that can leverage this partial label information to train a segmentation model. This allows them to train on a larger and more diverse dataset compared to fully-supervised methods, which could lead to improved performance.
The key innovation is a novel loss function that encourages the model to output segmentation maps whose class proportions match the provided partial labels. This helps the model learn the correct tissue boundaries without needing pixel-perfect annotations.
Technical Explanation
The paper proposes a weakly-supervised learning approach for whole slide image segmentation that only requires partial label proportions during training, rather than full pixel-level annotations.
The authors develop a deep learning architecture consisting of an encoder-decoder network with a percentage matching loss. The encoder extracts features from the input WSI, and the decoder produces a segmentation map.
The key innovation is the percentage matching loss, which compares the class proportions in the predicted segmentation map to the provided partial label proportions. This loss encourages the model to output segmentation maps that match the known class ratios, even though the exact pixel-level labels are not available.
The authors evaluate their approach on two public WSI datasets, showing that it can achieve competitive performance compared to fully-supervised baselines while requiring significantly less annotation effort. They also demonstrate the model's ability to generalize to unseen data and its robustness to varying levels of partial label information.
Critical Analysis
The paper presents a promising weakly-supervised approach for WSI segmentation that can leverage partial label proportions. This is a valuable contribution as obtaining full pixel-level annotations for medical imaging tasks is often prohibitively expensive and time-consuming.
One potential limitation is that the proposed method still requires some degree of partial label information, which may not always be available. The authors acknowledge this and suggest exploring semi-supervised or unsupervised techniques as future work.
Additionally, the paper does not provide a detailed analysis of the model's performance on different tissue types or the impact of varying partial label quality. Further investigation into these areas could provide additional insights and guide practical application of the method.
Overall, the research represents an important step towards more efficient and scalable medical image segmentation, and the authors' findings warrant further exploration and validation in real-world clinical settings.
Conclusion
This paper presents a novel weakly-supervised approach for whole slide image segmentation that only requires partial label proportions during training. By leveraging this weaker form of supervision, the method can potentially be applied to a wider range of medical imaging datasets, reducing the burden of obtaining labor-intensive pixel-level annotations.
The key technical contribution is a percentage matching loss that encourages the model to output segmentation maps with class proportions matching the provided partial labels. This allows the model to learn the correct tissue boundaries without needing full pixel-perfect annotations.
The researchers demonstrate the effectiveness of their approach on public WSI datasets, showcasing its ability to achieve competitive performance compared to fully-supervised baselines. This work represents an important step towards more efficient and scalable medical image analysis, with potential implications for clinical decision support and disease diagnosis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning from Partial Label Proportions for Whole Slide Image Segmentation
Shinnosuke Matsuo, Daiki Suehiro, Seiichi Uchida, Hiroaki Ito, Kazuhiro Terada, Akihiko Yoshizawa, Ryoma Bise
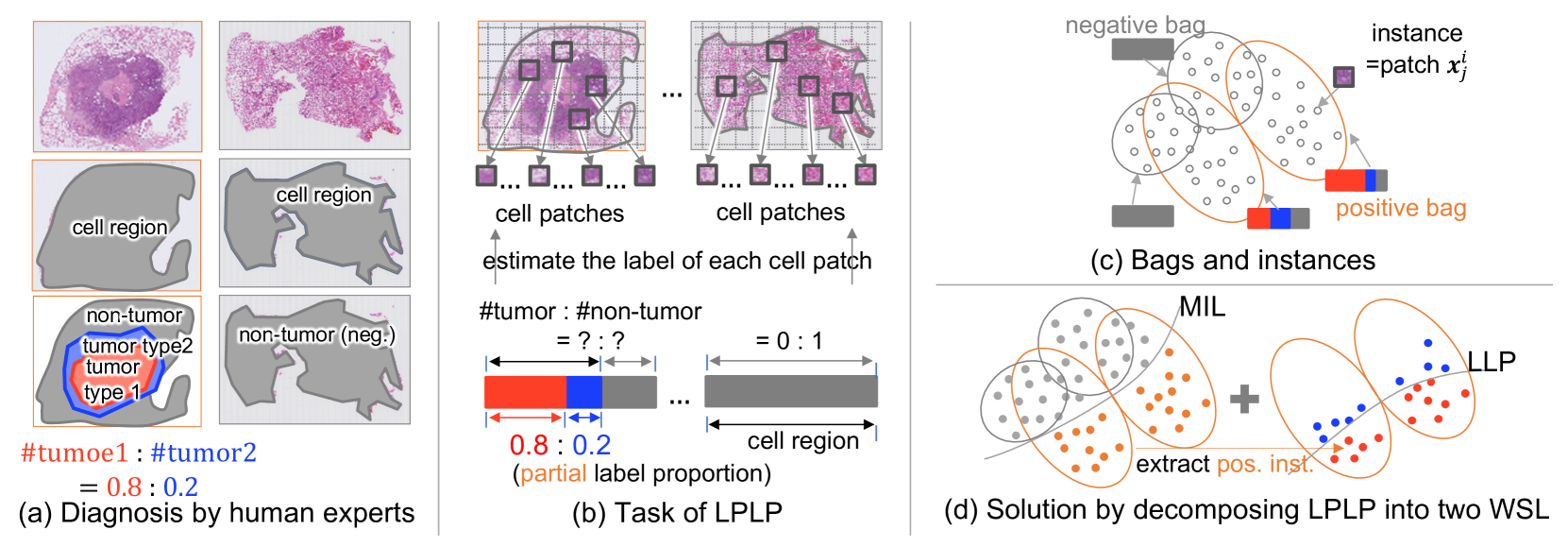
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Read more5/16/2024
🌿
0
Proportion Estimation by Masked Learning from Label Proportion
Takumi Okuo, Kazuya Nishimura, Hiroaki Ito, Kazuhiro Terada, Akihiko Yoshizawa, Ryoma Bise
The PD-L1 rate, the number of PD-L1 positive tumor cells over the total number of all tumor cells, is an important metric for immunotherapy. This metric is recorded as diagnostic information with pathological images. In this paper, we propose a proportion estimation method with a small amount of cell-level annotation and proportion annotation, which can be easily collected. Since the PD-L1 rate is calculated from only `tumor cells' and not using `non-tumor cells', we first detect tumor cells with a detection model. Then, we estimate the PD-L1 proportion by introducing a masking technique to `learning from label proportion.' In addition, we propose a weighted focal proportion loss to address data imbalance problems. Experiments using clinical data demonstrate the effectiveness of our method. Our method achieved the best performance in comparisons.
Read more5/9/2024

0
Superpixelwise Low-rank Approximation based Partial Label Learning for Hyperspectral Image Classification
Shujun Yang, Yu Zhang, Yao Ding, Danfeng Hong
Insufficient prior knowledge of a captured hyperspectral image (HSI) scene may lead the experts or the automatic labeling systems to offer incorrect labels or ambiguous labels (i.e., assigning each training sample to a group of candidate labels, among which only one of them is valid; this is also known as partial label learning) during the labeling process. Accordingly, how to learn from such data with ambiguous labels is a problem of great practical importance. In this paper, we propose a novel superpixelwise low-rank approximation (LRA)-based partial label learning method, namely SLAP, which is the first to take into account partial label learning in HSI classification. SLAP is mainly composed of two phases: disambiguating the training labels and acquiring the predictive model. Specifically, in the first phase, we propose a superpixelwise LRA-based model, preparing the affinity graph for the subsequent label propagation process while extracting the discriminative representation to enhance the following classification task of the second phase. Then to disambiguate the training labels, label propagation propagates the labeling information via the affinity graph of training pixels. In the second phase, we take advantage of the resulting disambiguated training labels and the discriminative representations to enhance the classification performance. The extensive experiments validate the advantage of the proposed SLAP method over state-of-the-art methods.
Read more5/28/2024

0
Finding Regions of Interest in Whole Slide Images Using Multiple Instance Learning
Martim Afonso, Praphulla M. S. Bhawsar, Monjoy Saha, Jonas S. Almeida, Arlindo L. Oliveira
Whole Slide Images (WSI), obtained by high-resolution digital scanning of microscope slides at multiple scales, are the cornerstone of modern Digital Pathology. However, they represent a particular challenge to AI-based/AI-mediated analysis because pathology labeling is typically done at slide-level, instead of tile-level. It is not just that medical diagnostics is recorded at the specimen level, the detection of oncogene mutation is also experimentally obtained, and recorded by initiatives like The Cancer Genome Atlas (TCGA), at the slide level. This configures a dual challenge: a) accurately predicting the overall cancer phenotype and b) finding out what cellular morphologies are associated with it at the tile level. To address these challenges, a weakly supervised Multiple Instance Learning (MIL) approach was explored for two prevalent cancer types, Invasive Breast Carcinoma (TCGA-BRCA) and Lung Squamous Cell Carcinoma (TCGA-LUSC). This approach was explored for tumor detection at low magnification levels and TP53 mutations at various levels. Our results show that a novel additive implementation of MIL matched the performance of reference implementation (AUC 0.96), and was only slightly outperformed by Attention MIL (AUC 0.97). More interestingly from the perspective of the molecular pathologist, these different AI architectures identify distinct sensitivities to morphological features (through the detection of Regions of Interest, RoI) at different amplification levels. Tellingly, TP53 mutation was most sensitive to features at the higher applications where cellular morphology is resolved.
Read more4/12/2024