Proportion Estimation by Masked Learning from Label Proportion

0
🌿
Sign in to get full access
Overview
- The PD-L1 rate, which measures the proportion of tumor cells that express PD-L1, is an important metric for cancer immunotherapy.
- This paper proposes a method to estimate the PD-L1 rate from pathological images, using a small amount of cell-level and proportion annotations.
- The key steps are: 1) detecting tumor cells, and 2) estimating the PD-L1 proportion using a masking technique and weighted focal proportion loss.
- Experiments on clinical data demonstrate the effectiveness of the proposed method.
Plain English Explanation
One of the important factors in deciding if a cancer patient should receive immunotherapy is the PD-L1 rate - the percentage of a patient's tumor cells that express a protein called PD-L1. Doctors need to know this PD-L1 rate to determine the best treatment.
To measure the PD-L1 rate, doctors look at samples of a patient's tumor under a microscope and count the number of tumor cells that are positive for PD-L1. This can be a time-consuming and error-prone process.
The researchers in this paper developed a new AI-based method to automate the PD-L1 rate estimation. Their approach only requires a small amount of manual labeling, making it easy to use in practice.
First, the method detects which cells in the sample are actual tumor cells, as opposed to normal, non-tumor cells. Then, it estimates the proportion of the tumor cells that are PD-L1 positive.
The researchers used a special "masking" technique and a weighted loss function to improve the accuracy of the PD-L1 proportion estimation, especially when there is an imbalance in the data.
Tests on real clinical data showed that this new automated method performed better than other approaches at estimating the PD-L1 rate. This could help doctors make more informed decisions about immunotherapy for their cancer patients.
Technical Explanation
The core of this paper is a new method for estimating the PD-L1 rate - the proportion of tumor cells in a pathological image that express the PD-L1 protein. This metric is critical for determining a cancer patient's eligibility for immunotherapy treatments.
The proposed approach first uses a tumor cell detection model to identify which cells in the image are actual tumor cells, as the PD-L1 rate is calculated using only the tumor cell population.
Next, the method estimates the PD-L1 proportion using a "learning from label proportion" technique. Specifically, it introduces a masking step to focus the model on just the tumor cell regions when predicting the PD-L1 proportion. Additionally, the researchers designed a weighted focal proportion loss function to address potential data imbalance issues, where there may be many more PD-L1 negative than positive tumor cells.
Experiments on clinical datasets demonstrated the effectiveness of this automated PD-L1 proportion estimation approach compared to other methods. The proposed technique achieved the best performance, suggesting it could provide a valuable tool to assist doctors in making immunotherapy decisions.
Critical Analysis
The paper presents a promising solution for the important clinical problem of efficiently and accurately estimating the PD-L1 rate from pathological images. The authors' use of a tumor cell detection model and their novel masking and weighted loss techniques are thoughtful approaches to addressing the key challenges.
One potential limitation is the reliance on a small amount of manual cell-level and proportion annotations for training the models. In real-world clinical settings, acquiring these labeled datasets may still require significant effort from pathologists. Further research could explore methods to reduce or eliminate the need for such annotations, perhaps through techniques like unsupervised or self-supervised learning.
Additionally, the paper does not provide much insight into the types of errors or biases that may arise with this automated PD-L1 estimation approach. For example, it's unclear how the method would perform on samples with unusual tumor cell morphologies or atypical PD-L1 expression patterns. Deeper analysis of failure cases and potential confounding factors could strengthen the critical evaluation of this work.
Overall, this research represents an important step forward in enhancing AI diagnostics for cancer care. With further refinement and validation, the proposed technique could become a valuable tool to support clinicians in making more informed decisions about immunotherapy for their patients.
Conclusion
This paper introduces a new method for automatically estimating the PD-L1 rate from pathological images, a critical metric for determining cancer immunotherapy eligibility. The approach combines tumor cell detection with a novel masking-based proportion estimation technique and a weighted loss function to achieve strong performance on clinical datasets.
While the reliance on some manual annotations is a potential limitation, the researchers have demonstrated a promising path forward for enhancing AI-based cancer diagnostics. Further development and validation of this work could lead to important real-world impacts, helping clinicians make more informed and effective treatment decisions for their cancer patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
Proportion Estimation by Masked Learning from Label Proportion
Takumi Okuo, Kazuya Nishimura, Hiroaki Ito, Kazuhiro Terada, Akihiko Yoshizawa, Ryoma Bise
The PD-L1 rate, the number of PD-L1 positive tumor cells over the total number of all tumor cells, is an important metric for immunotherapy. This metric is recorded as diagnostic information with pathological images. In this paper, we propose a proportion estimation method with a small amount of cell-level annotation and proportion annotation, which can be easily collected. Since the PD-L1 rate is calculated from only `tumor cells' and not using `non-tumor cells', we first detect tumor cells with a detection model. Then, we estimate the PD-L1 proportion by introducing a masking technique to `learning from label proportion.' In addition, we propose a weighted focal proportion loss to address data imbalance problems. Experiments using clinical data demonstrate the effectiveness of our method. Our method achieved the best performance in comparisons.
Read more5/9/2024
0
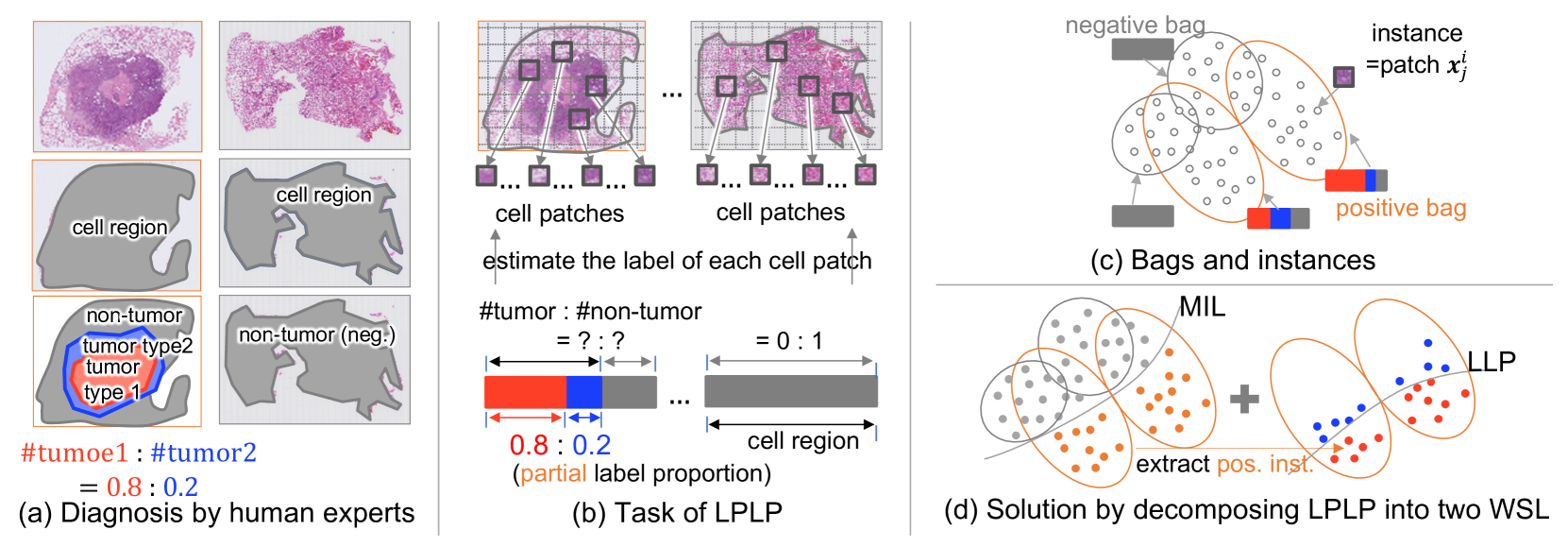
Learning from Partial Label Proportions for Whole Slide Image Segmentation
Shinnosuke Matsuo, Daiki Suehiro, Seiichi Uchida, Hiroaki Ito, Kazuhiro Terada, Akihiko Yoshizawa, Ryoma Bise
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Read more5/16/2024

0
PD-L1 Classification of Weakly-Labeled Whole Slide Images of Breast Cancer
Giacomo Cignoni, Cristian Scatena, Chiara Frascarelli, Nicola Fusco, Antonio Giuseppe Naccarato, Giuseppe Nicol'o Fanelli, Alina S^irbu
Specific and effective breast cancer therapy relies on the accurate quantification of PD-L1 positivity in tumors, which appears in the form of brown stainings in high resolution whole slide images (WSIs). However, the retrieval and extensive labeling of PD-L1 stained WSIs is a time-consuming and challenging task for pathologists, resulting in low reproducibility, especially for borderline images. This study aims to develop and compare models able to classify PD-L1 positivity of breast cancer samples based on WSI analysis, relying only on WSI-level labels. The task consists of two phases: identifying regions of interest (ROI) and classifying tumors as PD-L1 positive or negative. For the latter, two model categories were developed, with different feature extraction methodologies. The first encodes images based on the colour distance from a base color. The second uses a convolutional autoencoder to obtain embeddings of WSI tiles, and aggregates them into a WSI-level embedding. For both model types, features are fed into downstream ML classifiers. Two datasets from different clinical centers were used in two different training configurations: (1) training on one dataset and testing on the other; (2) combining the datasets. We also tested the performance with or without human preprocessing to remove brown artefacts Colour distance based models achieve the best performances on testing configuration (1) with artefact removal, while autoencoder-based models are superior in the remaining cases, which are prone to greater data variability.
Read more4/17/2024

0
Optimistic Rates for Learning from Label Proportions
Gene Li, Lin Chen, Adel Javanmard, Vahab Mirrokni
We consider a weakly supervised learning problem called Learning from Label Proportions (LLP), where examples are grouped into ``bags'' and only the average label within each bag is revealed to the learner. We study various learning rules for LLP that achieve PAC learning guarantees for classification loss. We establish that the classical Empirical Proportional Risk Minimization (EPRM) learning rule (Yu et al., 2014) achieves fast rates under realizability, but EPRM and similar proportion matching learning rules can fail in the agnostic setting. We also show that (1) a debiased proportional square loss, as well as (2) a recently proposed EasyLLP learning rule (Busa-Fekete et al., 2023) both achieve ``optimistic rates'' (Panchenko, 2002); in both the realizable and agnostic settings, their sample complexity is optimal (up to log factors) in terms of $epsilon, delta$, and VC dimension.
Read more6/4/2024