Learning Instruction-Guided Manipulation Affordance via Large Models for Embodied Robotic Tasks

0

Sign in to get full access
Overview
- The paper explores learning instruction-guided manipulation affordance using large language models for embodied robotic tasks.
- It aims to enable robots to understand and execute task-relevant manipulation actions based on natural language instructions.
- The approach involves using a large language model to learn task-relevant manipulation affordances, which are then used for downstream robotic control.
Plain English Explanation
The paper describes a method to help robots better understand and carry out tasks based on natural language instructions. The key idea is to use a powerful language model - a type of AI system trained on a huge amount of text data - to learn what manipulation actions (e.g. grasping, pushing, pulling) are relevant for different tasks.
For example, if a human tells a robot "Pick up the cup and put it on the table," the robot needs to understand that it should grasp the cup and move it to the table. The language model allows the robot to learn these task-relevant manipulation skills directly from the instruction, without having to be explicitly programmed for every possible scenario.
This approach aims to make robots more flexible and adaptable, allowing them to handle a wider variety of tasks and instructions compared to traditional robotic control systems. By leveraging the broad knowledge captured in large language models, the robots can better comprehend and execute the intent behind natural language commands.
Technical Explanation
The paper presents a framework for learning instruction-guided manipulation affordance using large language models. The key components are:
-
Instruction Encoder: A transformer-based language model (e.g. GPT-3) is used to encode the task instruction into a dense vector representation.
-
Manipulation Affordance Learner: This module takes the instruction encoding and the current robot state (e.g. camera images) as input, and learns to predict the relevant manipulation actions (e.g. grasp, push, pull) for completing the task.
-
Robotic Control: The predicted manipulation affordances are then used to guide the low-level control of the robot's actuators to execute the task.
The model is trained end-to-end using a combination of unsupervised pretraining on language data and finetuning on a dataset of human demonstrations of manipulation tasks paired with natural language instructions.
The experiments show that this approach can enable robots to effectively carry out a variety of manipulation tasks, such as rearranging objects or using tools, based on high-level natural language commands. The use of large language models allows the system to generalize beyond the specific training data, exhibiting more flexible and adaptive behavior compared to traditional robotic control methods.
Critical Analysis
The paper makes a compelling case for the potential of large language models to enhance the instruction-following capabilities of robotic systems. By leveraging the rich semantic and commonsense knowledge captured in these models, the robots can better understand and execute the intent behind natural language commands.
However, the paper also acknowledges several limitations and areas for further research:
-
Grounding in Physical Reality: While the language model can learn high-level manipulation affordances, there may still be challenges in reliably grounding these abstract concepts to the robot's physical sensors and actuators. Bridging this "reality gap" is an ongoing challenge in embodied AI.
-
Generalization and Robustness: The experiments demonstrate the approach on a limited set of tasks and environments. Further research is needed to evaluate the system's ability to generalize to more diverse and complex real-world settings.
-
Safety and Reliability: Deploying such systems in the real world will require careful consideration of safety and reliability, as errors or unintended behaviors could have serious consequences. Techniques for ensuring robust and predictable performance will be crucial.
-
Interpretability and Transparency: As with many large neural network models, the internal workings of the manipulation affordance learner may be difficult to interpret and audit. Improving the transparency and explainability of these systems is an important direction for future research.
Overall, the paper presents an intriguing approach that leverages the power of large language models to enhance robotic manipulation capabilities. However, realizing the full potential of this technique will likely require addressing the various challenges and limitations outlined above.
Conclusion
This paper explores a novel approach to enabling robots to better understand and execute tasks based on natural language instructions. By using a large language model to learn task-relevant manipulation affordances, the system can exhibit more flexible and adaptable behavior compared to traditional robotic control methods.
While the paper demonstrates promising results, it also highlights several areas for further research and development, such as grounding the abstract knowledge in physical reality, ensuring robust generalization, and improving the interpretability of the system. Addressing these challenges will be important for realizing the full potential of this technique and deploying such systems in real-world applications.
Overall, the work represents an exciting step forward in the quest to develop more intelligent and intuitive robotic assistants that can seamlessly collaborate with humans through natural language communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Instruction-Guided Manipulation Affordance via Large Models for Embodied Robotic Tasks
Dayou Li, Chenkun Zhao, Shuo Yang, Lin Ma, Yibin Li, Wei Zhang
We study the task of language instruction-guided robotic manipulation, in which an embodied robot is supposed to manipulate the target objects based on the language instructions. In previous studies, the predicted manipulation regions of the target object typically do not change with specification from the language instructions, which means that the language perception and manipulation prediction are separate. However, in human behavioral patterns, the manipulation regions of the same object will change for different language instructions. In this paper, we propose Instruction-Guided Affordance Net (IGANet) for predicting affordance maps of instruction-guided robotic manipulation tasks by utilizing powerful priors from vision and language encoders pre-trained on large-scale datasets. We develop a Vison-Language-Models(VLMs)-based data augmentation pipeline, which can generate a large amount of data automatically for model training. Besides, with the help of Large-Language-Models(LLMs), actions can be effectively executed to finish the tasks defined by instructions. A series of real-world experiments revealed that our method can achieve better performance with generated data. Moreover, our model can generalize better to scenarios with unseen objects and language instructions.
Read more8/21/2024

0
ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models
Siyuan Huang, Iaroslav Ponomarenko, Zhengkai Jiang, Xiaoqi Li, Xiaobin Hu, Peng Gao, Hongsheng Li, Hao Dong
While the integration of Multi-modal Large Language Models (MLLMs) with robotic systems has significantly improved robots' ability to understand and execute natural language instructions, their performance in manipulation tasks remains limited due to a lack of robotics-specific knowledge. Conventional MLLMs are typically trained on generic image-text pairs, leaving them deficient in understanding affordances and physical concepts crucial for manipulation. To address this gap, we propose ManipVQA, a novel framework that infuses MLLMs with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. This approach encompasses tool detection, affordance recognition, and a broader understanding of physical concepts. We curated a diverse dataset of images depicting interactive objects, to challenge robotic understanding in tool detection, affordance prediction, and physical concept comprehension. To effectively integrate this robotics-specific knowledge with the inherent vision-reasoning capabilities of MLLMs, we leverage a unified VQA format and devise a fine-tuning strategy. This strategy preserves the original vision-reasoning abilities while incorporating the newly acquired robotic insights. Empirical evaluations conducted in robotic simulators and across various vision task benchmarks demonstrate the robust performance of ManipVQA. The code and dataset are publicly available at https://github.com/SiyuanHuang95/ManipVQA.
Read more8/23/2024

0
Affordance-Guided Reinforcement Learning via Visual Prompting
Olivia Y. Lee, Annie Xie, Kuan Fang, Karl Pertsch, Chelsea Finn
Robots equipped with reinforcement learning (RL) have the potential to learn a wide range of skills solely from a reward signal. However, obtaining a robust and dense reward signal for general manipulation tasks remains a challenge. Existing learning-based approaches require significant data, such as demonstrations or examples of success and failure, to learn task-specific reward functions. Recently, there is also a growing adoption of large multi-modal foundation models for robotics. These models can perform visual reasoning in physical contexts and generate coarse robot motions for various manipulation tasks. Motivated by this range of capability, in this work, we propose and study rewards shaped by vision-language models (VLMs). State-of-the-art VLMs have demonstrated an impressive ability to reason about affordances through keypoints in zero-shot, and we leverage this to define dense rewards for robotic learning. On a real-world manipulation task specified by natural language description, we find that these rewards improve the sample efficiency of autonomous RL and enable successful completion of the task in 20K online finetuning steps. Additionally, we demonstrate the robustness of the approach to reductions in the number of in-domain demonstrations used for pretraining, reaching comparable performance in 35K online finetuning steps.
Read more7/16/2024
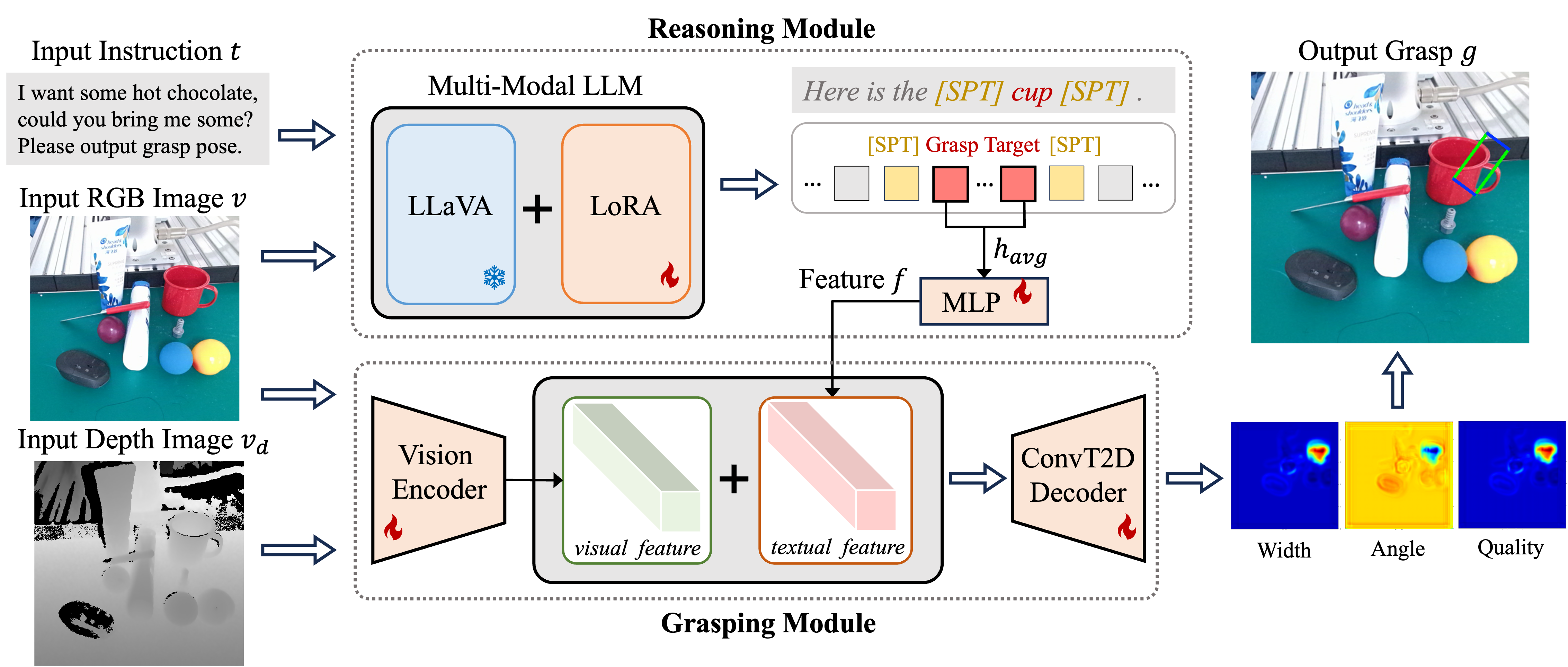
0
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Read more4/29/2024