ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models

0

Sign in to get full access
Overview
- The paper proposes a new model called ManipVQA that combines large language models with robotic affordance and physically grounded information to improve visual question answering (VQA) performance on manipulation-related tasks.
- The model aims to bridge the gap between language, vision, and action by leveraging affordance representations and physical world knowledge.
- Key contributions include a new benchmark dataset for manipulation-focused VQA and an approach for injecting robotic affordance and physical grounding into multi-modal language models.
Plain English Explanation
The researchers have developed a new AI model called ManipVQA that combines large language models with information about how objects can be manipulated and interacted with in the physical world. The goal is to improve the model's ability to answer questions about images related to physical manipulation tasks, like "Can I grip this object?" or "How would I pick up that item?"
Typically, large language models trained on a lot of text data excel at understanding language and answering questions. However, they often lack the grounded physical knowledge needed to reason about real-world interactions and manipulations. ManipVQA tries to bridge this gap by injecting details about object affordances - the actions that can be performed on an object - as well as other physically-grounded information into the language model.
The researchers created a new dataset specifically for testing this type of physically-grounded visual question answering, called the ManipVQA dataset. By training and evaluating ManipVQA on this dataset, they were able to show improvements over standard language models at answering questions that require an understanding of how objects can be manipulated and interacted with in the real world.
Technical Explanation
The key technical innovation of the ManipVQA model is the way it combines large language models with additional information about object affordances and physical world knowledge. Specifically, the model takes in both the image and question as inputs, and uses a series of transformer-based modules to encode and fuse this multi-modal information.
First, the image and question are passed through separate encoding modules to extract visual and linguistic features. Then, a fusion module combines these features with additional affordance and physical reasoning representations. This allows the model to reason about the interaction between the visual contents, the language, and the underlying physical properties and manipulation capabilities.
The affordance representations are derived from a separate model trained on robotic manipulation data, which learns to predict the possible actions that can be performed on different objects. The physical reasoning module taps into a knowledge base of physical commonsense to further ground the model's understanding.
Through extensive experiments on the ManipVQA dataset, the researchers demonstrate that this approach leads to significant performance improvements over baseline language models on visually-grounded manipulation-focused questions. The results highlight the importance of injecting physically-grounded knowledge into multi-modal models to bridge the gap between language, vision, and action.
Critical Analysis
The ManipVQA model represents an important step towards building AI systems that can reason about the physical world in a more grounded and actionable way. By incorporating object affordances and physical commonsense knowledge, the model is able to better understand and answer questions that require an understanding of how objects can be manipulated and interacted with.
That said, the current approach has some limitations. The affordance and physical reasoning representations are derived from separate models and knowledge bases, which introduces additional complexity and potential points of failure. An interesting direction for future work would be to explore end-to-end approaches that can learn these physically-grounded representations directly from data.
Additionally, the ManipVQA dataset, while a valuable benchmark, is still relatively narrow in scope. More diverse datasets that cover a wider range of manipulation-focused tasks and scenarios would help further test the generalization capabilities of this type of approach.
Overall, the ManipVQA model is a promising step forward in bridging the gap between language, vision, and physical action. As this line of research progresses, we may see increasingly capable AI systems that can understand and reason about the world in more intuitive and human-like ways.
Conclusion
The ManipVQA model presented in this paper demonstrates the value of injecting physically-grounded information, such as object affordances and physical commonsense knowledge, into multi-modal language models. By incorporating these elements, the model is able to significantly outperform standard language models on visually-grounded questions that require an understanding of how objects can be manipulated and interacted with.
This work highlights the importance of bridging the gap between language, vision, and physical action in order to build AI systems that can truly understand and reason about the world in a more intuitive and human-like way. As research in this area continues, we may see increasingly capable AI assistants and agents that can better assist humans with a wide range of physical tasks and interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models
Siyuan Huang, Iaroslav Ponomarenko, Zhengkai Jiang, Xiaoqi Li, Xiaobin Hu, Peng Gao, Hongsheng Li, Hao Dong
While the integration of Multi-modal Large Language Models (MLLMs) with robotic systems has significantly improved robots' ability to understand and execute natural language instructions, their performance in manipulation tasks remains limited due to a lack of robotics-specific knowledge. Conventional MLLMs are typically trained on generic image-text pairs, leaving them deficient in understanding affordances and physical concepts crucial for manipulation. To address this gap, we propose ManipVQA, a novel framework that infuses MLLMs with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. This approach encompasses tool detection, affordance recognition, and a broader understanding of physical concepts. We curated a diverse dataset of images depicting interactive objects, to challenge robotic understanding in tool detection, affordance prediction, and physical concept comprehension. To effectively integrate this robotics-specific knowledge with the inherent vision-reasoning capabilities of MLLMs, we leverage a unified VQA format and devise a fine-tuning strategy. This strategy preserves the original vision-reasoning abilities while incorporating the newly acquired robotic insights. Empirical evaluations conducted in robotic simulators and across various vision task benchmarks demonstrate the robust performance of ManipVQA. The code and dataset are publicly available at https://github.com/SiyuanHuang95/ManipVQA.
Read more8/23/2024

0
Learning Instruction-Guided Manipulation Affordance via Large Models for Embodied Robotic Tasks
Dayou Li, Chenkun Zhao, Shuo Yang, Lin Ma, Yibin Li, Wei Zhang
We study the task of language instruction-guided robotic manipulation, in which an embodied robot is supposed to manipulate the target objects based on the language instructions. In previous studies, the predicted manipulation regions of the target object typically do not change with specification from the language instructions, which means that the language perception and manipulation prediction are separate. However, in human behavioral patterns, the manipulation regions of the same object will change for different language instructions. In this paper, we propose Instruction-Guided Affordance Net (IGANet) for predicting affordance maps of instruction-guided robotic manipulation tasks by utilizing powerful priors from vision and language encoders pre-trained on large-scale datasets. We develop a Vison-Language-Models(VLMs)-based data augmentation pipeline, which can generate a large amount of data automatically for model training. Besides, with the help of Large-Language-Models(LLMs), actions can be effectively executed to finish the tasks defined by instructions. A series of real-world experiments revealed that our method can achieve better performance with generated data. Moreover, our model can generalize better to scenarios with unseen objects and language instructions.
Read more8/21/2024
0
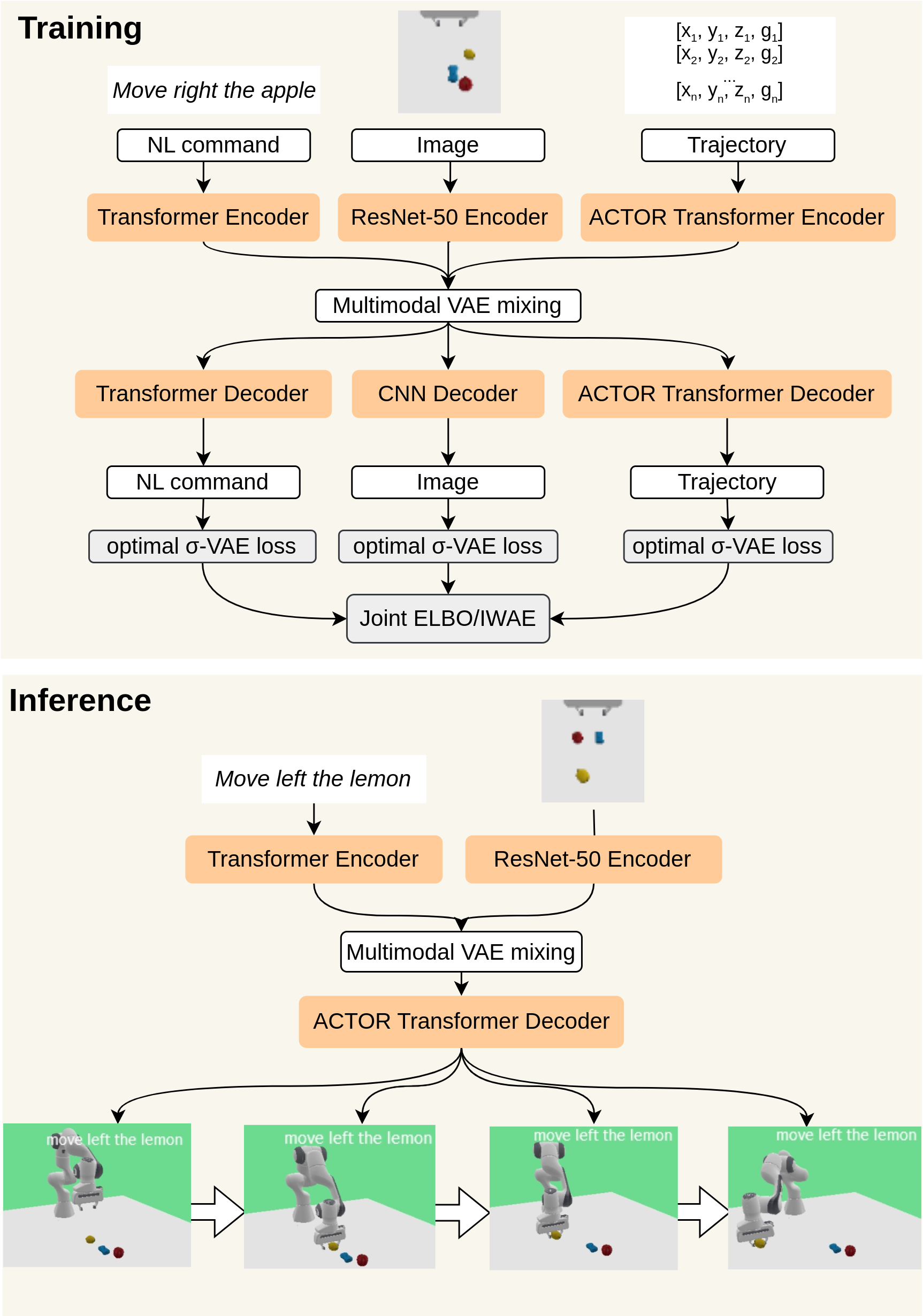
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Gabriela Sejnova, Michal Vavrecka, Karla Stepanova
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
Read more4/3/2024
0
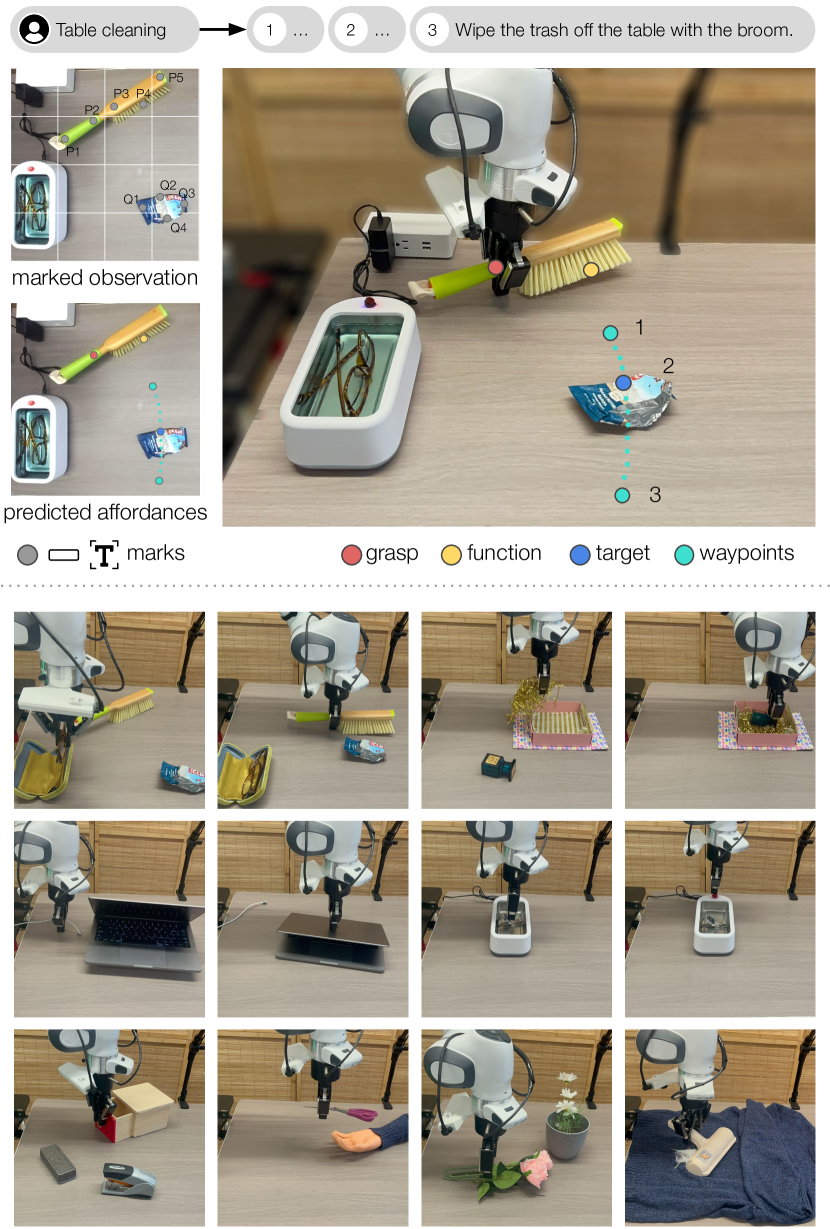
MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting
Fangchen Liu, Kuan Fang, Pieter Abbeel, Sergey Levine
Open-world generalization requires robotic systems to have a profound understanding of the physical world and the user command to solve diverse and complex tasks. While the recent advancement in vision-language models (VLMs) has offered unprecedented opportunities to solve open-world problems, how to leverage their capabilities to control robots remains a grand challenge. In this paper, we introduce Marking Open-world Keypoint Affordances (MOKA), an approach that employs VLMs to solve robotic manipulation tasks specified by free-form language instructions. Central to our approach is a compact point-based representation of affordance, which bridges the VLM's predictions on observed images and the robot's actions in the physical world. By prompting the pre-trained VLM, our approach utilizes the VLM's commonsense knowledge and concept understanding acquired from broad data sources to predict affordances and generate motions. To facilitate the VLM's reasoning in zero-shot and few-shot manners, we propose a visual prompting technique that annotates marks on images, converting affordance reasoning into a series of visual question-answering problems that are solvable by the VLM. We further explore methods to enhance performance with robot experiences collected by MOKA through in-context learning and policy distillation. We evaluate and analyze MOKA's performance on various table-top manipulation tasks including tool use, deformable body manipulation, and object rearrangement.
Read more9/5/2024