Learning Job Title Representation from Job Description Aggregation Network

0

Sign in to get full access
Overview
- This paper introduces a novel job title representation learning method called the Job Description Aggregation Network (JDAN).
- JDAN leverages the semantic information from job descriptions to learn effective representations for job titles.
- The authors demonstrate that JDAN outperforms existing methods on tasks like job title classification and job posting retrieval.
Plain English Explanation
The paper focuses on a problem that's important for companies and job seekers: how to accurately represent and categorize job titles. Job titles can be complex, with nuanced differences that are difficult to capture. The authors propose a new approach called the Job Description Aggregation Network (JDAN) that learns job title representations by analyzing the text of job descriptions.
The key idea is that the full job description contains valuable information that can help distinguish between similar-sounding job titles. For example, the description for a "Software Engineer" role may mention programming languages, frameworks, and software development tasks, while a "Data Analyst" role would focus more on data analysis, reporting, and business intelligence. By learning from these rich job description texts, the JDAN model can build more accurate and nuanced representations of job titles.
The authors show that this JDAN approach outperforms other methods on tasks like classifying job titles and retrieving relevant job postings. This suggests the JDAN model is capturing important semantic information that helps better understand and organize job titles, which could be beneficial for job recommendation systems, job duplication detection, and other applications in the job market domain.
Technical Explanation
The authors propose the Job Description Aggregation Network (JDAN), a novel method for learning effective representations of job titles. JDAN takes a set of job descriptions as input and learns a shared representation that captures the semantic information in the descriptions.
The core of JDAN is a Transformer-based neural network architecture that processes the text of job descriptions. This network learns to aggregate the relevant information from the descriptions into a compact vector representation of the job title. The authors use techniques like attention mechanisms and residual connections to enable the network to effectively distill the key semantic signals.
To train JDAN, the authors leverage large datasets of job postings and their associated titles. The model is trained to predict the correct job title given the description text, incentivizing it to learn representations that capture the nuances distinguishing different job roles.
The authors evaluate JDAN on two key tasks: job title classification and job posting retrieval. On both benchmarks, JDAN outperforms prior methods that rely on simpler representations like word embeddings or entity extraction. This demonstrates the advantages of JDAN's principled approach to learning rich job title representations from aggregated job description data.
Critical Analysis
The authors provide a thorough evaluation of JDAN, demonstrating its strong performance on standard job market tasks. However, the paper does not deeply explore the limitations or potential downsides of the approach.
One potential issue is the reliance on large, high-quality datasets of job postings and descriptions. In practice, many organizations may have more limited data available, which could impact JDAN's effectiveness. The authors should discuss how the model might perform in data-scarce scenarios.
Additionally, the paper does not address potential biases or fairness concerns that could arise from JDAN's representation learning. Job titles and descriptions can reflect societal biases, and the model may inadvertently amplify these issues. Further research is needed to ensure JDAN and similar techniques are developed and deployed responsibly.
Overall, the JDAN method represents an interesting and valuable contribution to the field of job market analysis. However, the authors could strengthen the paper by more thoroughly exploring the limitations, risks, and areas for future work.
Conclusion
This paper introduces the Job Description Aggregation Network (JDAN), a novel approach to learning effective representations of job titles. By leveraging the rich semantic information contained in job descriptions, JDAN is able to outperform prior methods on key tasks like job title classification and job posting retrieval.
The authors' work demonstrates the value of using advanced natural language processing techniques to better understand and organize job market data. The JDAN model's ability to capture nuanced differences between job titles could benefit a wide range of applications, from personalized job recommendations to job market analysis.
While the paper provides a strong technical foundation, further research is needed to address potential limitations and ensure responsible development of such job title representation learning models. Overall, this work represents an important step forward in using AI and NLP to improve our understanding and navigation of the job market.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Job Title Representation from Job Description Aggregation Network
Napat Laosaengpha, Thanit Tativannarat, Chawan Piansaddhayanon, Attapol Rutherford, Ekapol Chuangsuwanich
Learning job title representation is a vital process for developing automatic human resource tools. To do so, existing methods primarily rely on learning the title representation through skills extracted from the job description, neglecting the rich and diverse content within. Thus, we propose an alternative framework for learning job titles through their respective job description (JD) and utilize a Job Description Aggregator component to handle the lengthy description and bidirectional contrastive loss to account for the bidirectional relationship between the job title and its description. We evaluated the performance of our method on both in-domain and out-of-domain settings, achieving a superior performance over the skill-based approach.
Read more6/13/2024
0
Computational Job Market Analysis with Natural Language Processing
Mike Zhang
[Abridged Abstract] Recent technological advances underscore labor market dynamics, yielding significant consequences for employment prospects and increasing job vacancy data across platforms and languages. Aggregating such data holds potential for valuable insights into labor market demands, new skills emergence, and facilitating job matching for various stakeholders. However, despite prevalent insights in the private sector, transparent language technology systems and data for this domain are lacking. This thesis investigates Natural Language Processing (NLP) technology for extracting relevant information from job descriptions, identifying challenges including scarcity of training data, lack of standardized annotation guidelines, and shortage of effective extraction methods from job ads. We frame the problem, obtaining annotated data, and introducing extraction methodologies. Our contributions include job description datasets, a de-identification dataset, and a novel active learning algorithm for efficient model training. We propose skill extraction using weak supervision, a taxonomy-aware pre-training methodology adapting multilingual language models to the job market domain, and a retrieval-augmented model leveraging multiple skill extraction datasets to enhance overall performance. Finally, we ground extracted information within a designated taxonomy.
Read more5/1/2024
0
JobFormer: Skill-Aware Job Recommendation with Semantic-Enhanced Transformer
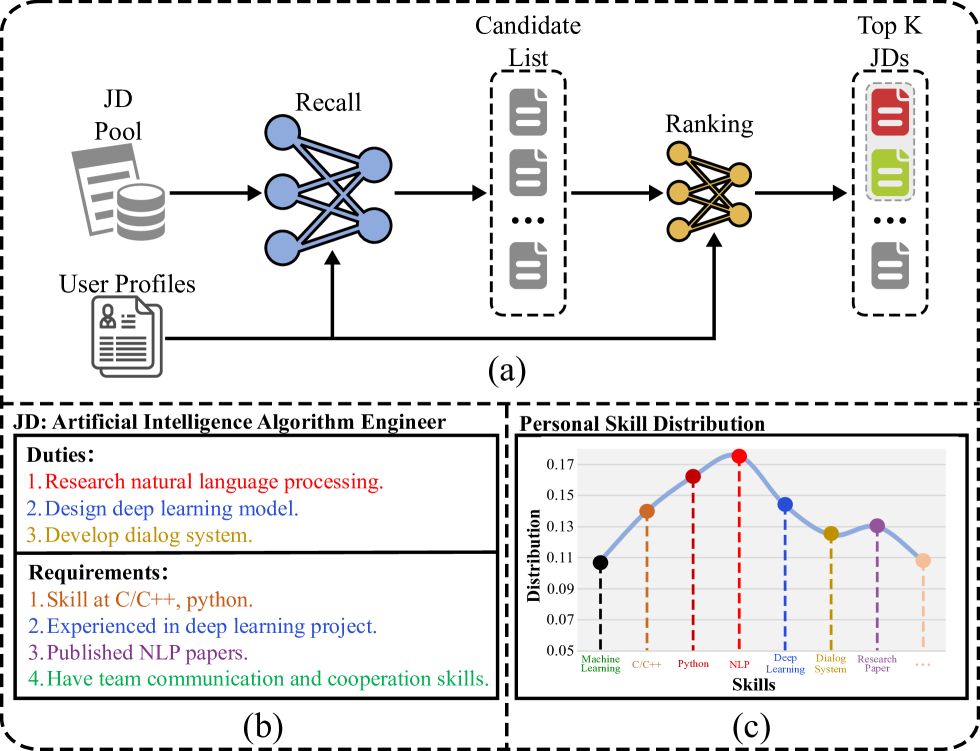
Zhihao Guan, Jia-Qi Yang, Yang Yang, Hengshu Zhu, Wenjie Li, Hui Xiong
Job recommendation aims to provide potential talents with suitable job descriptions (JDs) consistent with their career trajectory, which plays an essential role in proactive talent recruitment. In real-world management scenarios, the available JD-user records always consist of JDs, user profiles, and click data, in which the user profiles are typically summarized as the user's skill distribution for privacy reasons. Although existing sophisticated recommendation methods can be directly employed, effective recommendation still has challenges considering the information deficit of JD itself and the natural heterogeneous gap between JD and user profile. To address these challenges, we proposed a novel skill-aware recommendation model based on the designed semantic-enhanced transformer to parse JDs and complete personalized job recommendation. Specifically, we first model the relative items of each JD and then adopt an encoder with the local-global attention mechanism to better mine the intra-job and inter-job dependencies from JD tuples. Moreover, we adopt a two-stage learning strategy for skill-aware recommendation, in which we utilize the skill distribution to guide JD representation learning in the recall stage, and then combine the user profiles for final prediction in the ranking stage. Consequently, we can embed rich contextual semantic representations for learning JDs, while skill-aware recommendation provides effective JD-user joint representation for click-through rate (CTR) prediction. To validate the superior performance of our method for job recommendation, we present a thorough empirical analysis of large-scale real-world and public datasets to demonstrate its effectiveness and interpretability.
Read more4/9/2024

0
Combining Embeddings and Domain Knowledge for Job Posting Duplicate Detection
Matthias Engelbach, Dennis Klau, Maximilien Kintz, Alexander Ulrich
Job descriptions are posted on many online channels, including company websites, job boards or social media platforms. These descriptions are usually published with varying text for the same job, due to the requirements of each platform or to target different audiences. However, for the purpose of automated recruitment and assistance of people working with these texts, it is helpful to aggregate job postings across platforms and thus detect duplicate descriptions that refer to the same job. In this work, we propose an approach for detecting duplicates in job descriptions. We show that combining overlap-based character similarity with text embedding and keyword matching methods lead to convincing results. In particular, we show that although no approach individually achieves satisfying performance, a combination of string comparison, deep textual embeddings, and the use of curated weighted lookup lists for specific skills leads to a significant boost in overall performance. A tool based on our approach is being used in production and feedback from real-life use confirms our evaluation.
Read more6/11/2024