Computational Job Market Analysis with Natural Language Processing
2404.18977
0
0
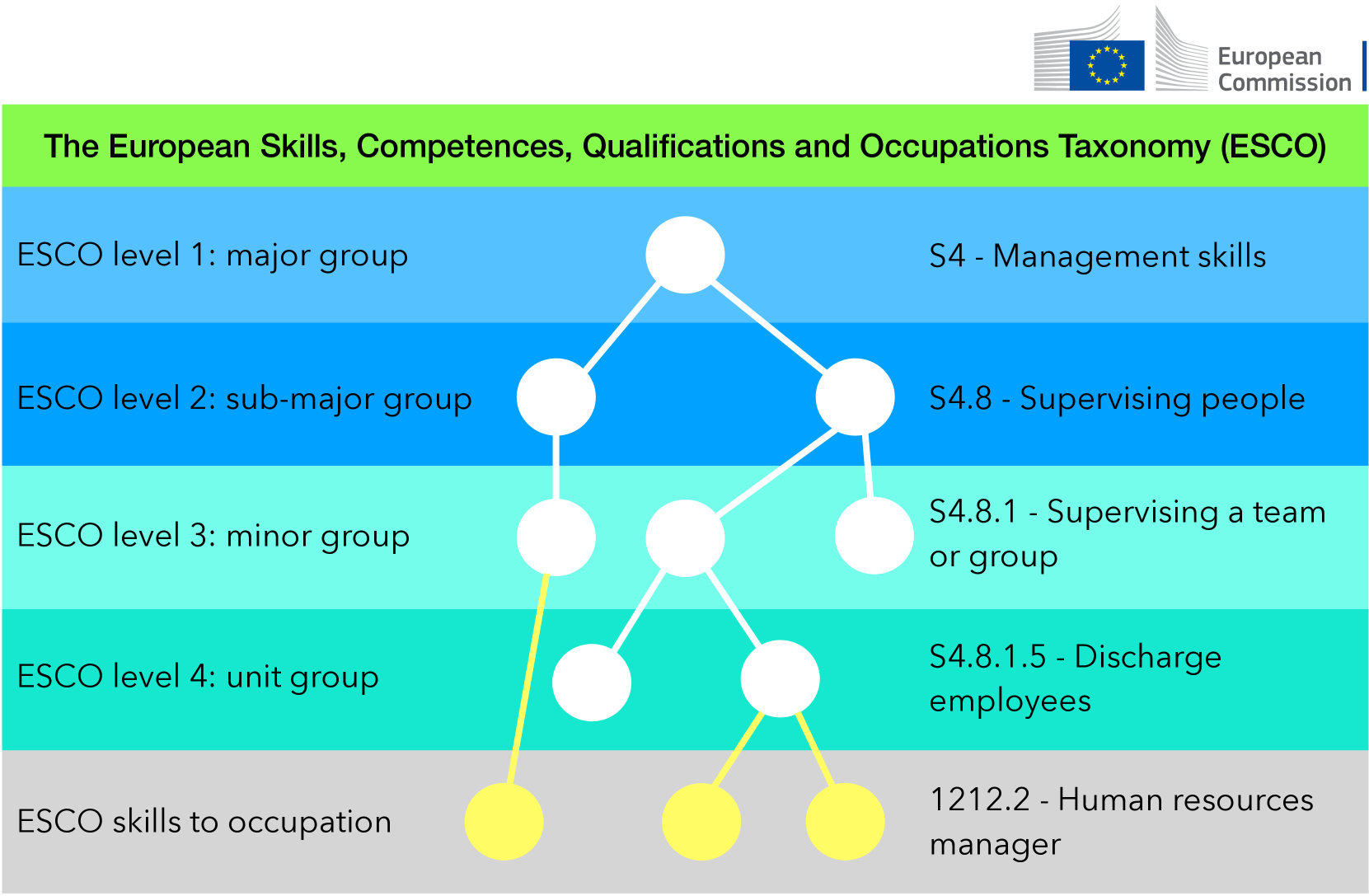
Abstract
[Abridged Abstract] Recent technological advances underscore labor market dynamics, yielding significant consequences for employment prospects and increasing job vacancy data across platforms and languages. Aggregating such data holds potential for valuable insights into labor market demands, new skills emergence, and facilitating job matching for various stakeholders. However, despite prevalent insights in the private sector, transparent language technology systems and data for this domain are lacking. This thesis investigates Natural Language Processing (NLP) technology for extracting relevant information from job descriptions, identifying challenges including scarcity of training data, lack of standardized annotation guidelines, and shortage of effective extraction methods from job ads. We frame the problem, obtaining annotated data, and introducing extraction methodologies. Our contributions include job description datasets, a de-identification dataset, and a novel active learning algorithm for efficient model training. We propose skill extraction using weak supervision, a taxonomy-aware pre-training methodology adapting multilingual language models to the job market domain, and a retrieval-augmented model leveraging multiple skill extraction datasets to enhance overall performance. Finally, we ground extracted information within a designated taxonomy.
Create account to get full access
Overview
- This paper explores the use of natural language processing (NLP) techniques to analyze and understand linguistic dialects and language variation.
- The researchers conduct a comprehensive survey of existing work on NLP and language dialects, covering a range of topics from dataset and task development to use case exploration and model augmentation.
- The paper aims to provide a structured overview of the current state of the field and identify promising directions for future research.
Plain English Explanation
This paper looks at how researchers are using natural language processing (NLP) techniques to study and understand different dialects and variations of language. The researchers reviewed a lot of existing work in this area, covering things like:
- Creating new datasets and tasks to help computers better understand different dialects
- Exploring real-world applications where understanding language variation is important
- Improving language models to make them better at handling dialects and accents
The goal is to provide a comprehensive overview of the current state of this research field and identify promising directions for future work. This could help advance our ability to build AI systems that can communicate more effectively with diverse populations and better understand the nuances of human language.
Technical Explanation
The paper begins by highlighting the importance of studying linguistic dialects and variation, noting that this can have significant implications for a wide range of NLP applications, from speech recognition to machine translation. The authors then provide a thorough review of the existing literature in this area.
Key topics covered include:
-
Dataset and task development: The researchers discuss efforts to create annotated datasets that capture diverse linguistic phenomena, as well as the design of specialized tasks to evaluate NLP systems' handling of dialect-related challenges.
-
Use case exploration: The paper examines real-world applications where understanding language variation is crucial, such as clinical NLP, educational technology, and conversational AI.
-
Model augmentation: The authors review techniques for enhancing language models to better handle dialects, including data augmentation, transfer learning, and meta-learning approaches.
Throughout the survey, the researchers highlight key insights, challenges, and promising directions for future research in this rapidly evolving field of NLP.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the current state of NLP research on linguistic dialects and variation. The authors do a commendable job of covering a wide range of relevant topics and identifying critical areas for further exploration.
One potential limitation mentioned in the paper is the relative scarcity of publicly available datasets that capture the full breadth of dialect phenomena, particularly for under-represented languages and communities. The authors suggest that addressing this data gap should be a priority for the research community going forward.
Additionally, the paper acknowledges the inherent complexity and context-dependence of language variation, which poses significant challenges for developing robust NLP solutions. The authors encourage further research into more nuanced, contextual approaches to handling dialect-related issues.
While the paper offers a thorough review of the existing literature, it could potentially benefit from a more critical analysis of the underlying assumptions and potential biases present in some of the discussed studies. Exploring these aspects in greater depth could help readers develop a more nuanced understanding of the field's limitations and areas for improvement.
Conclusion
This paper provides a comprehensive and insightful survey of NLP research on linguistic dialects and variation. By covering a wide range of relevant topics, from dataset and task development to model augmentation and real-world applications, the authors offer a structured overview of the current state of the field and identify promising directions for future work.
The findings highlighted in this paper could have significant implications for the development of more inclusive and effective NLP systems, capable of better understanding and communicating with diverse populations. As the field continues to evolve, addressing the challenges and opportunities outlined in this survey will be critical for advancing our ability to leverage the power of language technology for the benefit of all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Challenges and Opportunities of NLP for HR Applications: A Discussion Paper
Jochen L. Leidner, Mark Stevenson
0
0
Over the course of the recent decade, tremendous progress has been made in the areas of machine learning and natural language processing, which opened up vast areas of potential application use cases, including hiring and human resource management. We review the use cases for text analytics in the realm of human resources/personnel management, including actually realized as well as potential but not yet implemented ones, and we analyze the opportunities and risks of these.
5/14/2024
🌿
Natural Language Processing for Dialects of a Language: A Survey
Aditya Joshi, Raj Dabre, Diptesh Kanojia, Zhuang Li, Haolan Zhan, Gholamreza Haffari, Doris Dippold
0
0
State-of-the-art natural language processing (NLP) models are trained on massive training corpora, and report a superlative performance on evaluation datasets. This survey delves into an important attribute of these datasets: the dialect of a language. Motivated by the performance degradation of NLP models for dialectic datasets and its implications for the equity of language technologies, we survey past research in NLP for dialects in terms of datasets, and approaches. We describe a wide range of NLP tasks in terms of two categories: natural language understanding (NLU) (for tasks such as dialect classification, sentiment analysis, parsing, and NLU benchmarks) and natural language generation (NLG) (for summarisation, machine translation, and dialogue systems). The survey is also broad in its coverage of languages which include English, Arabic, German among others. We observe that past work in NLP concerning dialects goes deeper than mere dialect classification, and . This includes early approaches that used sentence transduction that lead to the recent approaches that integrate hypernetworks into LoRA. We expect that this survey will be useful to NLP researchers interested in building equitable language technologies by rethinking LLM benchmarks and model architectures.
4/1/2024
🌿
Application of Natural Language Processing in Financial Risk Detection
Liyang Wang, Yu Cheng, Ao Xiang, Jingyu Zhang, Haowei Yang
0
0
This paper explores the application of Natural Language Processing (NLP) in financial risk detection. By constructing an NLP-based financial risk detection model, this study aims to identify and predict potential risks in financial documents and communications. First, the fundamental concepts of NLP and its theoretical foundation, including text mining methods, NLP model design principles, and machine learning algorithms, are introduced. Second, the process of text data preprocessing and feature extraction is described. Finally, the effectiveness and predictive performance of the model are validated through empirical research. The results show that the NLP-based financial risk detection model performs excellently in risk identification and prediction, providing effective risk management tools for financial institutions. This study offers valuable references for the field of financial risk management, utilizing advanced NLP techniques to improve the accuracy and efficiency of financial risk detection.
6/21/2024
🌿
Unlocking Futures: A Natural Language Driven Career Prediction System for Computer Science and Software Engineering Students
Sakir Hossain Faruque, Sharun Akter Khushbu, Sharmin Akter
0
0
A career is a crucial aspect for any person to fulfill their desires through hard work. During their studies, students cannot find the best career suggestions unless they receive meaningful guidance tailored to their skills. Therefore, we developed an AI-assisted model for early prediction to provide better career suggestions. Although the task is difficult, proper guidance can make it easier. Effective career guidance requires understanding a student's academic skills, interests, and skill-related activities. In this research, we collected essential information from Computer Science (CS) and Software Engineering (SWE) students to train a machine learning (ML) model that predicts career paths based on students' career-related information. To adequately train the models, we applied Natural Language Processing (NLP) techniques and completed dataset pre-processing. For comparative analysis, we utilized multiple classification ML algorithms and deep learning (DL) algorithms. This study contributes valuable insights to educational advising by providing specific career suggestions based on the unique features of CS and SWE students. Additionally, the research helps individual CS and SWE students find suitable jobs that match their skills, interests, and skill-related activities.
5/29/2024