Learning a Mini-batch Graph Transformer via Two-stage Interaction Augmentation

0
Sign in to get full access
Overview
- This paper proposes a novel graph transformer model that learns from mini-batch interactions to improve graph-based machine learning tasks.
- The model uses a two-stage interaction augmentation approach to capture both local and global information in the graph data.
- Experiments show the model outperforms state-of-the-art graph neural network and transformer models on semi-supervised node classification and molecular property prediction tasks.
Plain English Explanation
The researchers have developed a new type of machine learning model that can work effectively with graph-structured data, such as social networks or molecular structures. Graphs are a way of representing data that consists of nodes (like people or atoms) connected by edges (like friendships or chemical bonds).
Traditional graph neural network models can struggle to capture both the local connections between nearby nodes and the broader, global patterns in the entire graph. The researchers' new model-agnostic graph neural network approach uses a two-stage process to address this challenge.
First, the model learns about the relationships between small groups of connected nodes (mini-batches). Then, it takes this local knowledge and uses a graph transformer to understand the higher-level structure of the full graph. This two-stage interaction augmentation allows the model to build a more complete understanding of the graph data.
The researchers show that their model outperforms other state-of-the-art approaches on tasks like predicting the properties of molecules and classifying nodes in social networks. This suggests the two-stage approach is an effective way to solve graph-based machine learning problems, even when the data is split into smaller chunks (mini-batches) during training.
Technical Explanation
The key innovation in this paper is the use of a two-stage interaction augmentation process to learn a mini-batch graph transformer model.
In the first stage, the model learns to capture the local interactions between nodes in small subsets (mini-batches) of the full graph. This allows it to understand the relationships between nearby nodes and their direct neighbors.
Then, in the second stage, the model uses a graph transformer architecture to learn about the higher-level, global structure of the entire graph. The transformer takes the local knowledge from the first stage and uses it to model long-range dependencies and broader patterns in the data.
By combining these two stages, the model is able to build a more comprehensive understanding of the graph than approaches that only consider local or global information in isolation. The researchers demonstrate the effectiveness of this two-stage approach through experiments on semi-supervised node classification and molecular property prediction tasks, where their model outperforms state-of-the-art graph neural networks and transformers.
Critical Analysis
One potential limitation of this approach is the reliance on mini-batches during training. While this allows the model to scale to large graphs, it means the local interactions learned in the first stage may not fully capture the context of the entire graph. The researchers acknowledge this and suggest further research into techniques that can better bridge the gap between local and global information.
Additionally, the specific architectural choices and hyperparameter settings of the model are not explored in depth. It's possible that alternative designs or training procedures could further improve the model's performance, and further investigation in this area could yield additional insights.
Overall, the two-stage interaction augmentation approach represents a promising direction for developing more effective graph-based machine learning models. By combining local and global perspectives, the model is able to capture complex patterns in graph-structured data that may be missed by other approaches. However, there is still room for refinement and further exploration of this technique.
Conclusion
This paper introduces a novel graph transformer model that learns from mini-batch interactions using a two-stage interaction augmentation process. This approach allows the model to effectively capture both local and global information in graph data, leading to state-of-the-art performance on semi-supervised node classification and molecular property prediction tasks.
The research represents an important step forward in the development of graph-based machine learning models, demonstrating the value of combining local and global perspectives to build a more comprehensive understanding of complex, interconnected data. As graph-structured data becomes increasingly prevalent in fields like social networks, biology, and materials science, models like this one will be crucial for unlocking the insights hidden within these rich, relational datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning a Mini-batch Graph Transformer via Two-stage Interaction Augmentation
Wenda Li, Kaixuan Chen, Shunyu Liu, Tongya Zheng, Wenjie Huang, Mingli Song
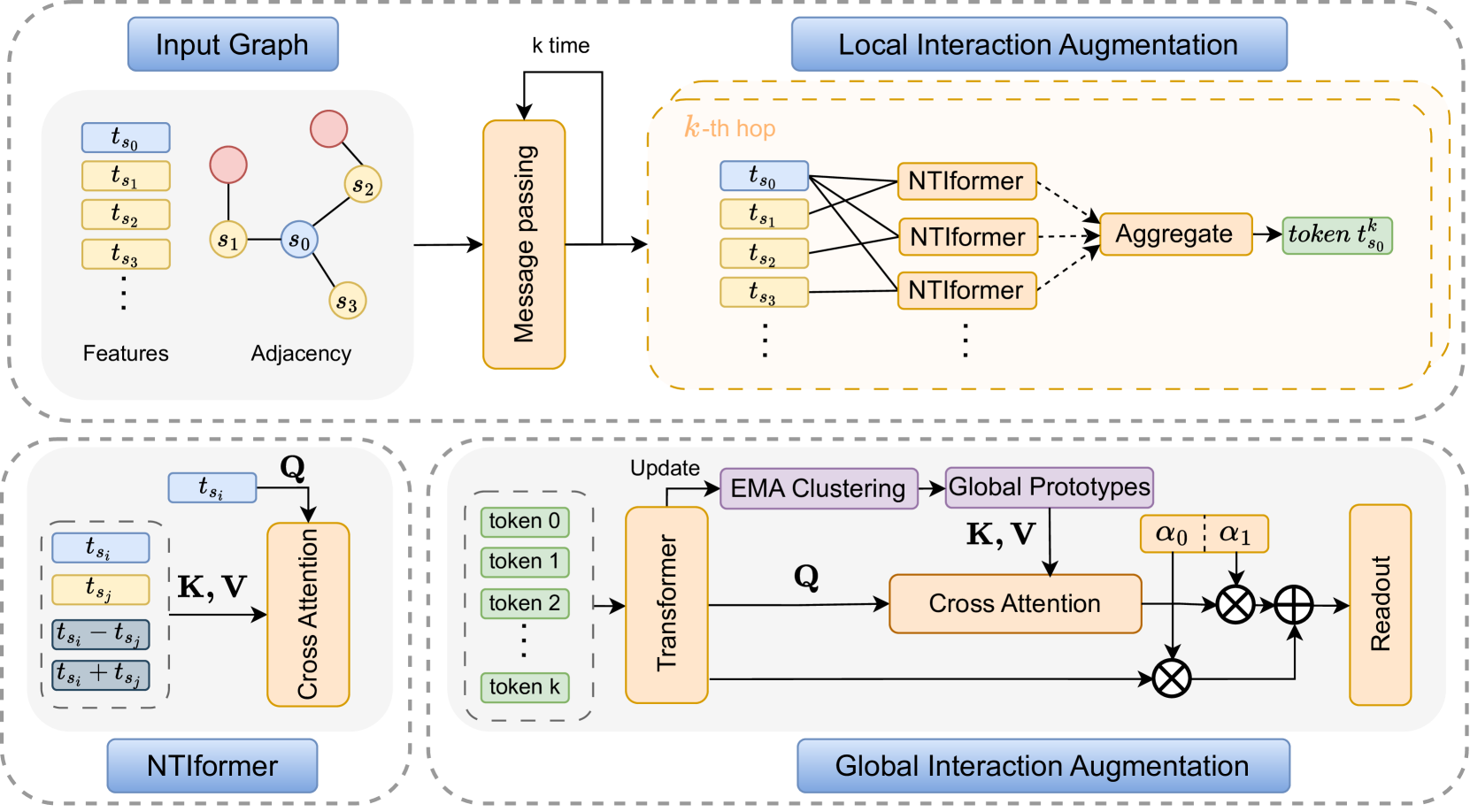
Mini-batch Graph Transformer (MGT), as an emerging graph learning model, has demonstrated significant advantages in semi-supervised node prediction tasks with improved computational efficiency and enhanced model robustness. However, existing methods for processing local information either rely on sampling or simple aggregation, which respectively result in the loss and squashing of critical neighbor information.Moreover, the limited number of nodes in each mini-batch restricts the model's capacity to capture the global characteristic of the graph. In this paper, we propose LGMformer, a novel MGT model that employs a two-stage augmented interaction strategy, transitioning from local to global perspectives, to address the aforementioned bottlenecks.The local interaction augmentation (LIA) presents a neighbor-target interaction Transformer (NTIformer) to acquire an insightful understanding of the co-interaction patterns between neighbors and the target node, resulting in a locally effective token list that serves as input for the MGT. In contrast, global interaction augmentation (GIA) adopts a cross-attention mechanism to incorporate entire graph prototypes into the target node epresentation, thereby compensating for the global graph information to ensure a more comprehensive perception. To this end, LGMformer achieves the enhancement of node representations under the MGT paradigm.Experimental results related to node classification on the ten benchmark datasets demonstrate the effectiveness of the proposed method. Our code is available at https://github.com/l-wd/LGMformer.
Read more7/16/2024

0
Hypergraph Transformer for Semi-Supervised Classification
Zexi Liu, Bohan Tang, Ziyuan Ye, Xiaowen Dong, Siheng Chen, Yanfeng Wang
Hypergraphs play a pivotal role in the modelling of data featuring higher-order relations involving more than two entities. Hypergraph neural networks emerge as a powerful tool for processing hypergraph-structured data, delivering remarkable performance across various tasks, e.g., hypergraph node classification. However, these models struggle to capture global structural information due to their reliance on local message passing. To address this challenge, we propose a novel hypergraph learning framework, HyperGraph Transformer (HyperGT). HyperGT uses a Transformer-based neural network architecture to effectively consider global correlations among all nodes and hyperedges. To incorporate local structural information, HyperGT has two distinct designs: i) a positional encoding based on the hypergraph incidence matrix, offering valuable insights into node-node and hyperedge-hyperedge interactions; and ii) a hypergraph structure regularization in the loss function, capturing connectivities between nodes and hyperedges. Through these designs, HyperGT achieves comprehensive hypergraph representation learning by effectively incorporating global interactions while preserving local connectivity patterns. Extensive experiments conducted on real-world hypergraph node classification tasks showcase that HyperGT consistently outperforms existing methods, establishing new state-of-the-art benchmarks. Ablation studies affirm the effectiveness of the individual designs of our model.
Read more6/4/2024

0
Triplet Interaction Improves Graph Transformers: Accurate Molecular Graph Learning with Triplet Graph Transformers
Md Shamim Hussain, Mohammed J. Zaki, Dharmashankar Subramanian
Graph transformers typically lack third-order interactions, limiting their geometric understanding which is crucial for tasks like molecular geometry prediction. We propose the Triplet Graph Transformer (TGT) that enables direct communication between pairs within a 3-tuple of nodes via novel triplet attention and aggregation mechanisms. TGT is applied to molecular property prediction by first predicting interatomic distances from 2D graphs and then using these distances for downstream tasks. A novel three-stage training procedure and stochastic inference further improve training efficiency and model performance. Our model achieves new state-of-the-art (SOTA) results on open challenge benchmarks PCQM4Mv2 and OC20 IS2RE. We also obtain SOTA results on QM9, MOLPCBA, and LIT-PCBA molecular property prediction benchmarks via transfer learning. We also demonstrate the generality of TGT with SOTA results on the traveling salesman problem (TSP).
Read more6/11/2024
➖
0
Less is More: on the Over-Globalizing Problem in Graph Transformers
Yujie Xing, Xiao Wang, Yibo Li, Hai Huang, Chuan Shi
Graph Transformer, due to its global attention mechanism, has emerged as a new tool in dealing with graph-structured data. It is well recognized that the global attention mechanism considers a wider receptive field in a fully connected graph, leading many to believe that useful information can be extracted from all the nodes. In this paper, we challenge this belief: does the globalizing property always benefit Graph Transformers? We reveal the over-globalizing problem in Graph Transformer by presenting both empirical evidence and theoretical analysis, i.e., the current attention mechanism overly focuses on those distant nodes, while the near nodes, which actually contain most of the useful information, are relatively weakened. Then we propose a novel Bi-Level Global Graph Transformer with Collaborative Training (CoBFormer), including the inter-cluster and intra-cluster Transformers, to prevent the over-globalizing problem while keeping the ability to extract valuable information from distant nodes. Moreover, the collaborative training is proposed to improve the model's generalization ability with a theoretical guarantee. Extensive experiments on various graphs well validate the effectiveness of our proposed CoBFormer.
Read more5/27/2024