Less is More: on the Over-Globalizing Problem in Graph Transformers

0
➖
Sign in to get full access
Overview
- Explores the limitations of the global attention mechanism in Graph Transformers
- Proposes a novel Bi-Level Global Graph Transformer with Collaborative Training (CoBFormer) to address the over-globalizing problem
- Demonstrates the effectiveness of CoBFormer through extensive experiments on various graphs
Plain English Explanation
Graph Transformers have become a popular tool for working with graph-structured data, thanks to their global attention mechanism. This mechanism allows them to consider information from all the nodes in a graph, which many believe can be useful. However, this paper challenges this belief, providing evidence that the global attention mechanism can actually be detrimental.
The researchers found that the current attention mechanism in Graph Transformers tends to focus too much on distant nodes, while relatively weakening the influence of nearby nodes, which often contain the most useful information. To address this "over-globalizing" problem, the researchers propose a new model called CoBFormer.
CoBFormer uses a "bi-level" approach, with separate Transformers for handling interactions between clusters of nodes (inter-cluster) and within each cluster (intra-cluster). This helps prevent the over-globalizing issue while still allowing the model to extract valuable information from distant nodes. The researchers also introduce a "collaborative training" technique to improve the model's generalization ability.
Through extensive experiments, the researchers demonstrate the effectiveness of CoBFormer in overcoming the limitations of traditional Graph Transformers. This work provides important insights into the design of graph neural networks and suggests that a more nuanced approach to global attention may be necessary for certain types of graph-structured data.
Technical Explanation
This paper investigates the limitations of the global attention mechanism in Graph Transformers. The researchers present both empirical evidence and theoretical analysis to show that the current attention mechanism in Graph Transformers tends to over-focus on distant nodes, while relatively weakening the influence of nearby nodes that often contain the most useful information.
To address this "over-globalizing" problem, the researchers propose a novel Bi-Level Global Graph Transformer with Collaborative Training (CoBFormer). CoBFormer uses a hierarchical approach, with separate Transformers for handling interactions between clusters of nodes (inter-cluster) and within each cluster (intra-cluster). This helps prevent the over-globalizing issue while still allowing the model to extract valuable information from distant nodes.
The researchers also introduce a "collaborative training" technique, where the inter-cluster and intra-cluster Transformers are trained jointly to improve the model's generalization ability. This approach is supported by a theoretical guarantee.
Extensive experiments on various graphs demonstrate the effectiveness of CoBFormer in overcoming the limitations of traditional Graph Transformers. The results show that CoBFormer consistently outperforms other state-of-the-art models, particularly on tasks where the over-globalizing problem is more pronounced.
Critical Analysis
The paper provides a comprehensive analysis of the limitations of the global attention mechanism in Graph Transformers and presents a novel solution in the form of CoBFormer. The researchers' empirical and theoretical evidence for the over-globalizing problem is compelling and raises important questions about the design of graph neural networks.
However, the paper does not delve into the potential reasons why the over-globalizing problem occurs in the first place. It would be interesting to further explore the underlying mechanisms and factors that contribute to this issue, as this could lead to even more insights and potential solutions.
Additionally, while the collaborative training approach is promising, the paper could have provided more details on the specific implementation and the intuition behind it. A deeper discussion of the trade-offs and potential drawbacks of this technique would also be valuable.
Overall, this paper makes a significant contribution to the field of graph representation learning and encourages researchers to think critically about the design choices in graph neural networks. The insights and the proposed CoBFormer model have the potential to inspire further advancements in this area.
Conclusion
This paper challenges the widely held belief that the global attention mechanism in Graph Transformers is always beneficial. Through rigorous analysis, the researchers uncover the "over-globalizing" problem, where the current attention mechanism overly focuses on distant nodes, while weakening the influence of nearby nodes that often contain the most useful information.
To address this issue, the researchers propose the Bi-Level Global Graph Transformer with Collaborative Training (CoBFormer), a novel architecture that separates inter-cluster and intra-cluster interactions and uses a collaborative training approach to improve generalization. The extensive experimental results demonstrate the effectiveness of CoBFormer in overcoming the limitations of traditional Graph Transformers.
This work provides important insights into the design of graph neural networks and suggests that a more nuanced approach to global attention may be necessary for certain types of graph-structured data. The findings and the proposed CoBFormer model have the potential to drive further advancements in the field of graph representation learning and its applications across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Less is More: on the Over-Globalizing Problem in Graph Transformers
Yujie Xing, Xiao Wang, Yibo Li, Hai Huang, Chuan Shi
Graph Transformer, due to its global attention mechanism, has emerged as a new tool in dealing with graph-structured data. It is well recognized that the global attention mechanism considers a wider receptive field in a fully connected graph, leading many to believe that useful information can be extracted from all the nodes. In this paper, we challenge this belief: does the globalizing property always benefit Graph Transformers? We reveal the over-globalizing problem in Graph Transformer by presenting both empirical evidence and theoretical analysis, i.e., the current attention mechanism overly focuses on those distant nodes, while the near nodes, which actually contain most of the useful information, are relatively weakened. Then we propose a novel Bi-Level Global Graph Transformer with Collaborative Training (CoBFormer), including the inter-cluster and intra-cluster Transformers, to prevent the over-globalizing problem while keeping the ability to extract valuable information from distant nodes. Moreover, the collaborative training is proposed to improve the model's generalization ability with a theoretical guarantee. Extensive experiments on various graphs well validate the effectiveness of our proposed CoBFormer.
Read more5/27/2024

0
SGFormer: Simplifying and Empowering Transformers for Large-Graph Representations
Qitian Wu, Wentao Zhao, Chenxiao Yang, Hengrui Zhang, Fan Nie, Haitian Jiang, Yatao Bian, Junchi Yan
Learning representations on large-sized graphs is a long-standing challenge due to the inter-dependence nature involved in massive data points. Transformers, as an emerging class of foundation encoders for graph-structured data, have shown promising performance on small graphs due to its global attention capable of capturing all-pair influence beyond neighboring nodes. Even so, existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated models by stacking deep multi-head attentions. In this paper, we critically demonstrate that even using a one-layer attention can bring up surprisingly competitive performance across node property prediction benchmarks where node numbers range from thousand-level to billion-level. This encourages us to rethink the design philosophy for Transformers on large graphs, where the global attention is a computation overhead hindering the scalability. We frame the proposed scheme as Simplified Graph Transformers (SGFormer), which is empowered by a simple attention model that can efficiently propagate information among arbitrary nodes in one layer. SGFormer requires none of positional encodings, feature/graph pre-processing or augmented loss. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M and yields up to 141x inference acceleration over SOTA Transformers on medium-sized graphs. Beyond current results, we believe the proposed methodology alone enlightens a new technical path of independent interest for building Transformers on large graphs.
Read more8/19/2024

0
New!SGFormer: Single-Layer Graph Transformers with Approximation-Free Linear Complexity
Qitian Wu, Kai Yang, Hengrui Zhang, David Wipf, Junchi Yan
Learning representations on large graphs is a long-standing challenge due to the inter-dependence nature. Transformers recently have shown promising performance on small graphs thanks to its global attention for capturing all-pair interactions beyond observed structures. Existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated architectures by stacking deep attention-based propagation layers. In this paper, we attempt to evaluate the necessity of adopting multi-layer attentions in Transformers on graphs, which considerably restricts the efficiency. Specifically, we analyze a generic hybrid propagation layer, comprised of all-pair attention and graph-based propagation, and show that multi-layer propagation can be reduced to one-layer propagation, with the same capability for representation learning. It suggests a new technical path for building powerful and efficient Transformers on graphs, particularly through simplifying model architectures without sacrificing expressiveness. As exemplified by this work, we propose a Simplified Single-layer Graph Transformers (SGFormer), whose main component is a single-layer global attention that scales linearly w.r.t. graph sizes and requires none of any approximation for accommodating all-pair interactions. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M, yielding orders-of-magnitude inference acceleration over peer Transformers on medium-sized graphs, and demonstrates competitiveness with limited labeled data.
Read more9/16/2024
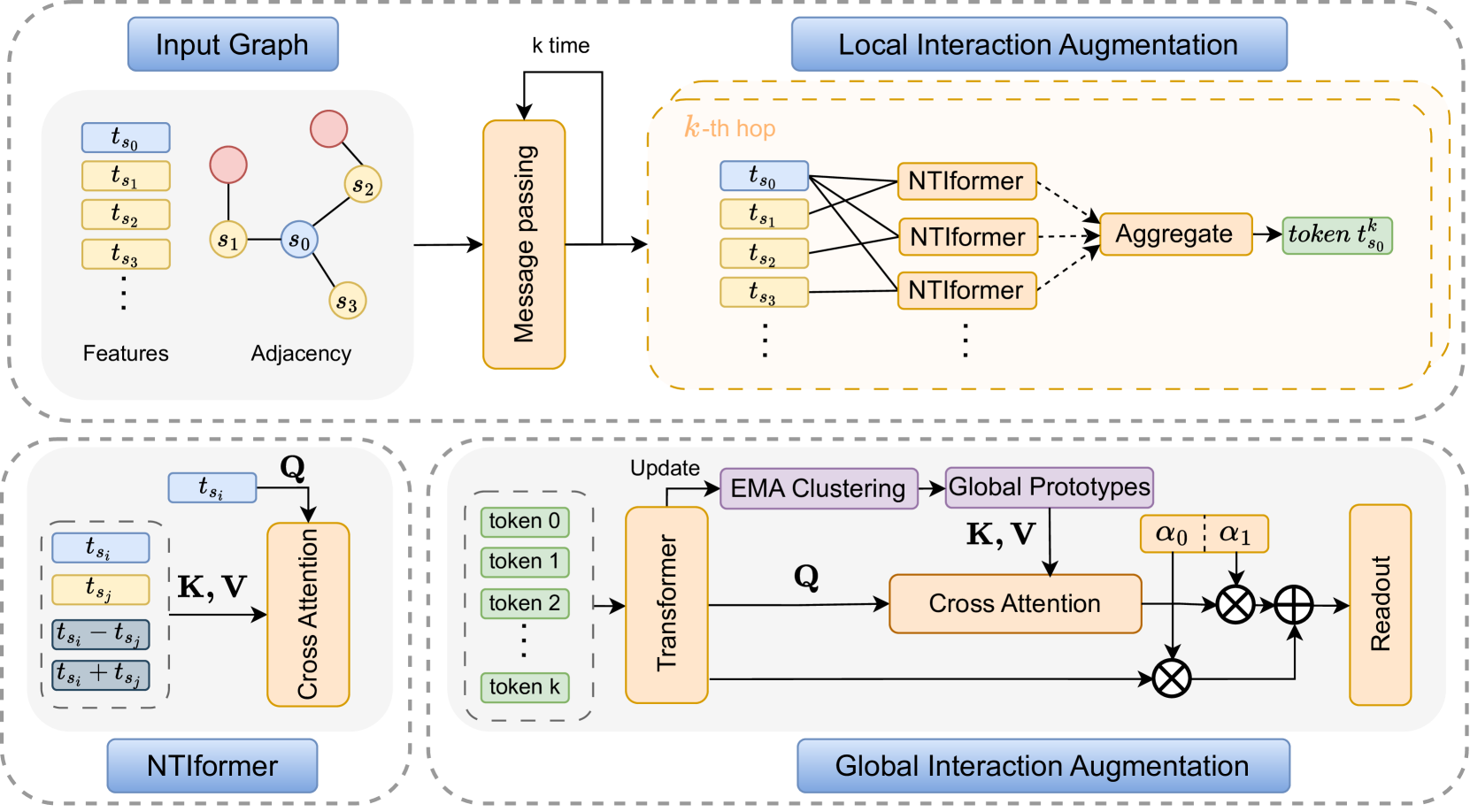
0
Learning a Mini-batch Graph Transformer via Two-stage Interaction Augmentation
Wenda Li, Kaixuan Chen, Shunyu Liu, Tongya Zheng, Wenjie Huang, Mingli Song
Mini-batch Graph Transformer (MGT), as an emerging graph learning model, has demonstrated significant advantages in semi-supervised node prediction tasks with improved computational efficiency and enhanced model robustness. However, existing methods for processing local information either rely on sampling or simple aggregation, which respectively result in the loss and squashing of critical neighbor information.Moreover, the limited number of nodes in each mini-batch restricts the model's capacity to capture the global characteristic of the graph. In this paper, we propose LGMformer, a novel MGT model that employs a two-stage augmented interaction strategy, transitioning from local to global perspectives, to address the aforementioned bottlenecks.The local interaction augmentation (LIA) presents a neighbor-target interaction Transformer (NTIformer) to acquire an insightful understanding of the co-interaction patterns between neighbors and the target node, resulting in a locally effective token list that serves as input for the MGT. In contrast, global interaction augmentation (GIA) adopts a cross-attention mechanism to incorporate entire graph prototypes into the target node epresentation, thereby compensating for the global graph information to ensure a more comprehensive perception. To this end, LGMformer achieves the enhancement of node representations under the MGT paradigm.Experimental results related to node classification on the ten benchmark datasets demonstrate the effectiveness of the proposed method. Our code is available at https://github.com/l-wd/LGMformer.
Read more7/16/2024