Learning Neural Networks with Sparse Activations

0
🧠
Sign in to get full access
Overview
- This paper explores learning neural networks with sparse activations, which means having few active neurons in the network.
- The researchers investigate the theoretical and practical aspects of training neural networks to achieve sparse activations, both under uniform and general distributions of the input data.
- The findings have implications for building more efficient and interpretable neural network models, as well as potential applications in neuromorphic computing and continual learning.
Plain English Explanation
Neural networks are a type of machine learning model inspired by the human brain. They are made up of interconnected "neurons" that transmit signals to each other. When training a neural network, the goal is for the network to learn patterns in data and make accurate predictions.
One way to make neural networks more efficient is by encouraging "sparse activations." This means having only a small number of neurons active at any given time, rather than having all neurons firing. Sparse activations can reduce the computational resources needed to run the network, as well as make the model more interpretable.
This paper explores different techniques for training neural networks to achieve sparse activations. The researchers look at how the distribution of the input data (i.e., the information going into the network) affects the sparsity of the activations. They investigate training under both uniform distributions, where the input data is spread out evenly, and more general distributions, which may have certain patterns or skewed distributions.
By understanding the theory and practical considerations around sparse activations, the researchers hope to provide insights that can help develop more efficient and interpretable neural network models. This could have applications in areas like neuromorphic computing, which aims to build hardware inspired by the brain, as well as continual learning, where the goal is to have neural networks that can continuously learn new information without forgetting what they've learned before.
Technical Explanation
The paper focuses on analyzing the theoretical and practical aspects of training neural networks to achieve sparse activations. Sparse activations refer to having only a small number of active neurons in the network at any given time, rather than having all neurons firing.
The researchers first investigate the case of learning under a uniform distribution of the input data. They derive theoretical bounds on the achievable sparsity of the activations and propose a training algorithm that can provably learn networks with sparse activations in this setting.
Next, the paper explores the more general case of learning under arbitrary input distributions. The authors show that the sparsity of the activations depends on the specific structure of the input distribution. They develop a training procedure that can adapt to different input distributions and still achieve sparse activations.
The proposed training algorithms leverage techniques like sparse regularization and sparse initialization to encourage sparse activations during the learning process. The experiments demonstrate the effectiveness of these methods on various neural network architectures and datasets.
Critical Analysis
The paper provides a rigorous theoretical and empirical analysis of the problem of learning neural networks with sparse activations. The researchers have carefully considered the impact of the input data distribution on the achievable sparsity and have proposed corresponding training algorithms.
One potential limitation of the work is that it primarily focuses on the case of feed-forward neural networks. It would be interesting to see how the insights and techniques extend to more complex neural network architectures, such as recurrent neural networks or transformers, which are widely used in practice.
Additionally, the paper does not delve into the potential trade-offs between sparsity and other desirable properties of neural networks, such as accuracy or generalization. It would be valuable to explore the practical implications of sparse activations and how they might affect the overall performance and robustness of the models.
Further research could also investigate the interplay between weight sparsity and activity sparsity in neural networks, as these two forms of sparsity could potentially complement each other in building efficient and interpretable models.
Conclusion
This paper presents a comprehensive study of learning neural networks with sparse activations. The researchers have developed theoretical insights and practical training algorithms that can achieve sparse activations under both uniform and general input distributions.
The findings from this work could have significant implications for building more efficient and interpretable neural network models. Sparse activations can reduce the computational resources required to run the models, making them potentially more suitable for deployment in resource-constrained environments, such as neuromorphic computing systems.
Additionally, the increased sparsity and interpretability of the models could benefit applications in continual learning, where the goal is to have neural networks that can continuously learn new information without forgetting what they've learned before.
Overall, this paper provides valuable insights and tools for researchers and practitioners interested in developing more efficient and interpretable neural network models, with potential applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Learning Neural Networks with Sparse Activations
Pranjal Awasthi, Nishanth Dikkala, Pritish Kamath, Raghu Meka
A core component present in many successful neural network architectures, is an MLP block of two fully connected layers with a non-linear activation in between. An intriguing phenomenon observed empirically, including in transformer architectures, is that, after training, the activations in the hidden layer of this MLP block tend to be extremely sparse on any given input. Unlike traditional forms of sparsity, where there are neurons/weights which can be deleted from the network, this form of {em dynamic} activation sparsity appears to be harder to exploit to get more efficient networks. Motivated by this we initiate a formal study of PAC learnability of MLP layers that exhibit activation sparsity. We present a variety of results showing that such classes of functions do lead to provable computational and statistical advantages over their non-sparse counterparts. Our hope is that a better theoretical understanding of {em sparsely activated} networks would lead to methods that can exploit activation sparsity in practice.
Read more6/27/2024
0
Achieving Sparse Activation in Small Language Models
Jifeng Song, Kai Huang, Xiangyu Yin, Boyuan Yang, Wei Gao
Sparse activation, which selectively activates only an input-dependent set of neurons in inference, is a useful technique to reduce the computing cost of Large Language Models (LLMs) without retraining or adaptation efforts. However, whether it can be applied to the recently emerging Small Language Models (SLMs) remains questionable, because SLMs are generally less over-parameterized than LLMs. In this paper, we aim to achieve sparse activation in SLMs. We first show that the existing sparse activation schemes in LLMs that build on neurons' output magnitudes cannot be applied to SLMs, and activating neurons based on their attribution scores is a better alternative. Further, we demonstrated and quantified the large errors of existing attribution metrics when being used for sparse activation, due to the interdependency among attribution scores of neurons across different layers. Based on these observations, we proposed a new attribution metric that can provably correct such errors and achieve precise sparse activation. Experiments over multiple popular SLMs and datasets show that our approach can achieve 80% sparsification ratio with <5% model accuracy loss, comparable to the sparse activation achieved in LLMs. The source code is available at: https://github.com/pittisl/Sparse-Activation.
Read more6/12/2024
0
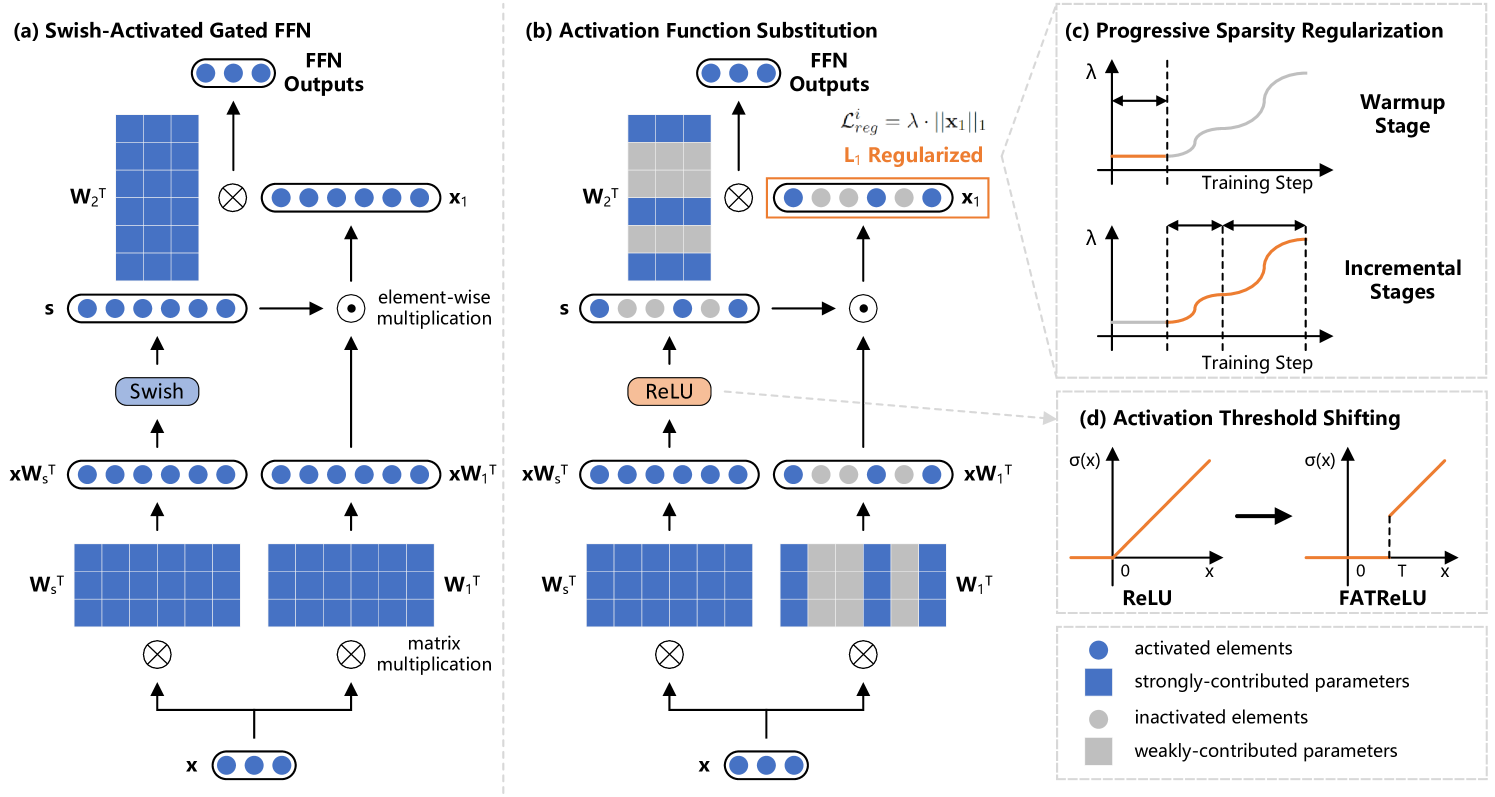
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guangli Li, Tao Yang, Maosong Sun
Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, activation sparsity has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces a simple and effective sparsification method named ProSparse to push LLMs for higher activation sparsity while maintaining comparable performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along the multi-stage sine curves. This can enhance activation sparsity and mitigate performance degradation by avoiding radical shifts in activation distributions. With ProSparse, we obtain high sparsity of 89.32% for LLaMA2-7B, 88.80% for LLaMA2-13B, and 87.89% for end-size MiniCPM-1B, respectively, achieving comparable performance to their original Swish-activated versions. These present the most sparsely activated models among open-source LLaMA versions and competitive end-size models, considerably surpassing ReluLLaMA-7B (66.98%) and ReluLLaMA-13B (71.56%). Our inference acceleration experiments further demonstrate the significant practical acceleration potential of LLMs with higher activation sparsity, obtaining up to 4.52$times$ inference speedup.
Read more7/4/2024
💬
0
Weight Sparsity Complements Activity Sparsity in Neuromorphic Language Models
Rishav Mukherji, Mark Schone, Khaleelulla Khan Nazeer, Christian Mayr, David Kappel, Anand Subramoney
Activity and parameter sparsity are two standard methods of making neural networks computationally more efficient. Event-based architectures such as spiking neural networks (SNNs) naturally exhibit activity sparsity, and many methods exist to sparsify their connectivity by pruning weights. While the effect of weight pruning on feed-forward SNNs has been previously studied for computer vision tasks, the effects of pruning for complex sequence tasks like language modeling are less well studied since SNNs have traditionally struggled to achieve meaningful performance on these tasks. Using a recently published SNN-like architecture that works well on small-scale language modeling, we study the effects of weight pruning when combined with activity sparsity. Specifically, we study the trade-off between the multiplicative efficiency gains the combination affords and its effect on task performance for language modeling. To dissect the effects of the two sparsities, we conduct a comparative analysis between densely activated models and sparsely activated event-based models across varying degrees of connectivity sparsity. We demonstrate that sparse activity and sparse connectivity complement each other without a proportional drop in task performance for an event-based neural network trained on the Penn Treebank and WikiText-2 language modeling datasets. Our results suggest sparsely connected event-based neural networks are promising candidates for effective and efficient sequence modeling.
Read more5/2/2024