Hard ASH: Sparsity and the right optimizer make a continual learner

0

Sign in to get full access
Overview
- The paper introduces "Hard ASH", a novel continual learning algorithm that leverages sparsity and the right optimizer to achieve strong performance.
- Hard ASH builds upon the existing ASH algorithm, which was designed for training sparse neural networks.
- The key innovations in Hard ASH include using a momentum-based optimizer and introducing a novel regularization term to encourage sparsity throughout training.
Plain English Explanation
The researchers developed a new machine learning algorithm called "Hard ASH" that can continually learn and adapt over time without forgetting previously learned information. This is a challenging problem in AI known as "continual learning".
The core idea behind Hard ASH is to leverage the power of sparse neural networks. Sparse models have many connections (or "weights") set to zero, making them more efficient and easier to update. The researchers found that using the right optimization technique, along with a sparsity-encouraging regularizer, allows Hard ASH to continually learn new tasks without catastrophically forgetting old ones.
To explain this in more simple terms, imagine you're trying to learn multiple new skills over time, like playing the guitar, cooking, and speaking a new language. Normally, learning a new skill can cause you to forget parts of the old skills. Hard ASH is like a smart study method that allows you to gradually build up all your skills without losing what you previously learned.
The ASH algorithm was an earlier approach to training sparse neural networks, but Hard ASH improves upon it with better optimization and a novel way to encourage sparsity. This makes Hard ASH more effective at continual learning compared to previous methods.
Technical Explanation
The paper begins by discussing the challenges of continual learning, where an AI system must learn new tasks without forgetting previous knowledge. The authors note that sparse neural networks, as explored in the ASH algorithm, can be a promising approach for continual learning due to their efficiency and ability to selectively update parameters.
Building on ASH, the authors introduce Hard ASH, which incorporates two key innovations:
-
Use of a momentum-based optimizer: The authors found that using a momentum-based optimizer, such as Adam, improves the continual learning performance of sparse neural networks compared to the original ASH, which used a simpler gradient descent optimizer.
-
Novel sparsity-encouraging regularization: Hard ASH introduces a new regularization term that encourages sparsity not just in the initial network, but throughout the entire continual learning process. This helps maintain a sparse model structure as new tasks are learned.
The paper then presents extensive experiments comparing Hard ASH to other continual learning algorithms, such as EWC and FLAASH. The results demonstrate that Hard ASH significantly outperforms these baselines on a range of continual learning benchmarks, highlighting the benefits of its sparsity-aware approach.
Critical Analysis
The paper provides a thorough evaluation of Hard ASH and makes a compelling case for its effectiveness in continual learning tasks. However, the authors acknowledge that Hard ASH, like other continual learning methods, still faces challenges in scenarios with significant distributional shift or when learning very dissimilar tasks in succession.
Additionally, while the paper demonstrates the advantages of Hard ASH over other algorithms, it would be valuable to see a more in-depth analysis of the trade-offs and limitations of the approach. For example, the impact of the sparsity-encouraging regularization on model expressivity or the computational overhead of the momentum-based optimizer could be further explored.
It would also be interesting to see how Hard ASH performs on more diverse continual learning benchmarks, such as those involving multi-modal data or long-term dependencies, to better understand the broader applicability of the method.
Conclusion
The Hard ASH algorithm represents an important advancement in the field of continual learning, demonstrating how sparsity and the right optimization techniques can enable AI systems to continuously learn new skills without forgetting old ones. By building on the foundations of the ASH algorithm and introducing novel sparsity-aware components, the authors have developed a continual learning approach that outperforms several state-of-the-art baselines.
While not without its limitations, the success of Hard ASH suggests that leveraging sparse neural network structures could be a promising direction for developing robust and efficient continual learning systems. As the field of AI continues to evolve, techniques like Hard ASH may play a crucial role in enabling machines to learn and adapt in a more human-like manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hard ASH: Sparsity and the right optimizer make a continual learner
Santtu Keskinen
In class incremental learning, neural networks typically suffer from catastrophic forgetting. We show that an MLP featuring a sparse activation function and an adaptive learning rate optimizer can compete with established regularization techniques in the Split-MNIST task. We highlight the effectiveness of the Adaptive SwisH (ASH) activation function in this context and introduce a novel variant, Hard Adaptive SwisH (Hard ASH) to further enhance the learning retention.
Read more4/30/2024
🧠
0
Learning Neural Networks with Sparse Activations
Pranjal Awasthi, Nishanth Dikkala, Pritish Kamath, Raghu Meka
A core component present in many successful neural network architectures, is an MLP block of two fully connected layers with a non-linear activation in between. An intriguing phenomenon observed empirically, including in transformer architectures, is that, after training, the activations in the hidden layer of this MLP block tend to be extremely sparse on any given input. Unlike traditional forms of sparsity, where there are neurons/weights which can be deleted from the network, this form of {em dynamic} activation sparsity appears to be harder to exploit to get more efficient networks. Motivated by this we initiate a formal study of PAC learnability of MLP layers that exhibit activation sparsity. We present a variety of results showing that such classes of functions do lead to provable computational and statistical advantages over their non-sparse counterparts. Our hope is that a better theoretical understanding of {em sparsely activated} networks would lead to methods that can exploit activation sparsity in practice.
Read more6/27/2024
0
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guangli Li, Tao Yang, Maosong Sun
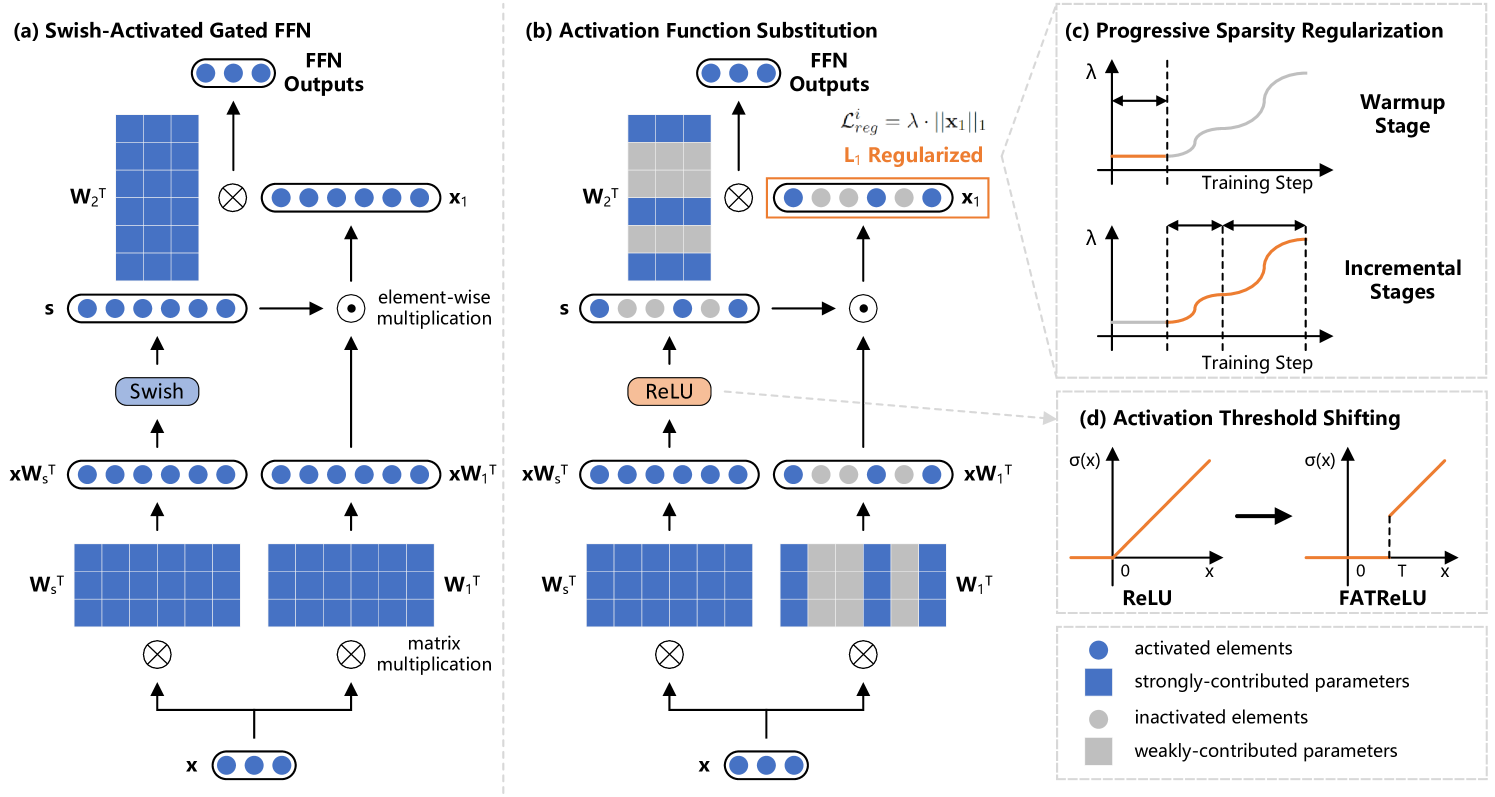
Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, activation sparsity has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces a simple and effective sparsification method named ProSparse to push LLMs for higher activation sparsity while maintaining comparable performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along the multi-stage sine curves. This can enhance activation sparsity and mitigate performance degradation by avoiding radical shifts in activation distributions. With ProSparse, we obtain high sparsity of 89.32% for LLaMA2-7B, 88.80% for LLaMA2-13B, and 87.89% for end-size MiniCPM-1B, respectively, achieving comparable performance to their original Swish-activated versions. These present the most sparsely activated models among open-source LLaMA versions and competitive end-size models, considerably surpassing ReluLLaMA-7B (66.98%) and ReluLLaMA-13B (71.56%). Our inference acceleration experiments further demonstrate the significant practical acceleration potential of LLMs with higher activation sparsity, obtaining up to 4.52$times$ inference speedup.
Read more7/4/2024
7
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Yixin Song, Haotong Xie, Zhengyan Zhang, Bo Wen, Li Ma, Zeyu Mi, Haibo Chen
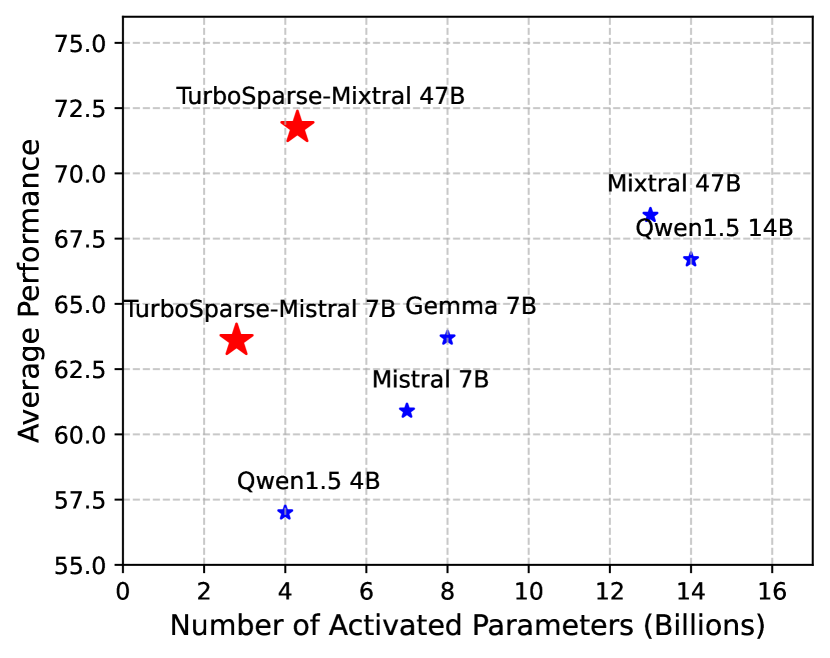
Exploiting activation sparsity is a promising approach to significantly accelerating the inference process of large language models (LLMs) without compromising performance. However, activation sparsity is determined by activation functions, and commonly used ones like SwiGLU and GeGLU exhibit limited sparsity. Simply replacing these functions with ReLU fails to achieve sufficient sparsity. Moreover, inadequate training data can further increase the risk of performance degradation. To address these challenges, we propose a novel dReLU function, which is designed to improve LLM activation sparsity, along with a high-quality training data mixture ratio to facilitate effective sparsification. Additionally, we leverage sparse activation patterns within the Feed-Forward Network (FFN) experts of Mixture-of-Experts (MoE) models to further boost efficiency. By applying our neuron sparsification method to the Mistral and Mixtral models, only 2.5 billion and 4.3 billion parameters are activated per inference iteration, respectively, while achieving even more powerful model performance. Evaluation results demonstrate that this sparsity achieves a 2-5x decoding speedup. Remarkably, on mobile phones, our TurboSparse-Mixtral-47B achieves an inference speed of 11 tokens per second. Our models are available at url{https://huggingface.co/PowerInfer}
Read more6/12/2024