Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning

0
Sign in to get full access
Overview
- This paper describes a deep reinforcement learning approach to teach a bipedal robot how to play soccer from an egocentric (first-person) perspective.
- The researchers developed a simulation environment and trained a deep neural network to control the robot's actions based on visual inputs.
- The goal was to enable the robot to learn agile soccer skills, such as dribbling, passing, and shooting, without relying on external sensors or pre-programmed behaviors.
Plain English Explanation
In this research, the scientists wanted to teach a two-legged robot how to play soccer using a deep learning technique called reinforcement learning. Instead of programming the robot with specific soccer skills, they created a simulation environment where the robot could learn on its own by trial and error.
The key idea was to let the robot learn from its own experiences, similar to how a human child might learn to play soccer. The robot was equipped with a camera to see the soccer ball and field from its own perspective (called "egocentric vision"). A deep neural network was then trained to convert the visual information into appropriate actions, such as moving, kicking, or passing the ball.
By rewarding the robot when it performed well and penalizing it when it made mistakes, the neural network gradually learned the best strategies for playing soccer. This allowed the robot to develop agile soccer skills, like dribbling, passing, and shooting, without needing any pre-programmed instructions.
The researchers believe this approach could be applied to other robotics challenges, where it's difficult to anticipate all the possible situations a robot might encounter. By letting the robot learn from experience, it can adapt and become more capable in complex, real-world environments.
Technical Explanation
The researchers developed a simulation environment to train a bipedal robot to play soccer using deep reinforcement learning. The robot was equipped with an egocentric vision system, which provided a first-person perspective of the soccer field and ball. This visual input was then processed by a deep neural network that learned to map the observations to the appropriate actions, such as moving, kicking, or passing the ball.
To train the neural network, the researchers used a reinforcement learning algorithm. The robot was rewarded for successful soccer plays, like scoring goals or maintaining possession of the ball, and penalized for mistakes, like losing the ball or colliding with obstacles. By repeatedly experiencing these rewards and penalties, the neural network gradually learned the optimal strategies for playing soccer.
The researchers tested their approach in the simulation environment and found that the robot was able to learn a variety of agile soccer skills, including dribbling, passing, and shooting. The neural network's performance improved over time as it accumulated more experience playing soccer.
The researchers also compared their deep reinforcement learning approach to a more traditional, manually-programmed approach for robot soccer. They found that the deep learning method was able to achieve better performance and more robust behaviors, as it was not limited by the pre-defined rules and strategies programmed by the researchers.
Critical Analysis
The research presented in this paper demonstrates the potential of deep reinforcement learning for enabling robots to learn complex, real-world skills like soccer. By allowing the robot to learn from its own experiences, rather than relying on pre-programmed behaviors, the approach can lead to more adaptable and capable robotic systems.
However, the paper does not fully address the potential challenges and limitations of this approach. For example, the simulation environment used in the experiments may not fully capture the complexity and uncertainties of the real world, which could make it difficult to transfer the learned skills to a physical robot. Additionally, the paper does not discuss the computational and data requirements of the deep reinforcement learning approach, which could be significant and limit its practical applicability.
Furthermore, the paper does not explore the potential ethical and social implications of developing robots with advanced soccer skills. As these technologies become more capable, it will be important to consider how they might be used and the potential impacts on human players and the sport of soccer.
Overall, the research presented in this paper is a promising step towards enabling robots to learn complex skills through deep reinforcement learning. However, more work is needed to address the practical and ethical challenges before this approach can be widely deployed in real-world applications.
Conclusion
This paper describes a deep reinforcement learning approach to teaching a bipedal robot how to play soccer from an egocentric (first-person) perspective. By creating a simulation environment and training a deep neural network to convert visual inputs into appropriate actions, the researchers were able to enable the robot to learn a variety of agile soccer skills, such as dribbling, passing, and shooting.
The key advantage of this approach is that it allows the robot to learn these skills through trial and error, without relying on pre-programmed behaviors or external sensors. This could make the robot more adaptable and capable in complex, real-world environments.
While the research demonstrates the potential of deep reinforcement learning for robotics, it also raises some important questions and challenges, such as the difficulty of transferring simulated skills to the physical world and the potential ethical implications of advanced robotic soccer players. Nonetheless, this work represents an important step forward in the field of robot learning and could have broader applications beyond the specific domain of soccer.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
Dhruva Tirumala, Markus Wulfmeier, Ben Moran, Sandy Huang, Jan Humplik, Guy Lever, Tuomas Haarnoja, Leonard Hasenclever, Arunkumar Byravan, Nathan Batchelor, Neil Sreendra, Kushal Patel, Marlon Gwira, Francesco Nori, Martin Riedmiller, Nicolas Heess
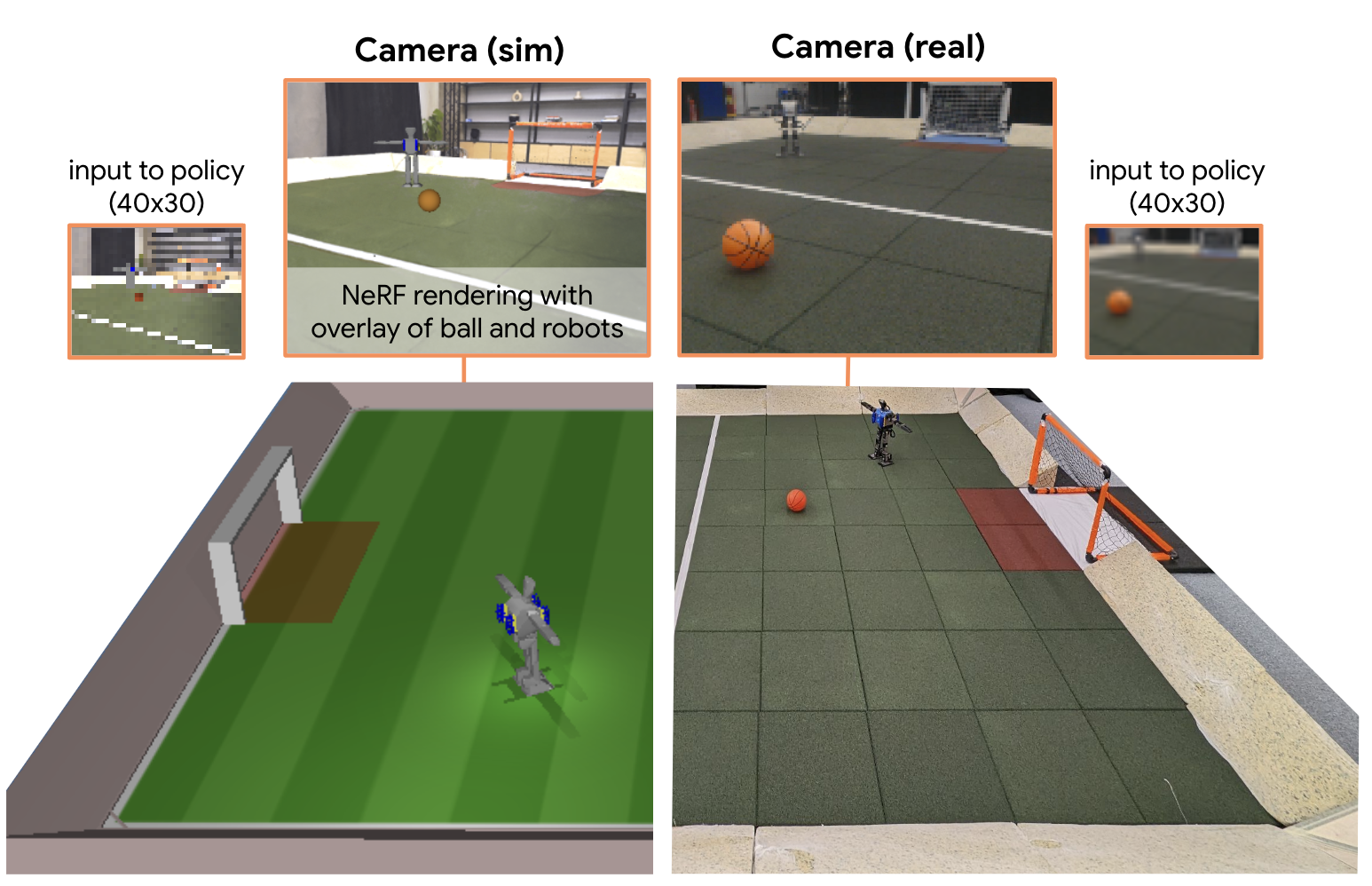
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Read more5/7/2024
🤿
9
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Tuomas Haarnoja, Ben Moran, Guy Lever, Sandy H. Huang, Dhruva Tirumala, Jan Humplik, Markus Wulfmeier, Saran Tunyasuvunakool, Noah Y. Siegel, Roland Hafner, Michael Bloesch, Kristian Hartikainen, Arunkumar Byravan, Leonard Hasenclever, Yuval Tassa, Fereshteh Sadeghi, Nathan Batchelor, Federico Casarini, Stefano Saliceti, Charles Game, Neil Sreendra, Kushal Patel, Marlon Gwira, Andrea Huber, Nicole Hurley, Francesco Nori, Raia Hadsell, Nicolas Heess
We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. The resulting agent exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and it transitions between them in a smooth, stable, and efficient manner. The agent's locomotion and tactical behavior adapts to specific game contexts in a way that would be impractical to manually design. The agent also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. Our agent was trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer. Although the robots are inherently fragile, basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way -- well beyond what is intuitively expected from the robot. Indeed, in experiments, they walked 181% faster, turned 302% faster, took 63% less time to get up, and kicked a ball 34% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives.
Read more4/12/2024

0
RobocupGym: A challenging continuous control benchmark in Robocup
Michael Beukman, Branden Ingram, Geraud Nangue Tasse, Benjamin Rosman, Pravesh Ranchod
Reinforcement learning (RL) has progressed substantially over the past decade, with much of this progress being driven by benchmarks. Many benchmarks are focused on video or board games, and a large number of robotics benchmarks lack diversity and real-world applicability. In this paper, we aim to simplify the process of applying reinforcement learning in the 3D simulation league of Robocup, a robotic football competition. To this end, we introduce a Robocup-based RL environment based on the open source rcssserver3d soccer server, simple pre-defined tasks, and integration with a popular RL library, Stable Baselines 3. Our environment enables the creation of high-dimensional continuous control tasks within a robotics football simulation. In each task, an RL agent controls a simulated Nao robot, and can interact with the ball or other agents. We open-source our environment and training code at https://github.com/Michael-Beukman/RobocupGym.
Read more7/23/2024

0
LLCoach: Generating Robot Soccer Plans using Multi-Role Large Language Models
Michele Brienza, Emanuele Musumeci, Vincenzo Suriani, Daniele Affinita, Andrea Pennisi, Daniele Nardi, Domenico Daniele Bloisi
The deployment of robots into human scenarios necessitates advanced planning strategies, particularly when we ask robots to operate in dynamic, unstructured environments. RoboCup offers the chance to deploy robots in one of those scenarios, a human-shaped game represented by a soccer match. In such scenarios, robots must operate using predefined behaviors that can fail in unpredictable conditions. This paper introduces a novel application of Large Language Models (LLMs) to address the challenge of generating actionable plans in such settings, specifically within the context of the RoboCup Standard Platform League (SPL) competitions where robots are required to autonomously execute soccer strategies that emerge from the interactions of individual agents. In particular, we propose a multi-role approach leveraging the capabilities of LLMs to generate and refine plans for a robotic soccer team. The potential of the proposed method is demonstrated through an experimental evaluation,carried out simulating multiple matches where robots with AI-generated plans play against robots running human-built code.
Read more6/27/2024