RobocupGym: A challenging continuous control benchmark in Robocup

0

Sign in to get full access
Overview
- RobocupGym is a challenging continuous control benchmark for Robocup, a robotics competition focused on soccer.
- The benchmark tests an agent's ability to control a bipedal robot to play soccer in a realistic environment with complex dynamics.
- The goal is to develop advanced reinforcement learning and control algorithms that can enable robust and agile soccer skills for autonomous robots.
Plain English Explanation
RobocupGym is a new benchmark for testing the capabilities of reinforcement learning and control algorithms in the context of robotic soccer. The goal is to simulate a realistic soccer environment with a bipedal robot that must learn to control its movements to dribble, pass, and shoot the ball effectively.
The benchmark presents several challenges that make it difficult for existing AI systems. The robot has to maintain balance and coordination while navigating the dynamic environment of a soccer pitch, which involves reacting to the ball's movements, other players, and complex physics. Developing robust and agile control policies that can handle these challenges is a key objective of the RobocupGym benchmark.
By providing this realistic and challenging testbed, the researchers hope to drive progress in areas like learning agile soccer skills, integrating deep reinforcement learning with low-level control, and adaptive reinforcement learning for robot control. Advances in these areas could lead to significant improvements in the performance and capabilities of autonomous soccer-playing robots.
Technical Explanation
The RobocupGym benchmark is designed to assess an agent's ability to control a bipedal robot in a realistic soccer environment. The environment is based on the Robocup soccer simulation, which models the complex dynamics of a soccer game, including the ball, other players, and the robot's interaction with the environment.
The benchmark presents several challenging tasks, such as dribbling the ball, passing to teammates, and shooting on goal. The agent must learn to coordinate the robot's balance, movements, and interactions with the ball and other objects to perform these soccer skills effectively. The benchmark also includes additional challenges, such as dealing with sensor noise, occlusions, and dynamic obstacles.
To evaluate the agent's performance, the benchmark provides various metrics, such as the ability to control the ball, pass accuracy, and goal-scoring rate. These metrics are designed to measure the agent's ability to learn robust and agile soccer skills that can be transferred to real-world robotic systems.
The RobocupGym benchmark is intended to drive progress in areas like learning robot soccer from egocentric vision, robust reinforcement learning, and integrating deep reinforcement learning with low-level control. Advances in these areas could lead to significant improvements in the performance and capabilities of autonomous soccer-playing robots.
Critical Analysis
The RobocupGym benchmark provides a valuable testbed for evaluating the capabilities of reinforcement learning and control algorithms in the context of robotic soccer. However, the complexity of the environment and the high-dimensional state space of the bipedal robot may present significant challenges for current AI systems.
While the benchmark aims to simulate a realistic soccer environment, there may be limitations in how well the simulation captures the full complexity of real-world physics and dynamics. Additionally, the benchmark focuses on a specific task (i.e., playing soccer), which may limit the generalizability of the learned skills to other robotic applications.
Further research may be needed to address issues like robustness to sensor noise and occlusions, safe exploration and learning, and the integration of high-level decision-making with low-level control. Addressing these challenges could lead to more versatile and reliable autonomous soccer-playing robots.
Conclusion
The RobocupGym benchmark presents a challenging continuous control problem that can drive progress in areas like reinforcement learning, robot control, and multi-agent coordination. By providing a realistic and complex soccer environment, the benchmark aims to spur the development of advanced algorithms that can enable robust and agile soccer skills for autonomous robots.
The insights and techniques gained from addressing the challenges posed by the RobocupGym benchmark could have broader implications for the field of robotics, potentially leading to more capable and versatile robotic systems that can operate in dynamic and unstructured environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RobocupGym: A challenging continuous control benchmark in Robocup
Michael Beukman, Branden Ingram, Geraud Nangue Tasse, Benjamin Rosman, Pravesh Ranchod
Reinforcement learning (RL) has progressed substantially over the past decade, with much of this progress being driven by benchmarks. Many benchmarks are focused on video or board games, and a large number of robotics benchmarks lack diversity and real-world applicability. In this paper, we aim to simplify the process of applying reinforcement learning in the 3D simulation league of Robocup, a robotic football competition. To this end, we introduce a Robocup-based RL environment based on the open source rcssserver3d soccer server, simple pre-defined tasks, and integration with a popular RL library, Stable Baselines 3. Our environment enables the creation of high-dimensional continuous control tasks within a robotics football simulation. In each task, an RL agent controls a simulated Nao robot, and can interact with the ball or other agents. We open-source our environment and training code at https://github.com/Michael-Beukman/RobocupGym.
Read more7/23/2024
0
Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
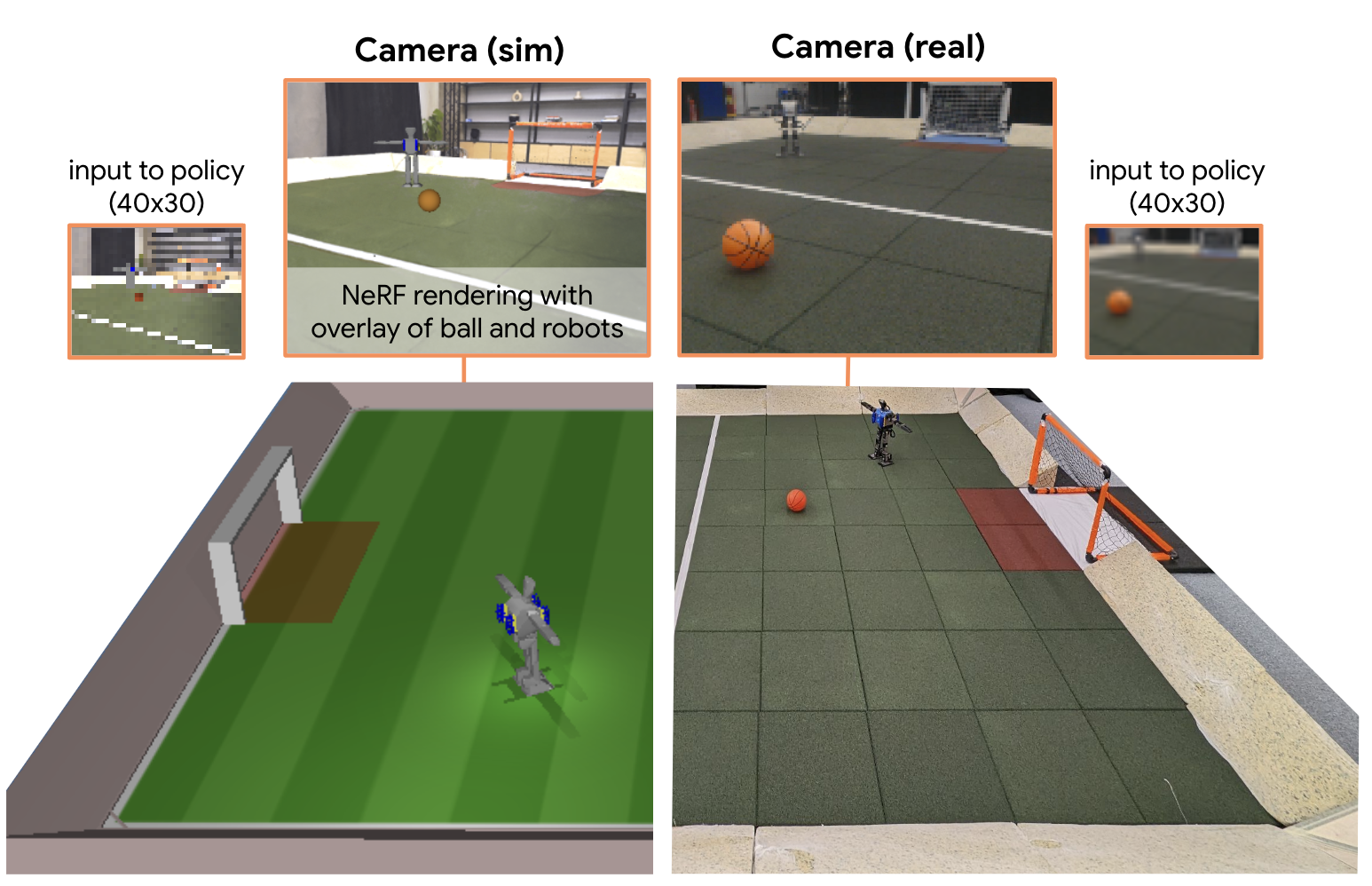
Dhruva Tirumala, Markus Wulfmeier, Ben Moran, Sandy Huang, Jan Humplik, Guy Lever, Tuomas Haarnoja, Leonard Hasenclever, Arunkumar Byravan, Nathan Batchelor, Neil Sreendra, Kushal Patel, Marlon Gwira, Francesco Nori, Martin Riedmiller, Nicolas Heess
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Read more5/7/2024
0
RRLS : Robust Reinforcement Learning Suite
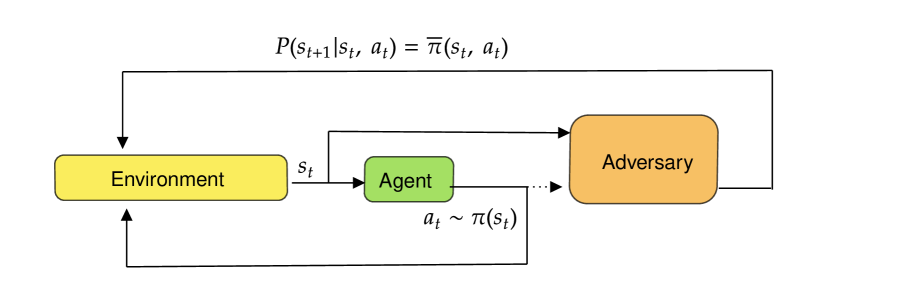
Adil Zouitine, David Bertoin, Pierre Clavier, Matthieu Geist, Emmanuel Rachelson
Robust reinforcement learning is the problem of learning control policies that provide optimal worst-case performance against a span of adversarial environments. It is a crucial ingredient for deploying algorithms in real-world scenarios with prevalent environmental uncertainties and has been a long-standing object of attention in the community, without a standardized set of benchmarks. This contribution endeavors to fill this gap. We introduce the Robust Reinforcement Learning Suite (RRLS), a benchmark suite based on Mujoco environments. RRLS provides six continuous control tasks with two types of uncertainty sets for training and evaluation. Our benchmark aims to standardize robust reinforcement learning tasks, facilitating reproducible and comparable experiments, in particular those from recent state-of-the-art contributions, for which we demonstrate the use of RRLS. It is also designed to be easily expandable to new environments. The source code is available at href{https://github.com/SuReLI/RRLS}{https://github.com/SuReLI/RRLS}.
Read more6/13/2024
🤿
9
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Tuomas Haarnoja, Ben Moran, Guy Lever, Sandy H. Huang, Dhruva Tirumala, Jan Humplik, Markus Wulfmeier, Saran Tunyasuvunakool, Noah Y. Siegel, Roland Hafner, Michael Bloesch, Kristian Hartikainen, Arunkumar Byravan, Leonard Hasenclever, Yuval Tassa, Fereshteh Sadeghi, Nathan Batchelor, Federico Casarini, Stefano Saliceti, Charles Game, Neil Sreendra, Kushal Patel, Marlon Gwira, Andrea Huber, Nicole Hurley, Francesco Nori, Raia Hadsell, Nicolas Heess
We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. The resulting agent exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and it transitions between them in a smooth, stable, and efficient manner. The agent's locomotion and tactical behavior adapts to specific game contexts in a way that would be impractical to manually design. The agent also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. Our agent was trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer. Although the robots are inherently fragile, basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way -- well beyond what is intuitively expected from the robot. Indeed, in experiments, they walked 181% faster, turned 302% faster, took 63% less time to get up, and kicked a ball 34% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives.
Read more4/12/2024