Learning Sparse Codes with Entropy-Based ELBOs
2311.01888
0
0
✨
Abstract
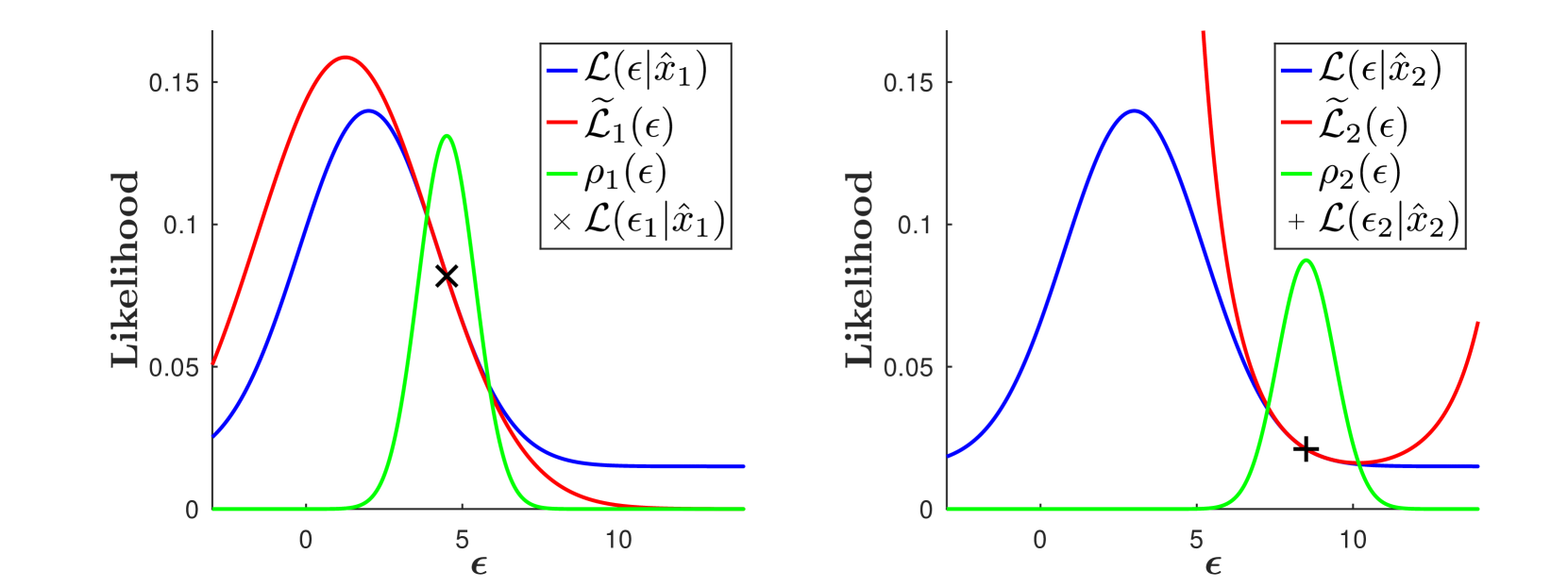
Standard probabilistic sparse coding assumes a Laplace prior, a linear mapping from latents to observables, and Gaussian observable distributions. We here derive a solely entropy-based learning objective for the parameters of standard sparse coding. The novel variational objective has the following features: (A) unlike MAP approximations, it uses non-trivial posterior approximations for probabilistic inference; (B) unlike for previous non-trivial approximations, the novel objective is fully analytical; and (C) the objective allows for a novel principled form of annealing. The objective is derived by first showing that the standard ELBO objective converges to a sum of entropies, which matches similar recent results for generative models with Gaussian priors. The conditions under which the ELBO becomes equal to entropies are then shown to have analytical solutions, which leads to the fully analytical objective. Numerical experiments are used to demonstrate the feasibility of learning with such entropy-based ELBOs. We investigate different posterior approximations including Gaussians with correlated latents and deep amortized approximations. Furthermore, we numerically investigate entropy-based annealing which results in improved learning. Our main contributions are theoretical, however, and they are twofold: (1) for non-trivial posterior approximations, we provide the (to the knowledge of the authors) first analytical ELBO objective for standard probabilistic sparse coding; and (2) we provide the first demonstration on how a recently shown convergence of the ELBO to entropy sums can be used for learning.
Create account to get full access
Overview
- This paper introduces a novel, fully analytical objective function for learning the parameters of standard probabilistic sparse coding models.
- The objective is derived by showing that the standard evidence lower bound (ELBO) objective converges to a sum of entropies, which can then be optimized directly.
- The new objective has several key advantages over previous approaches, including the use of non-trivial posterior approximations and a novel form of annealing.
- The authors demonstrate the feasibility of learning with this entropy-based ELBO through numerical experiments.
Plain English Explanation
Probabilistic sparse coding is a machine learning technique that aims to represent data using a small number of important features or "latent variables." [https://aimodels.fyi/papers/arxiv/towards-generalized-entropic-sparsification-convolutional-neural-networks] This is often done by assuming a Laplace prior distribution on the latent variables and a linear mapping to the observable data.
The paper introduces a new way to learn the parameters of this sparse coding model, based solely on maximizing the entropy of the latent variable distributions. [https://aimodels.fyi/papers/arxiv/sparse-concept-bottleneck-models-gumbel-tricks-contrastive] This is different from the typical approach, which uses an approximate inference method called the evidence lower bound (ELBO).
The key advantages of this entropy-based approach are:
- It can use more complex, "non-trivial" approximations of the posterior distribution, unlike previous ELBO-based methods.
- The new objective is fully analytical, meaning it can be optimized efficiently.
- It allows for a novel form of "annealing," which can improve the learning process.
The authors demonstrate the feasibility of this approach through numerical experiments, exploring different ways of approximating the posterior distribution, including using deep neural networks. [https://aimodels.fyi/papers/arxiv/bayesian-inference-consistent-predictions-overparameterized-nonlinear-regression] They also show that the entropy-based annealing can lead to better learning outcomes.
Technical Explanation
The paper starts by noting that standard probabilistic sparse coding assumes a Laplace prior on the latent variables, a linear mapping to the observables, and Gaussian observable distributions. The authors then derive a novel, entropy-based learning objective for the model parameters.
The key steps are:
- The authors show that the standard ELBO objective converges to a sum of entropies, similar to recent results for generative models with Gaussian priors. [https://aimodels.fyi/papers/arxiv/mathematical-theory-learning-semantic-languages-by-abstract]
- They then find the conditions under which the ELBO becomes equal to these entropies, and derive an analytical solution for the objective.
- This results in a fully analytical entropy-based objective function that can be optimized directly.
The authors test this new objective through numerical experiments, exploring different posterior approximations, including Gaussians with correlated latents and deep amortized approximations. They also investigate the effects of entropy-based annealing, which can improve the learning process.
Critical Analysis
The main strengths of this work are the theoretical insights and the demonstration of a novel, fully analytical objective function for probabilistic sparse coding. The authors show how the ELBO can be reformulated in terms of entropies, leading to an efficient optimization procedure.
One potential limitation is the focus on the standard sparse coding model, which may not capture all the complexities of real-world data. It would be interesting to see if the entropy-based approach can be extended to more sophisticated sparse coding or generative modeling frameworks.
Additionally, while the numerical experiments are promising, more extensive testing on larger-scale problems and real-world datasets would be helpful to fully assess the practical benefits of this approach. [https://aimodels.fyi/papers/arxiv/from-latent-dynamics-to-meaningful-representations]
Overall, this paper represents an interesting theoretical contribution that opens up new avenues for research in sparse coding and probabilistic modeling. The entropy-based perspective could inspire further developments in this area.
Conclusion
This paper introduces a novel, entropy-based objective function for learning the parameters of standard probabilistic sparse coding models. The key advantages of this approach are the use of non-trivial posterior approximations, the analytical nature of the objective, and the ability to perform principled annealing.
The authors demonstrate the feasibility of this approach through numerical experiments, exploring different posterior approximations and the effects of entropy-based annealing. While the focus is on the standard sparse coding model, the theoretical insights and the fully analytical objective function represent an important contribution to the field of probabilistic modeling and sparse representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
On the Convergence of the ELBO to Entropy Sums
Jorg Lucke, Jan Warnken
0
0
The variational lower bound (a.k.a. ELBO or free energy) is the central objective for many established as well as many novel algorithms for unsupervised learning. During learning such algorithms change model parameters to increase the variational lower bound. Learning usually proceeds until parameters have converged to values close to a stationary point of the learning dynamics. In this purely theoretical contribution, we show that (for a very large class of generative models) the variational lower bound is at all stationary points of learning equal to a sum of entropies. For standard machine learning models with one set of latents and one set of observed variables, the sum consists of three entropies: (A) the (average) entropy of the variational distributions, (B) the negative entropy of the model's prior distribution, and (C) the (expected) negative entropy of the observable distribution. The obtained result applies under realistic conditions including: finite numbers of data points, at any stationary point (including saddle points) and for any family of (well behaved) variational distributions. The class of generative models for which we show the equality to entropy sums contains many well-known generative models. As concrete examples we discuss Sigmoid Belief Networks, probabilistic PCA and (Gaussian and non-Gaussian) mixture models. The result also applies for standard (Gaussian) variational autoencoders, a special case that has been shown previously (Damm et al., 2023). The prerequisites we use to show equality to entropy sums are relatively mild. Concretely, the distributions of a given generative model have to be of the exponential family, and the model has to satisfy a parameterization criterion (which is usually fulfilled). Proving the equality of the ELBO to entropy sums at stationary points (under the stated conditions) is the main contribution of this work.
4/30/2024
Analytical Approximation of the ELBO Gradient in the Context of the Clutter Problem
Roumen Nikolaev Popov
0
0
We propose an analytical solution for approximating the gradient of the Evidence Lower Bound (ELBO) in variational inference problems where the statistical model is a Bayesian network consisting of observations drawn from a mixture of a Gaussian distribution embedded in unrelated clutter, known as the clutter problem. The method employs the reparameterization trick to move the gradient operator inside the expectation and relies on the assumption that, because the likelihood factorizes over the observed data, the variational distribution is generally more compactly supported than the Gaussian distribution in the likelihood factors. This allows efficient local approximation of the individual likelihood factors, which leads to an analytical solution for the integral defining the gradient expectation. We integrate the proposed gradient approximation as the expectation step in an EM (Expectation Maximization) algorithm for maximizing ELBO and test against classical deterministic approaches in Bayesian inference, such as the Laplace approximation, Expectation Propagation and Mean-Field Variational Inference. The proposed method demonstrates good accuracy and rate of convergence together with linear computational complexity.
5/8/2024
🛸
Leveraging joint sparsity in hierarchical Bayesian learning
Jan Glaubitz, Anne Gelb
0
0
We present a hierarchical Bayesian learning approach to infer jointly sparse parameter vectors from multiple measurement vectors. Our model uses separate conditionally Gaussian priors for each parameter vector and common gamma-distributed hyper-parameters to enforce joint sparsity. The resulting joint-sparsity-promoting priors are combined with existing Bayesian inference methods to generate a new family of algorithms. Our numerical experiments, which include a multi-coil magnetic resonance imaging application, demonstrate that our new approach consistently outperforms commonly used hierarchical Bayesian methods.
5/27/2024
How to train your VAE
Mariano Rivera
0
0
Variational Autoencoders (VAEs) have become a cornerstone in generative modeling and representation learning within machine learning. This paper explores a nuanced aspect of VAEs, focusing on interpreting the Kullback-Leibler (KL) Divergence, a critical component within the Evidence Lower Bound (ELBO) that governs the trade-off between reconstruction accuracy and regularization. Meanwhile, the KL Divergence enforces alignment between latent variable distributions and a prior imposing a structure on the overall latent space but leaves individual variable distributions unconstrained. The proposed method redefines the ELBO with a mixture of Gaussians for the posterior probability, introduces a regularization term to prevent variance collapse, and employs a PatchGAN discriminator to enhance texture realism. Implementation details involve ResNetV2 architectures for both the Encoder and Decoder. The experiments demonstrate the ability to generate realistic faces, offering a promising solution for enhancing VAE-based generative models.
6/26/2024