On the Convergence of the ELBO to Entropy Sums
2209.03077
0
0
🏷️
Abstract
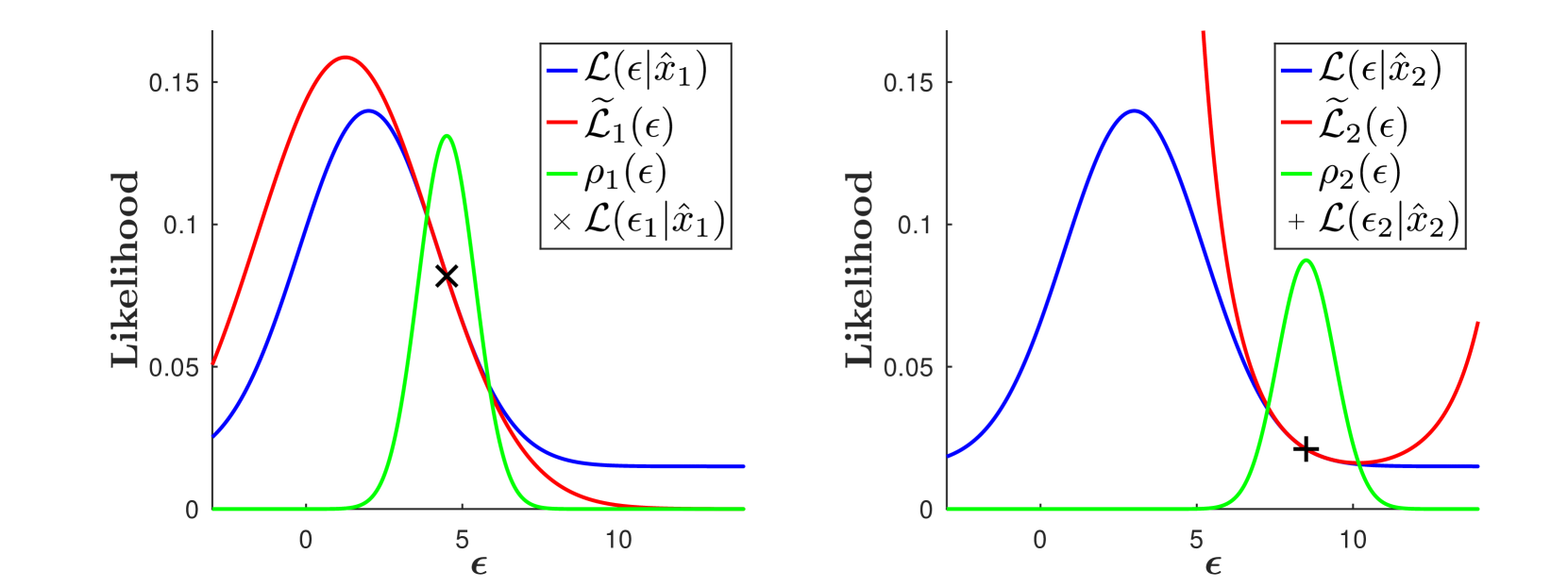
The variational lower bound (a.k.a. ELBO or free energy) is the central objective for many established as well as many novel algorithms for unsupervised learning. During learning such algorithms change model parameters to increase the variational lower bound. Learning usually proceeds until parameters have converged to values close to a stationary point of the learning dynamics. In this purely theoretical contribution, we show that (for a very large class of generative models) the variational lower bound is at all stationary points of learning equal to a sum of entropies. For standard machine learning models with one set of latents and one set of observed variables, the sum consists of three entropies: (A) the (average) entropy of the variational distributions, (B) the negative entropy of the model's prior distribution, and (C) the (expected) negative entropy of the observable distribution. The obtained result applies under realistic conditions including: finite numbers of data points, at any stationary point (including saddle points) and for any family of (well behaved) variational distributions. The class of generative models for which we show the equality to entropy sums contains many well-known generative models. As concrete examples we discuss Sigmoid Belief Networks, probabilistic PCA and (Gaussian and non-Gaussian) mixture models. The result also applies for standard (Gaussian) variational autoencoders, a special case that has been shown previously (Damm et al., 2023). The prerequisites we use to show equality to entropy sums are relatively mild. Concretely, the distributions of a given generative model have to be of the exponential family, and the model has to satisfy a parameterization criterion (which is usually fulfilled). Proving the equality of the ELBO to entropy sums at stationary points (under the stated conditions) is the main contribution of this work.
Create account to get full access
Overview
- The paper focuses on the variational lower bound (ELBO or free energy), which is a key objective for many machine learning algorithms.
- The authors show that for a broad class of generative models, the ELBO at stationary points of the learning dynamics is equal to a sum of entropies.
- This result applies to various models, including Sigmoid Belief Networks, probabilistic PCA, Gaussian and non-Gaussian mixture models, and Gaussian variational autoencoders.
Plain English Explanation
The variational lower bound, also known as the ELBO or free energy, is a fundamental concept in unsupervised machine learning. It's a mathematical expression that measures how well a model is able to describe the observed data. Many machine learning algorithms, both established and novel, aim to maximize this ELBO during the learning process.
The authors of this paper have made a significant theoretical contribution by showing that for a wide range of generative models, the ELBO is equal to a sum of entropies at the stationary points of the learning process. Entropy is a measure of uncertainty or unpredictability, and the authors have found that the ELBO can be broken down into three entropy-related terms:
- The average entropy of the variational distributions, which represents the uncertainty in the model's latent variables.
- The negative entropy of the model's prior distribution, which reflects the inherent structure or patterns in the model.
- The expected negative entropy of the observable distribution, which captures the uncertainty in the observed data.
This result holds true for a wide range of generative models, including Sigmoid Belief Networks, probabilistic PCA, and Gaussian and non-Gaussian mixture models. It also applies to the popular Gaussian variational autoencoder, a special case that was previously shown.
The authors' main contribution is proving this equality between the ELBO and the sum of entropies under relatively mild conditions, such as the distributions being in the exponential family and the model satisfying a specific parameterization criterion.
Technical Explanation
The paper shows that for a broad class of generative models, the variational lower bound (ELBO) is equal to a sum of entropies at the stationary points of the learning dynamics. This result holds true under realistic conditions, including finite datasets and for any family of well-behaved variational distributions.
The class of generative models covered includes many well-known models, such as Sigmoid Belief Networks, probabilistic PCA, and Gaussian and non-Gaussian mixture models. The authors also demonstrate that the result applies to the standard Gaussian variational autoencoder, a special case that was previously established.
The key prerequisites for this equality to hold are that the distributions of the generative model must be in the exponential family and the model must satisfy a specific parameterization criterion, which is typically fulfilled.
The authors prove that at the stationary points of the learning process, the ELBO can be decomposed into three entropy-related terms: the average entropy of the variational distributions, the negative entropy of the model's prior distribution, and the expected negative entropy of the observable distribution.
This theoretical result provides a deeper understanding of the ELBO and its relationship to the underlying uncertainty and structure of the generative model. It has implications for the interpretation and analysis of unsupervised learning algorithms that optimize the ELBO.
Critical Analysis
The authors have provided a rigorous theoretical analysis of the variational lower bound (ELBO) and its relationship to entropy at the stationary points of the learning dynamics. The result is quite general, applying to a broad class of generative models, which strengthens the significance of the findings.
One potential limitation of the paper is that the analysis is purely theoretical and does not include any empirical validation or experiments. While the theoretical insights are valuable, it would be interesting to see how the entropy decomposition of the ELBO manifests in practical applications and whether it can provide additional insights or guide the development of more effective learning algorithms.
Furthermore, the paper focuses on the stationary points of the learning dynamics, which may not capture the full picture of the learning process. It would be informative to understand how the ELBO and its entropy components evolve during the entire course of learning, particularly in the transient phase before convergence.
Another area for further research could be examining the implications of this entropy-based ELBO decomposition for model interpretability and the ability to extract meaningful insights about the underlying generative process. The connection between information theory and machine learning uncertainty could be an interesting direction to explore.
Overall, the authors have made a valuable contribution to the theoretical understanding of the variational lower bound and its relationship to entropy in generative models. The findings provide a solid foundation for further investigations into the interpretability and optimization of unsupervised learning algorithms.
Conclusion
This paper presents a significant theoretical result, showing that for a broad class of generative models, the variational lower bound (ELBO) is equal to a sum of entropies at the stationary points of the learning dynamics. This deepens our understanding of the ELBO and its connection to the underlying uncertainty and structure of the models.
The authors' proof applies to a wide range of well-known generative models, including Sigmoid Belief Networks, probabilistic PCA, and Gaussian and non-Gaussian mixture models. The result also extends to the popular Gaussian variational autoencoder, a special case that was previously established.
The theoretical insights provided in this paper have the potential to inform the development of more effective and interpretable unsupervised learning algorithms. By understanding the entropy-based decomposition of the ELBO, researchers and practitioners may be able to gain better insights into the learning process and design models that capture the essential patterns and uncertainties in the data more accurately.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Learning Sparse Codes with Entropy-Based ELBOs
Dmytro Velychko, Simon Damm, Asja Fischer, Jorg Lucke
0
0
Standard probabilistic sparse coding assumes a Laplace prior, a linear mapping from latents to observables, and Gaussian observable distributions. We here derive a solely entropy-based learning objective for the parameters of standard sparse coding. The novel variational objective has the following features: (A) unlike MAP approximations, it uses non-trivial posterior approximations for probabilistic inference; (B) unlike for previous non-trivial approximations, the novel objective is fully analytical; and (C) the objective allows for a novel principled form of annealing. The objective is derived by first showing that the standard ELBO objective converges to a sum of entropies, which matches similar recent results for generative models with Gaussian priors. The conditions under which the ELBO becomes equal to entropies are then shown to have analytical solutions, which leads to the fully analytical objective. Numerical experiments are used to demonstrate the feasibility of learning with such entropy-based ELBOs. We investigate different posterior approximations including Gaussians with correlated latents and deep amortized approximations. Furthermore, we numerically investigate entropy-based annealing which results in improved learning. Our main contributions are theoretical, however, and they are twofold: (1) for non-trivial posterior approximations, we provide the (to the knowledge of the authors) first analytical ELBO objective for standard probabilistic sparse coding; and (2) we provide the first demonstration on how a recently shown convergence of the ELBO to entropy sums can be used for learning.
4/11/2024
Analytical Approximation of the ELBO Gradient in the Context of the Clutter Problem
Roumen Nikolaev Popov
0
0
We propose an analytical solution for approximating the gradient of the Evidence Lower Bound (ELBO) in variational inference problems where the statistical model is a Bayesian network consisting of observations drawn from a mixture of a Gaussian distribution embedded in unrelated clutter, known as the clutter problem. The method employs the reparameterization trick to move the gradient operator inside the expectation and relies on the assumption that, because the likelihood factorizes over the observed data, the variational distribution is generally more compactly supported than the Gaussian distribution in the likelihood factors. This allows efficient local approximation of the individual likelihood factors, which leads to an analytical solution for the integral defining the gradient expectation. We integrate the proposed gradient approximation as the expectation step in an EM (Expectation Maximization) algorithm for maximizing ELBO and test against classical deterministic approaches in Bayesian inference, such as the Laplace approximation, Expectation Propagation and Mean-Field Variational Inference. The proposed method demonstrates good accuracy and rate of convergence together with linear computational complexity.
5/8/2024
How to train your VAE
Mariano Rivera
0
0
Variational Autoencoders (VAEs) have become a cornerstone in generative modeling and representation learning within machine learning. This paper explores a nuanced aspect of VAEs, focusing on interpreting the Kullback-Leibler (KL) Divergence, a critical component within the Evidence Lower Bound (ELBO) that governs the trade-off between reconstruction accuracy and regularization. Meanwhile, the KL Divergence enforces alignment between latent variable distributions and a prior imposing a structure on the overall latent space but leaves individual variable distributions unconstrained. The proposed method redefines the ELBO with a mixture of Gaussians for the posterior probability, introduces a regularization term to prevent variance collapse, and employs a PatchGAN discriminator to enhance texture realism. Implementation details involve ResNetV2 architectures for both the Encoder and Decoder. The experiments demonstrate the ability to generate realistic faces, offering a promising solution for enhancing VAE-based generative models.
6/26/2024
🤔
Variational inference, Mixture of Gaussians, Bayesian Machine Learning
Tom Huix, Anna Korba, Alain Durmus, Eric Moulines
0
0
Variational inference (VI) is a popular approach in Bayesian inference, that looks for the best approximation of the posterior distribution within a parametric family, minimizing a loss that is typically the (reverse) Kullback-Leibler (KL) divergence. Despite its empirical success, the theoretical properties of VI have only received attention recently, and mostly when the parametric family is the one of Gaussians. This work aims to contribute to the theoretical study of VI in the non-Gaussian case by investigating the setting of Mixture of Gaussians with fixed covariance and constant weights. In this view, VI over this specific family can be casted as the minimization of a Mollified relative entropy, i.e. the KL between the convolution (with respect to a Gaussian kernel) of an atomic measure supported on Diracs, and the target distribution. The support of the atomic measure corresponds to the localization of the Gaussian components. Hence, solving variational inference becomes equivalent to optimizing the positions of the Diracs (the particles), which can be done through gradient descent and takes the form of an interacting particle system. We study two sources of error of variational inference in this context when optimizing the mollified relative entropy. The first one is an optimization result, that is a descent lemma establishing that the algorithm decreases the objective at each iteration. The second one is an approximation error, that upper bounds the objective between an optimal finite mixture and the target distribution.
6/11/2024