Learning Spatially-Aware Language and Audio Embedding

0
💬
Sign in to get full access
Overview
- This paper explores the potential of large language models to understand and reason about spatial audio information.
- The researchers investigate how well these models can learn to link language to spatial audio cues and infer properties of spatial environments from audio alone.
- The findings have implications for audio-text retrieval and spatial sound reasoning in areas like robotics, virtual reality, and accessibility.
Plain English Explanation
Large language models, like those used in chatbots and text generation, have become remarkably capable at understanding and generating human language. However, these models typically focus on text-based information, without much understanding of the physical world.
This research explores whether these language models can also learn to reason about spatial audio information - the sounds that occur in 3D environments and convey information about the size, shape, and contents of a space. For example, the echoes and reverberation of a sound in a small bathroom versus a large cathedral provide cues about the physical environment.
The researchers investigate if language models can link language to these spatial audio cues - so they can understand and describe what an environment might sound like. They also test whether the models can infer properties of spatial environments from audio alone, without any visual information.
Being able to understand spatial audio could have important applications. For example, it could improve audio-text retrieval - allowing users to search for and find relevant audio clips based on descriptive language. It could also enable spatial sound reasoning for robots or virtual assistants, helping them better navigate and interact with 3D environments through sound cues.
Technical Explanation
The paper presents several experiments to assess how well large language models can learn to reason about spatial audio information.
In the first set of experiments, the researchers trained language models to learn a joint embedding space linking textual descriptions of spatial environments to simulated audio recordings of those environments. This allowed the models to associate language with relevant spatial audio cues.
The second experiment tested whether the trained models could infer properties of unseen spatial environments based solely on audio information, without any visual input. The models were able to accurately predict attributes like room size, wall materials, and object placements.
Finally, the researchers evaluated the models' performance on audio-text retrieval tasks, showing they could match textual descriptions to corresponding spatial audio clips.
The results suggest large language models have significant potential to understand and reason about spatial audio, which could enable new capabilities in areas like robotic navigation, virtual environments, and accessibility for the visually impaired.
Critical Analysis
The paper presents promising initial findings, but also acknowledges several limitations and areas for further research.
One key caveat is that the experiments relied on simulated spatial audio data, rather than recordings of real-world environments. While the simulations aimed to be realistic, there may be important differences in how language models handle authentic spatial audio cues.
Additionally, the test environments were relatively simple - mostly empty rooms with a few basic objects. More complex, cluttered spaces may pose greater challenges for the models to infer spatial properties from audio alone.
The paper also does not explore how well the language models' spatial audio understanding would transfer to real-world applications. Further research is needed to assess their performance in tasks like robotic navigation or audio-based virtual environments.
Finally, while the audio-text retrieval results are promising, the paper does not address potential biases or limitations in the models' language understanding that could impact the reliability of these systems for practical use cases.
Overall, the research demonstrates an interesting first step, but significant work remains to realize the full potential of language models for spatial audio reasoning in real-world settings.
Conclusion
This paper investigates the ability of large language models to understand and reason about spatial audio information. The findings suggest these models can learn to associate textual descriptions with relevant spatial audio cues, and even infer properties of unseen environments based solely on audio input.
This capability could enable new applications in areas like audio-text retrieval, robotic navigation, virtual environments, and accessibility for the visually impaired. However, further research is needed to address the limitations of the current experiments and assess the real-world performance of these models.
Ultimately, this work highlights the remarkable potential of large language models to understand not just language, but also the physical world around us - and points the way toward more intelligent, multimodal AI systems that can seamlessly integrate diverse sensory inputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
New!Learning Spatially-Aware Language and Audio Embedding
Bhavika Devnani, Skyler Seto, Zakaria Aldeneh, Alessandro Toso, Elena Menyaylenko, Barry-John Theobald, Jonathan Sheaffer, Miguel Sarabia
Humans can picture a sound scene given an imprecise natural language description. For example, it is easy to imagine an acoustic environment given a phrase like the lion roar came from right behind me!. For a machine to have the same degree of comprehension, the machine must know what a lion is (semantic attribute), what the concept of behind is (spatial attribute) and how these pieces of linguistic information align with the semantic and spatial attributes of the sound (what a roar sounds like when its coming from behind). State-of-the-art audio foundation models which learn to map between audio scenes and natural textual descriptions, are trained on non-spatial audio and text pairs, and hence lack spatial awareness. In contrast, sound event localization and detection models are limited to recognizing sounds from a fixed number of classes, and they localize the source to absolute position (e.g., 0.2m) rather than a position described using natural language (e.g., next to me). To address these gaps, we present ELSA a spatially aware-audio and text embedding model trained using multimodal contrastive learning. ELSA supports non-spatial audio, spatial audio, and open vocabulary text captions describing both the spatial and semantic components of sound. To train ELSA: (a) we spatially augment the audio and captions of three open-source audio datasets totaling 4,738 hours of audio, and (b) we design an encoder to capture the semantics of non-spatial audio, and the semantics and spatial attributes of spatial audio using contrastive learning. ELSA is competitive with state-of-the-art for both semantic retrieval and 3D source localization. In particular, ELSA achieves +2.8% mean audio-to-text and text-to-audio R@1 above the baseline, and outperforms by -11.6{deg} mean-absolute-error in 3D source localization over the baseline.
Read more9/18/2024

0
Can Large Language Models Understand Spatial Audio?
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Jun Zhang, Lu Lu, Zejun Ma, Yuxuan Wang, Chao Zhang
This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
Read more6/17/2024
💬
0
BAT: Learning to Reason about Spatial Sounds with Large Language Models
Zhisheng Zheng, Puyuan Peng, Ziyang Ma, Xie Chen, Eunsol Choi, David Harwath
Spatial sound reasoning is a fundamental human skill, enabling us to navigate and interpret our surroundings based on sound. In this paper we present BAT, which combines the spatial sound perception ability of a binaural acoustic scene analysis model with the natural language reasoning capabilities of a large language model (LLM) to replicate this innate ability. To address the lack of existing datasets of in-the-wild spatial sounds, we synthesized a binaural audio dataset using AudioSet and SoundSpaces 2.0. Next, we developed SpatialSoundQA, a spatial sound-based question-answering dataset, offering a range of QA tasks that train BAT in various aspects of spatial sound perception and reasoning. The acoustic front end encoder of BAT is a novel spatial audio encoder named Spatial Audio Spectrogram Transformer, or Spatial-AST, which by itself achieves strong performance across sound event detection, spatial localization, and distance estimation. By integrating Spatial-AST with LLaMA-2 7B model, BAT transcends standard Sound Event Localization and Detection (SELD) tasks, enabling the model to reason about the relationships between the sounds in its environment. Our experiments demonstrate BAT's superior performance on both spatial sound perception and reasoning, showcasing the immense potential of LLMs in navigating and interpreting complex spatial audio environments.
Read more5/28/2024
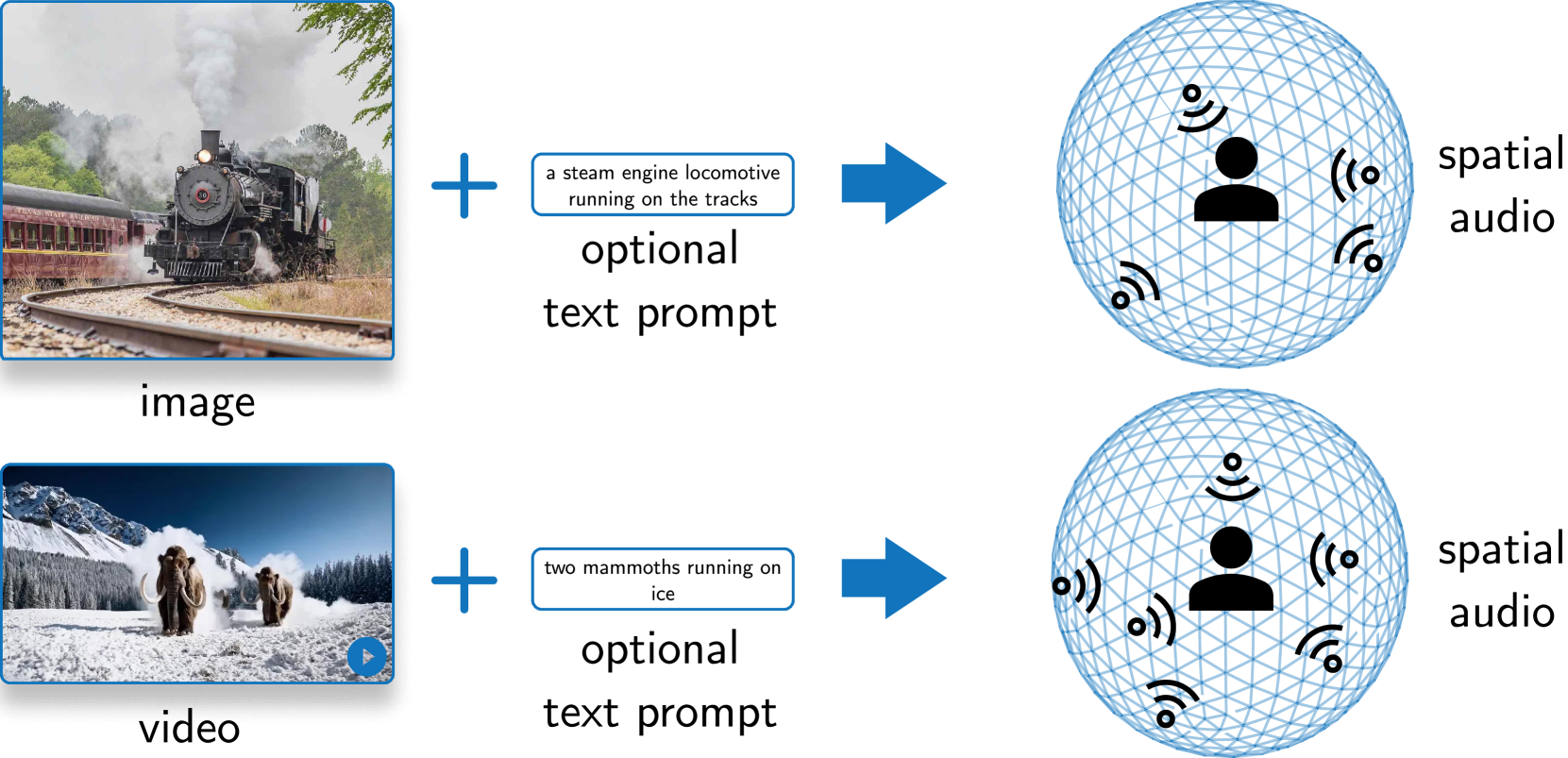
0
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Rishit Dagli, Shivesh Prakash, Robert Wu, Houman Khosravani
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
Read more6/12/2024