SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
2406.06612
0
0
Abstract
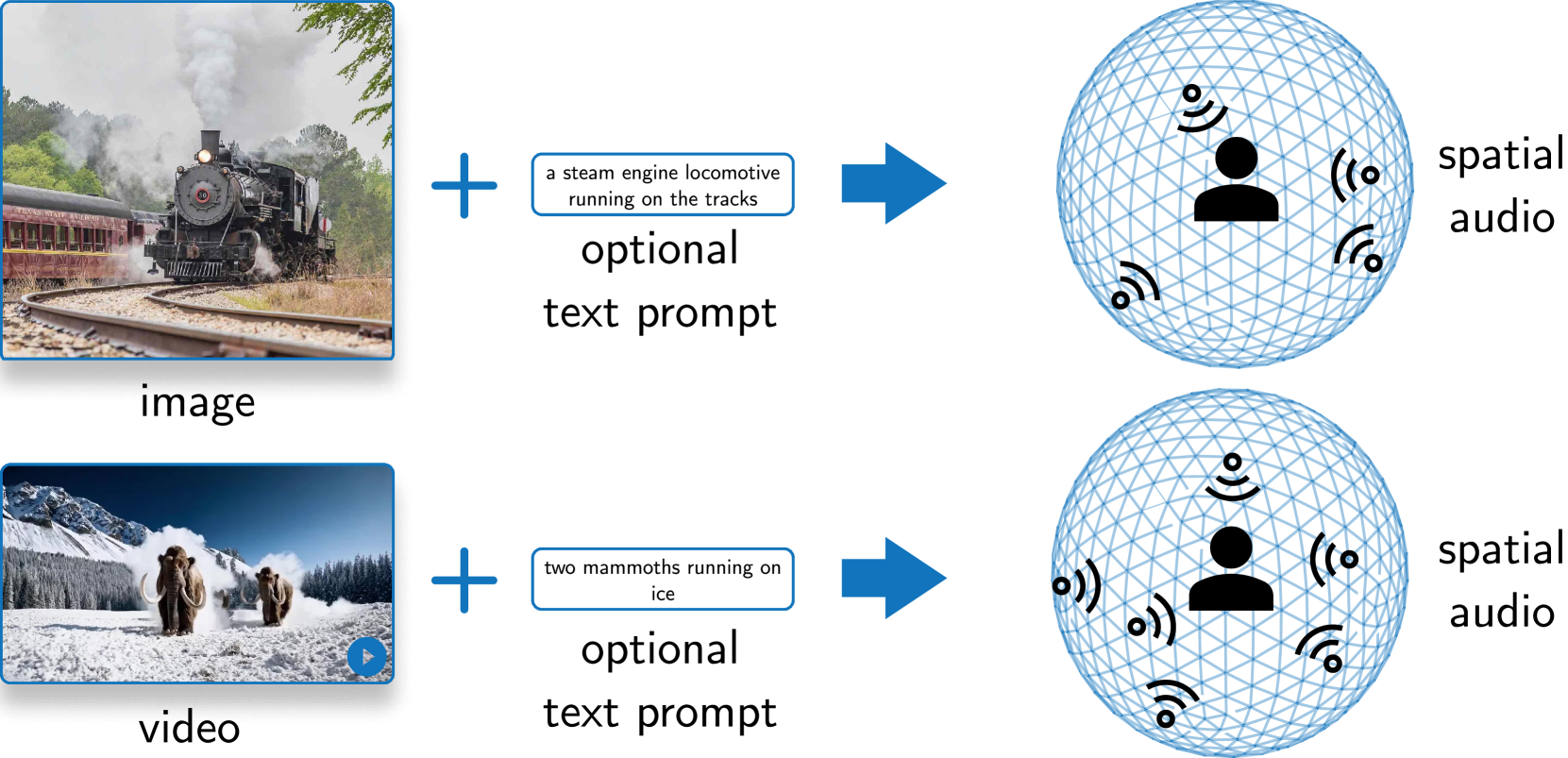
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
Create account to get full access
Overview
- This paper presents a novel approach called SEE-2-SOUND, which enables the generation of spatial sound from raw visual observations of a scene.
- The system is trained in a zero-shot manner, meaning it can generate spatial sound for new environments without requiring any audio data for those environments.
- The key innovation is the ability to learn spatial sound representations directly from visual inputs, without relying on paired audio-visual data.
Plain English Explanation
The researchers have developed a system called SEE-2-SOUND that can generate 3D spatial sound from just looking at a scene, without needing any audio recordings of that environment. This is a "zero-shot" approach, meaning the system can work for new places it hasn't seen before.
The core idea is that the system learns to extract relevant spatial information directly from visual inputs, rather than relying on matching audio and video data. This allows the model to generate realistic 3D sound that matches the visual layout and objects in a scene, even if no audio recordings of that specific environment are available.
This could be useful for various applications, like generating immersive audio for virtual or augmented reality experiences, or enabling robots and assistants to understand and respond to the acoustic properties of new environments they encounter. The key advantage is that it removes the need to capture audio data for every new environment, which can be time-consuming and costly.
Technical Explanation
The SEE-2-SOUND system uses a deep learning architecture that takes in raw visual observations of a scene and generates a corresponding 3D spatial sound field. The core innovation is the ability to learn these spatial sound representations directly from visual inputs, without requiring any paired audio-visual data during training.
The model consists of a visual encoder that processes the input scene, followed by a spatial sound decoder that maps the visual features to a set of spatial audio parameters. This allows the system to generate a binaural audio signal that captures the spatial properties of the environment, such as the locations of sound sources and acoustic reflections.
The training process is designed as a zero-shot learning task, where the model is exposed to a diverse set of visual environments, but does not have access to any corresponding audio recordings. The system is trained to learn general visual-to-spatial audio mappings by optimizing a set of perceptual loss functions that capture important aspects of the spatial sound field, such as source localization and room acoustics.
The researchers evaluate SEE-2-SOUND on a variety of indoor and outdoor scenes, demonstrating its ability to generate realistic spatial audio that matches the visual properties of the environments. The results show that the system outperforms baseline approaches that rely on paired audio-visual data or hand-engineered acoustic features.
Critical Analysis
The SEE-2-SOUND approach represents a significant advancement in the field of spatial audio generation, as it addresses the challenge of creating immersive sound experiences without the need for extensive audio data collection. The zero-shot learning setup is particularly impressive, as it allows the system to generalize to new environments without any additional training.
That said, the paper acknowledges several limitations and areas for future research. For example, the current system is limited to generating static spatial audio, and does not yet account for dynamic events or moving sound sources. Additionally, the evaluation is primarily focused on subjective human listening tests, and more objective metrics could be explored to better quantify the system's performance.
Further research could also investigate ways to incorporate additional modalities, such as text-guided audio-visual scene understanding or learning spatial features from audio-visual correspondence, to potentially improve the system's ability to generate even more realistic and contextually-relevant spatial audio.
Conclusion
The SEE-2-SOUND system represents a significant step forward in the field of spatial audio generation, enabling the creation of immersive 3D sound experiences from visual inputs alone. By learning to extract relevant spatial information directly from visual data, the system can generate realistic spatial audio for new environments without requiring any corresponding audio recordings.
This capability has the potential to unlock a wide range of applications, from enhancing virtual and augmented reality experiences to enabling robots and assistants to better understand and respond to the acoustic properties of their surroundings. As the researchers continue to refine and expand the system, it could lead to further advancements in audio-visual talker localization, generating images that sound, and other areas of hearing anything anywhere.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hearing Anything Anywhere
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, Jiajun Wu
0
0
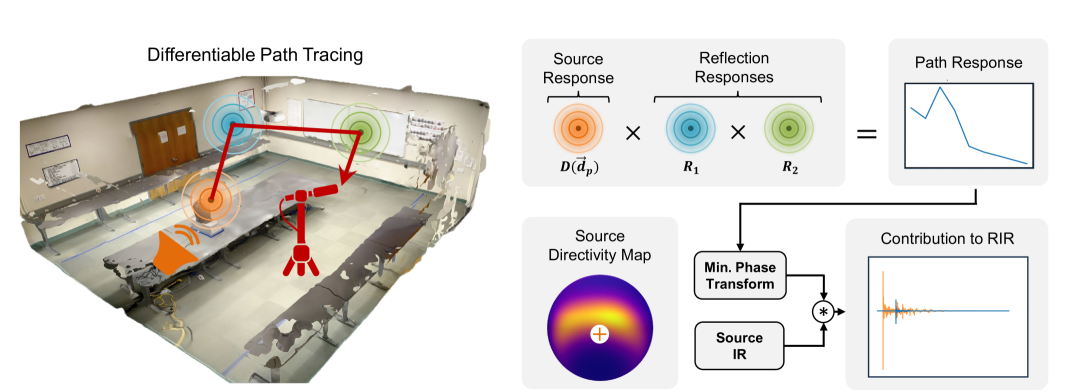
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
6/12/2024

Can Large Language Models Understand Spatial Audio?
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Jun Zhang, Lu Lu, Zejun Ma, Yuxuan Wang, Chao Zhang
0
0
This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
6/17/2024

Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
Changan Chen, Puyuan Peng, Ami Baid, Zihui Xue, Wei-Ning Hsu, David Harwath, Kristen Grauman
0
0
Generating realistic audio for human interactions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals -- resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets Ego4D and EPIC-KITCHENS. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our work is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
6/21/2024
Audio-Visual Talker Localization in Video for Spatial Sound Reproduction
Davide Berghi, Philip J. B. Jackson
0
0
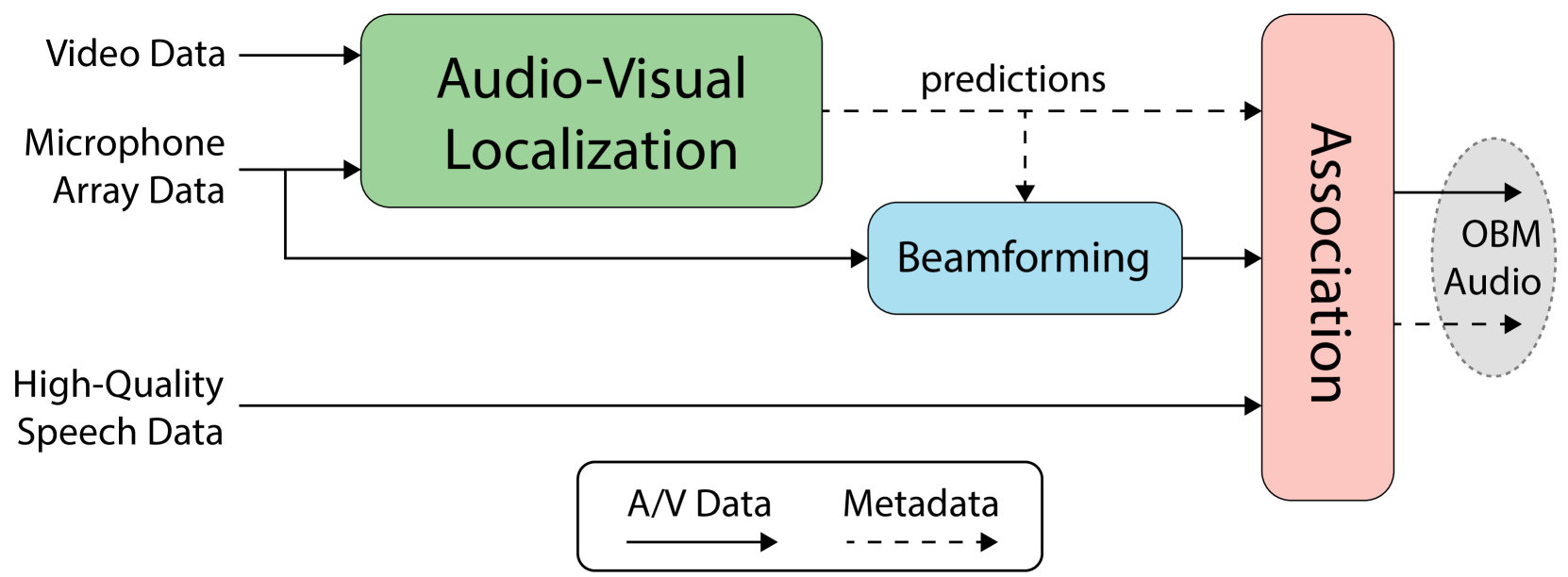
Object-based audio production requires the positional metadata to be defined for each point-source object, including the key elements in the foreground of the sound scene. In many media production use cases, both cameras and microphones are employed to make recordings, and the human voice is often a key element. In this research, we detect and locate the active speaker in the video, facilitating the automatic extraction of the positional metadata of the talker relative to the camera's reference frame. With the integration of the visual modality, this study expands upon our previous investigation focused solely on audio-based active speaker detection and localization. Our experiments compare conventional audio-visual approaches for active speaker detection that leverage monaural audio, our previous audio-only method that leverages multichannel recordings from a microphone array, and a novel audio-visual approach integrating vision and multichannel audio. We found the role of the two modalities to complement each other. Multichannel audio, overcoming the problem of visual occlusions, provides a double-digit reduction in detection error compared to audio-visual methods with single-channel audio. The combination of multichannel audio and vision further enhances spatial accuracy, leading to a four-percentage point increase in F1 score on the Tragic Talkers dataset. Future investigations will assess the robustness of the model in noisy and highly reverberant environments, as well as tackle the problem of off-screen speakers.
6/4/2024