Learning Subject-Aware Cropping by Outpainting Professional Photos

0

Sign in to get full access
Additional Results and Ablations
Computational Cost of Image Generation
The paper provides details on the computational cost of the image generation process. Generating a high-quality image with the proposed approach requires significant computational resources, as it involves multiple steps, including outpainting, compositing, and fine-tuning. The authors note that the computational cost is a limitation of the current approach and suggest that future research should focus on improving the efficiency of the image generation process.
Full Qualitative Results
The paper presents a comprehensive set of qualitative results, showcasing the ability of the proposed approach to generate high-quality, subject-aware cropped images. The results demonstrate that the model can effectively handle a wide range of subjects and scenes, producing visually appealing and coherent outputs. The authors provide a detailed analysis of the strengths and limitations of the approach, highlighting areas for future improvement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Subject-Aware Cropping by Outpainting Professional Photos
James Hong, Lu Yuan, Michael Gharbi, Matthew Fisher, Kayvon Fatahalian
How to frame (or crop) a photo often depends on the image subject and its context; e.g., a human portrait. Recent works have defined the subject-aware image cropping task as a nuanced and practical version of image cropping. We propose a weakly-supervised approach (GenCrop) to learn what makes a high-quality, subject-aware crop from professional stock images. Unlike supervised prior work, GenCrop requires no new manual annotations beyond the existing stock image collection. The key challenge in learning from this data, however, is that the images are already cropped and we do not know what regions were removed. Our insight is to combine a library of stock images with a modern, pre-trained text-to-image diffusion model. The stock image collection provides diversity and its images serve as pseudo-labels for a good crop, while the text-image diffusion model is used to out-paint (i.e., outward inpainting) realistic uncropped images. Using this procedure, we are able to automatically generate a large dataset of cropped-uncropped training pairs to train a cropping model. Despite being weakly-supervised, GenCrop is competitive with state-of-the-art supervised methods and significantly better than comparable weakly-supervised baselines on quantitative and qualitative evaluation metrics.
Read more4/5/2024
0
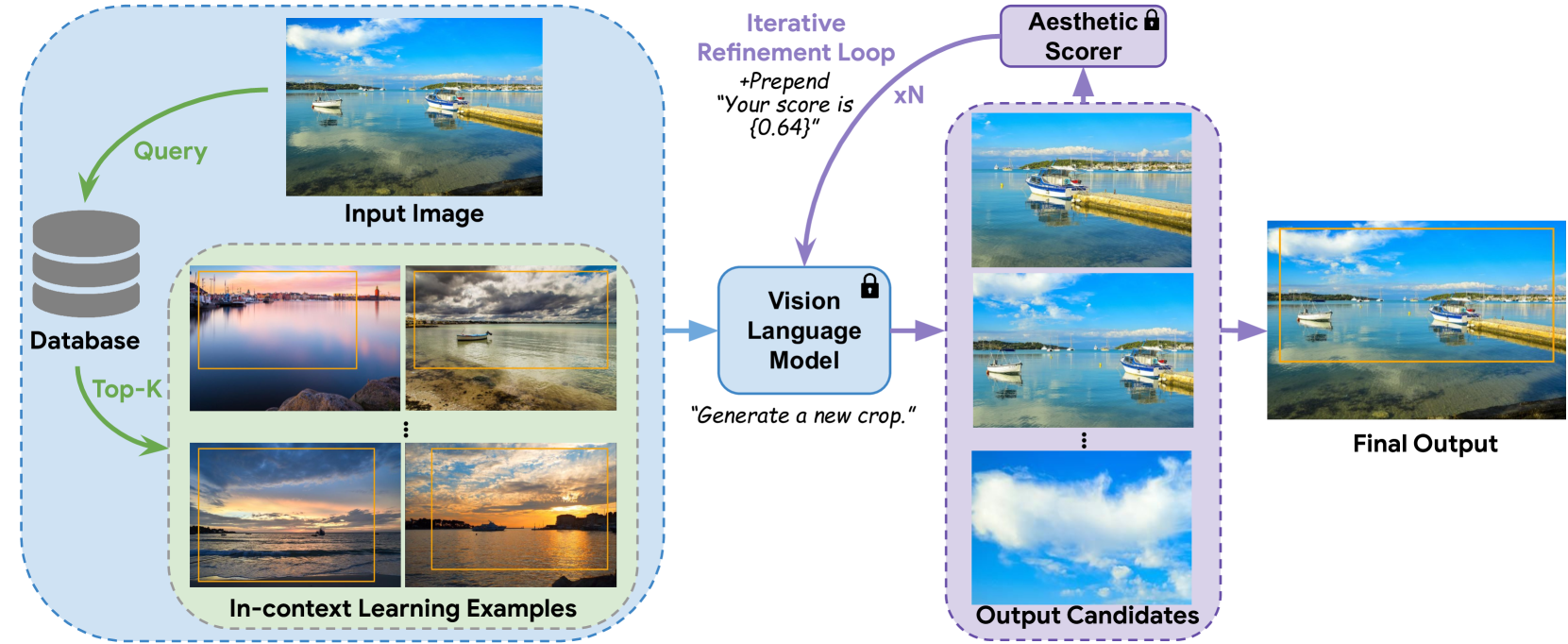
Cropper: Vision-Language Model for Image Cropping through In-Context Learning
Seung Hyun Lee, Junjie Ke, Yinxiao Li, Junfeng He, Steven Hickson, Katie Datsenko, Sangpil Kim, Ming-Hsuan Yang, Irfan Essa, Feng Yang
The goal of image cropping is to identify visually appealing crops within an image. Conventional methods rely on specialized architectures trained on specific datasets, which struggle to be adapted to new requirements. Recent breakthroughs in large vision-language models (VLMs) have enabled visual in-context learning without explicit training. However, effective strategies for vision downstream tasks with VLMs remain largely unclear and underexplored. In this paper, we propose an effective approach to leverage VLMs for better image cropping. First, we propose an efficient prompt retrieval mechanism for image cropping to automate the selection of in-context examples. Second, we introduce an iterative refinement strategy to iteratively enhance the predicted crops. The proposed framework, named Cropper, is applicable to a wide range of cropping tasks, including free-form cropping, subject-aware cropping, and aspect ratio-aware cropping. Extensive experiments and a user study demonstrate that Cropper significantly outperforms state-of-the-art methods across several benchmarks.
Read more8/16/2024
🖼️
0
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Navve Wasserman, Noam Rotstein, Roy Ganz, Ron Kimmel
Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to the utilization of segmentation mask datasets alongside inpainting models that inpaint within these masks. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones; moreover, it maintains consistency between source and target by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. We show that the trained model surpasses existing ones both qualitatively and quantitatively, and release the large-scale dataset alongside the trained models for the community.
Read more4/30/2024
0
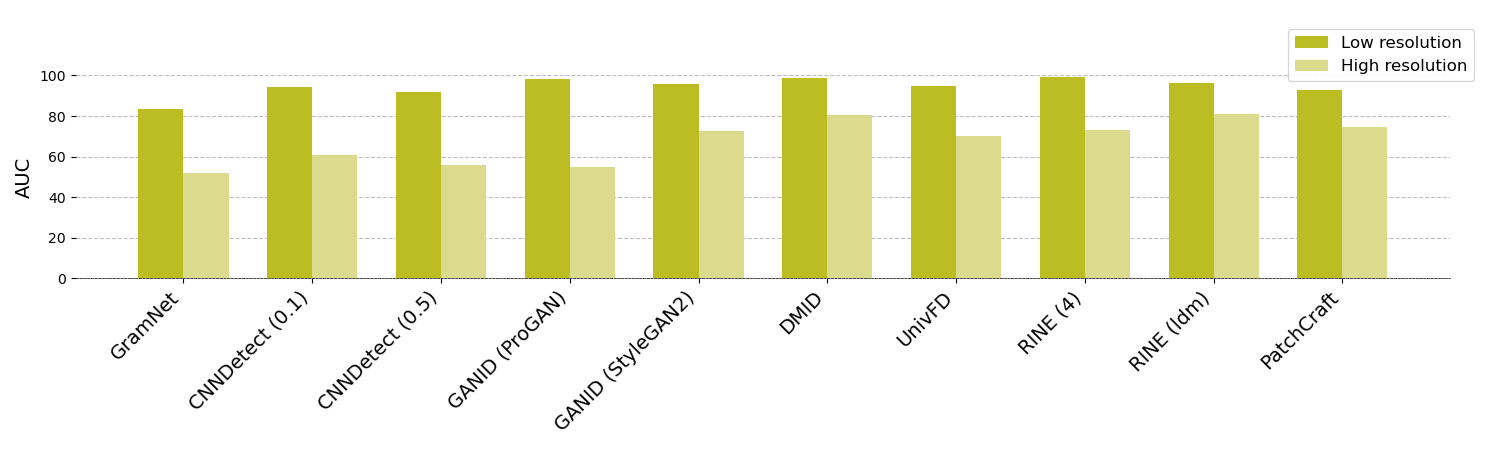
TextureCrop: Enhancing Synthetic Image Detection through Texture-based Cropping
Despina Konstantinidou, Christos Koutlis, Symeon Papadopoulos
Generative AI technologies produce hyper-realistic imagery that can be used for nefarious purposes such as producing misleading or harmful content, among others. This makes Synthetic Image Detection (SID) an essential tool for defending against AI-generated harmful content. Current SID methods typically resize input images to a fixed resolution or perform center-cropping due to computational concerns, leading to challenges in effectively detecting artifacts in high-resolution images. To this end, we propose TextureCrop, a novel image pre-processing technique. By focusing on high-frequency image parts where generation artifacts are prevalent, TextureCrop effectively enhances SID accuracy while maintaining manageable memory requirements. Experimental results demonstrate a consistent improvement in AUC across various detectors by 5.7% compared to center cropping and by 14% compared to resizing, across high-resolution images from the Forensynths and Synthbuster datasets.
Read more7/23/2024