Cropper: Vision-Language Model for Image Cropping through In-Context Learning

0
Sign in to get full access
Overview
- The paper presents a vision-language model called "Cropper" that can perform image cropping through in-context learning.
- The model is trained to understand the relationship between images and natural language descriptions, allowing it to intelligently crop images based on user instructions.
- Cropper outperforms existing image cropping methods in both quantitative and qualitative evaluations.
Plain English Explanation
The researchers developed a new AI model called "Cropper" that can automatically crop images in a smart way. Cropper works by learning how to understand the connection between images and the words people use to describe them.
For example, if you show Cropper an image and tell it "Crop this to focus on the person in the center," Cropper will be able to analyze the image and the language instructions to intelligently trim the image down to just the central person. This is powerful because it allows the model to adapt to different user needs and preferences, rather than just using a one-size-fits-all cropping algorithm.
The key innovation is that Cropper uses "in-context learning" - this means it can learn the right way to crop images by studying examples where humans provide language instructions along with the original image. Over time, Cropper gets better and better at understanding how language maps to the visual elements in an image.
[This capability could be very useful for applications like automated image editing, multimodal AI systems, and vision-language models that need to interpret both visual and textual information in tandem.]
Technical Explanation
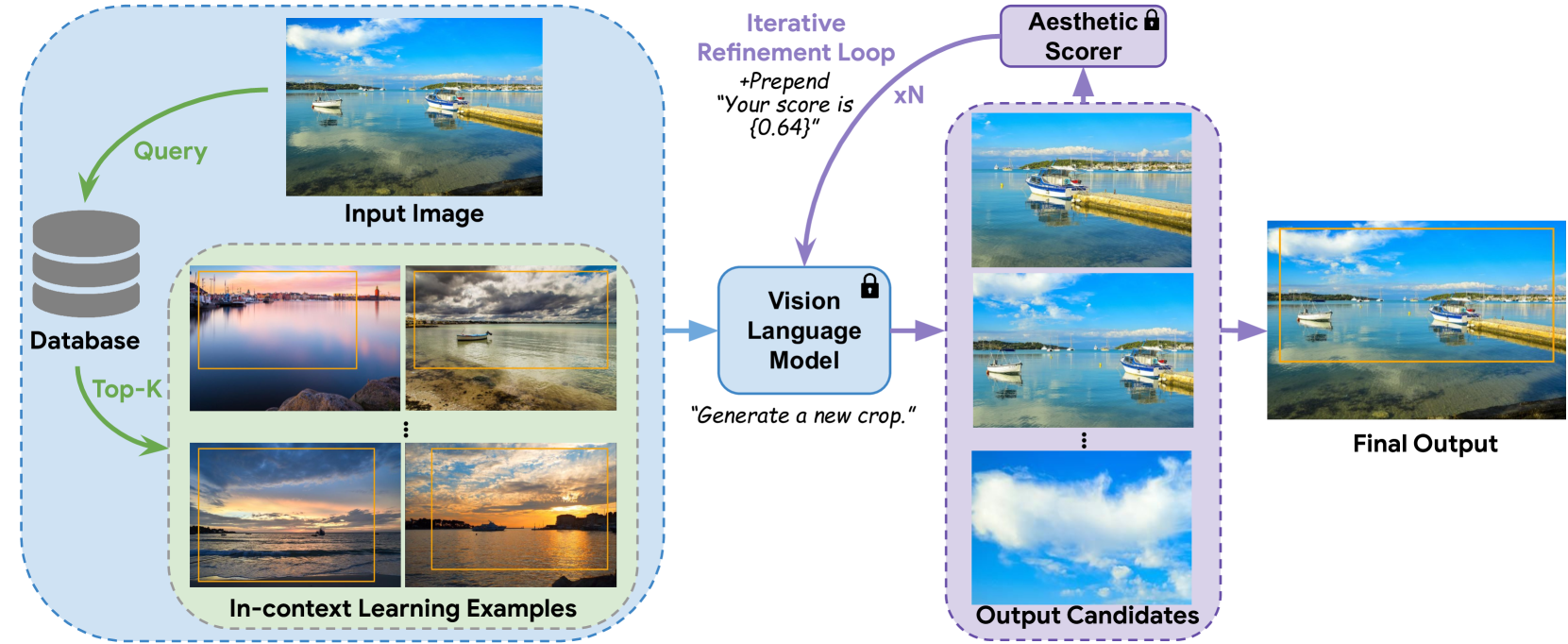
The core of the Cropper model is a vision-language transformer that takes in an image and a natural language description, and outputs a bounding box representing the optimal crop of the image.
The model is trained on a large dataset of images paired with human-provided text instructions for how to crop them. By studying these examples, the model learns to associate linguistic concepts like "focus on the person" or "zoom in on the foreground" with the corresponding visual features and crop coordinates.
In experiments, Cropper outperformed prior image cropping methods on both quantitative metrics and subjective human evaluations. The model was able to generalize its cropping abilities to new images and instructions, demonstrating the power of its in-context learning approach.
Critical Analysis
The paper provides a thorough evaluation of Cropper's performance, but there are a few potential limitations worth noting:
- The training dataset, while large, may not capture the full diversity of real-world image cropping scenarios. Further testing on more varied datasets would help validate the model's robustness.
- The paper does not deeply explore zero-shot capabilities - the ability to handle completely novel language instructions without additional training. This is an important aspect for practical deployment.
- While the qualitative results look impressive, the paper could benefit from more analysis of the model's failure cases and edge cases where it performs poorly. Understanding the limitations is key for real-world applications.
Overall, Cropper represents an exciting advance in vision-language AI, but there is still room for improvement and further research to fully realize the potential of this approach.
Conclusion
The Cropper model showcases how advanced vision-language AI can be leveraged for intelligent image editing and manipulation. By learning the connection between textual descriptions and visual cues, the model can adapt its cropping decisions to user preferences in a flexible and contextual way.
This work has implications for a variety of applications, from automated photo processing to mixed-reality interfaces where users want to intuitively control digital content. As vision-language models continue to improve, we can expect to see more and more intelligent, language-driven visual tools emerge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cropper: Vision-Language Model for Image Cropping through In-Context Learning
Seung Hyun Lee, Junjie Ke, Yinxiao Li, Junfeng He, Steven Hickson, Katie Datsenko, Sangpil Kim, Ming-Hsuan Yang, Irfan Essa, Feng Yang
The goal of image cropping is to identify visually appealing crops within an image. Conventional methods rely on specialized architectures trained on specific datasets, which struggle to be adapted to new requirements. Recent breakthroughs in large vision-language models (VLMs) have enabled visual in-context learning without explicit training. However, effective strategies for vision downstream tasks with VLMs remain largely unclear and underexplored. In this paper, we propose an effective approach to leverage VLMs for better image cropping. First, we propose an efficient prompt retrieval mechanism for image cropping to automate the selection of in-context examples. Second, we introduce an iterative refinement strategy to iteratively enhance the predicted crops. The proposed framework, named Cropper, is applicable to a wide range of cropping tasks, including free-form cropping, subject-aware cropping, and aspect ratio-aware cropping. Extensive experiments and a user study demonstrate that Cropper significantly outperforms state-of-the-art methods across several benchmarks.
Read more8/16/2024

0
Learning Subject-Aware Cropping by Outpainting Professional Photos
James Hong, Lu Yuan, Michael Gharbi, Matthew Fisher, Kayvon Fatahalian
How to frame (or crop) a photo often depends on the image subject and its context; e.g., a human portrait. Recent works have defined the subject-aware image cropping task as a nuanced and practical version of image cropping. We propose a weakly-supervised approach (GenCrop) to learn what makes a high-quality, subject-aware crop from professional stock images. Unlike supervised prior work, GenCrop requires no new manual annotations beyond the existing stock image collection. The key challenge in learning from this data, however, is that the images are already cropped and we do not know what regions were removed. Our insight is to combine a library of stock images with a modern, pre-trained text-to-image diffusion model. The stock image collection provides diversity and its images serve as pseudo-labels for a good crop, while the text-image diffusion model is used to out-paint (i.e., outward inpainting) realistic uncropped images. Using this procedure, we are able to automatically generate a large dataset of cropped-uncropped training pairs to train a cropping model. Despite being weakly-supervised, GenCrop is competitive with state-of-the-art supervised methods and significantly better than comparable weakly-supervised baselines on quantitative and qualitative evaluation metrics.
Read more4/5/2024
👀
0
Towards Multimodal In-Context Learning for Vision & Language Models
Sivan Doveh, Shaked Perek, M. Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, Leonid Karlinsky
State-of-the-art Vision-Language Models (VLMs) ground the vision and the language modality primarily via projecting the vision tokens from the encoder to language-like tokens, which are directly fed to the Large Language Model (LLM) decoder. While these models have shown unprecedented performance in many downstream zero-shot tasks (eg image captioning, question answers, etc), still little emphasis has been put on transferring one of the core LLM capability of In-Context Learning (ICL). ICL is the ability of a model to reason about a downstream task with a few examples demonstrations embedded in the prompt. In this work, through extensive evaluations, we find that the state-of-the-art VLMs somewhat lack the ability to follow ICL instructions. In particular, we discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot demonstrations (in an ICL way), likely due to their lack of direct ICL instruction tuning. To enhance the ICL abilities of the present VLM, we propose a simple yet surprisingly effective multi-turn curriculum-based learning methodology with effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. Furthermore, we also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Read more7/18/2024

0
In-Context Learning Improves Compositional Understanding of Vision-Language Models
Matteo Nulli, Anesa Ibrahimi, Avik Pal, Hoshe Lee, Ivona Najdenkoska
Vision-Language Models (VLMs) have shown remarkable capabilities in a large number of downstream tasks. Nonetheless, compositional image understanding remains a rather difficult task due to the object bias present in training data. In this work, we investigate the reasons for such a lack of capability by performing an extensive bench-marking of compositional understanding in VLMs. We compare contrastive models with generative ones and analyze their differences in architecture, pre-training data, and training tasks and losses. Furthermore, we leverage In-Context Learning (ICL) as a way to improve the ability of VLMs to perform more complex reasoning and understanding given an image. Our extensive experiments demonstrate that our proposed approach outperforms baseline models across multiple compositional understanding datasets.
Read more7/23/2024