Learning to Generate Answers with Citations via Factual Consistency Models
2406.13124
0
0

Abstract
Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
Create account to get full access
Overview
- This paper presents a novel approach for generating answers to questions with supporting citations, called Factual Consistency Models (FCMs).
- FCMs are trained to generate answers that are factually consistent with the provided evidence, including citations to relevant research papers.
- The authors address the challenge of ensuring that generated answers are grounded in the available evidence and do not contain factual errors or inconsistencies.
Plain English Explanation
The researchers have developed a new way to generate answers to questions that include citations to relevant research papers. This builds on previous work on generating text with citations and using context to improve language model performance.
The key idea is to train a model, called a Factual Consistency Model (FCM), to produce answers that are factually consistent with the evidence provided in the cited research papers. This helps ensure that the generated answers are accurate and grounded in the available information, rather than containing errors or making unsupported claims.
The authors also explore techniques for generating fine-grained, verifiable citations at the subsentence level, which allows for more precise tracking of which parts of the answer are supported by which sources.
Overall, this work aims to improve the reliability and trustworthiness of language models by ensuring their outputs are factually consistent with the available evidence. This ties into broader efforts to develop more grounded and robust large language models that can be relied upon to provide accurate and trustworthy information.
Technical Explanation
The key technical innovation in this paper is the Factual Consistency Model (FCM), a neural network architecture designed to generate answers that are factually consistent with the provided evidence.
The FCM takes as input a question, a set of relevant research papers, and any other contextual information. It then generates an answer along with citations to the specific passages in the papers that support the factual claims made in the answer.
To train the FCM, the authors use a multi-task learning approach that combines answer generation with a factual consistency objective. This encourages the model to produce answers that are grounded in the evidence and do not contain unsupported claims.
The authors also explore techniques for generating fine-grained, verifiable citations at the subsentence level, which allows for more precise tracking of which parts of the answer are supported by which sources.
Experiments on benchmark question-answering datasets demonstrate the effectiveness of the FCM approach, showing that it can generate answers that are more factually consistent with the provided evidence compared to baseline language models.
Critical Analysis
The authors acknowledge several limitations and areas for further research:
- The current approach is limited to generating answers supported by the provided evidence, and does not handle cases where the evidence is incomplete or insufficient.
- The techniques for generating fine-grained citations are still relatively coarse and could be improved to provide even more granular tracking of the support for each claim.
- The training process for the FCM is computationally intensive and may not be scalable to very large language models or datasets.
Additionally, while the paper demonstrates the effectiveness of the FCM approach on benchmark datasets, it would be important to further validate the performance and real-world applicability of the system through more extensive user studies and evaluations.
Overall, this work represents an important step towards developing more reliable and trustworthy language models that can generate factually consistent information. However, there is still significant room for improvement in ensuring the robustness and faithfulness of large language models.
Conclusion
This paper presents a novel Factual Consistency Model (FCM) for generating answers to questions that are grounded in the available evidence and supported by citations to relevant research papers.
The key innovation is the use of a multi-task learning approach that encourages the model to produce answers that are factually consistent with the provided information, rather than making unsupported claims.
By improving the reliability and trustworthiness of language model outputs, this work represents an important step towards developing AI systems that can be relied upon to provide accurate and trustworthy information. However, there are still significant challenges to overcome in ensuring the robustness and faithfulness of large language models, which will require ongoing research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Training Language Models to Generate Text with Citations via Fine-grained Rewards
Chengyu Huang, Zeqiu Wu, Yushi Hu, Wenya Wang
0
0
While recent Large Language Models (LLMs) have proven useful in answering user queries, they are prone to hallucination, and their responses often lack credibility due to missing references to reliable sources. An intuitive solution to these issues would be to include in-text citations referring to external documents as evidence. While previous works have directly prompted LLMs to generate in-text citations, their performances are far from satisfactory, especially when it comes to smaller LLMs. In this work, we propose an effective training framework using fine-grained rewards to teach LLMs to generate highly supportive and relevant citations, while ensuring the correctness of their responses. We also conduct a systematic analysis of applying these fine-grained rewards to common LLM training strategies, demonstrating its advantage over conventional practices. We conduct extensive experiments on Question Answering (QA) datasets taken from the ALCE benchmark and validate the model's generalizability using EXPERTQA. On LLaMA-2-7B, the incorporation of fine-grained rewards achieves the best performance among the baselines, even surpassing that of GPT-3.5-turbo.
5/28/2024
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
0
0
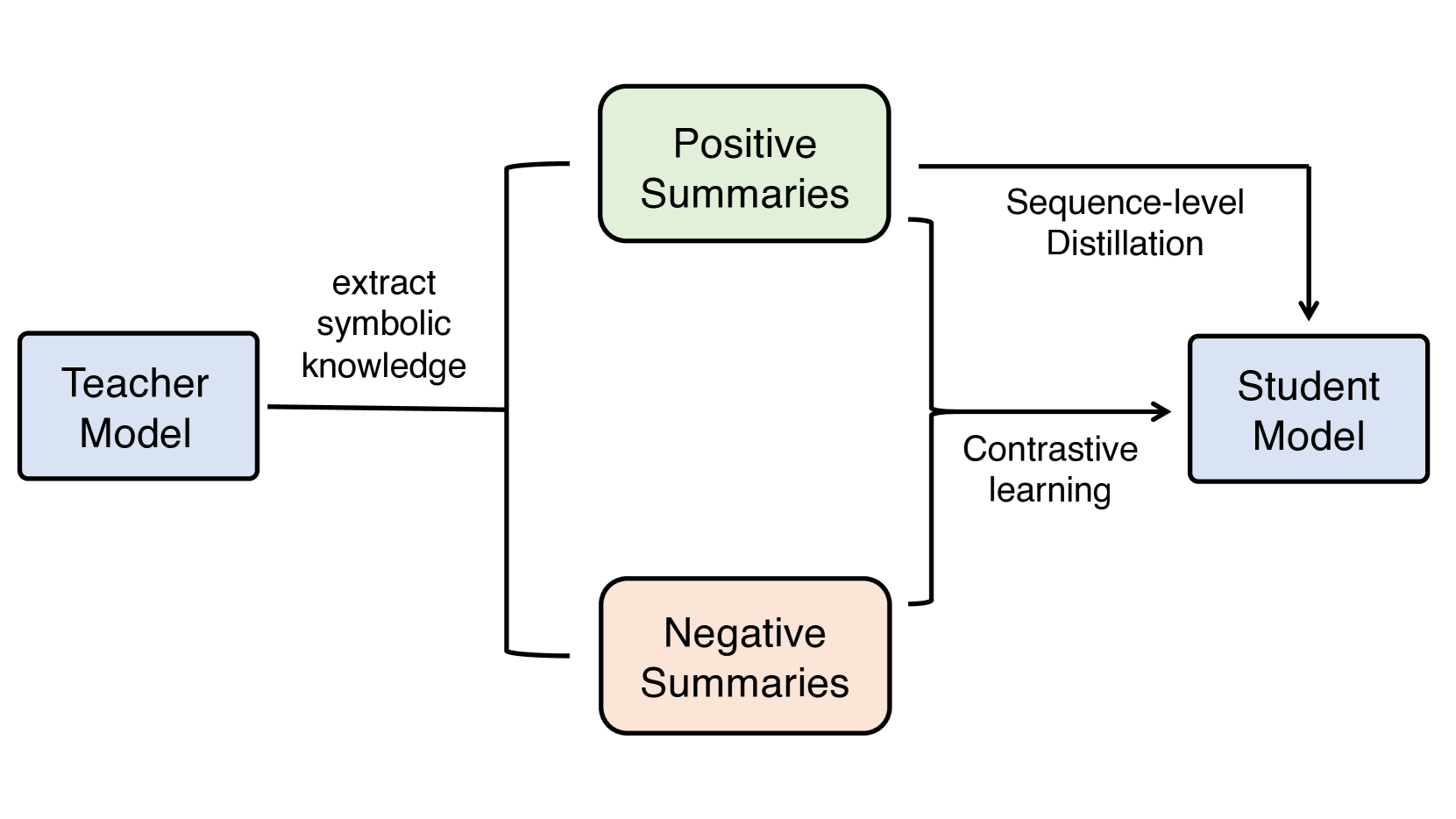
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
6/24/2024
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
0
0
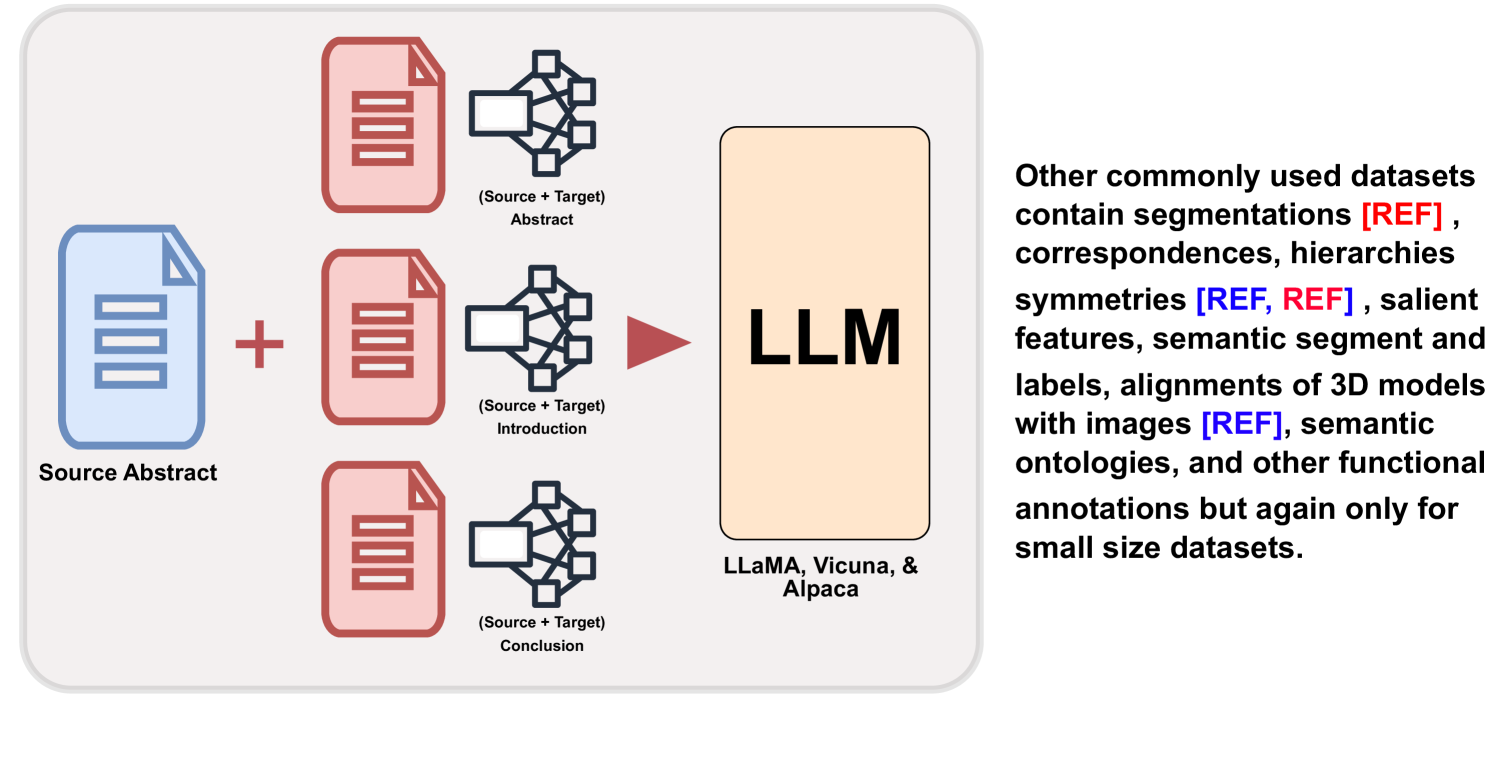
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
4/23/2024
Verifiable Generation with Subsentence-Level Fine-Grained Citations
Shuyang Cao, Lu Wang
0
0
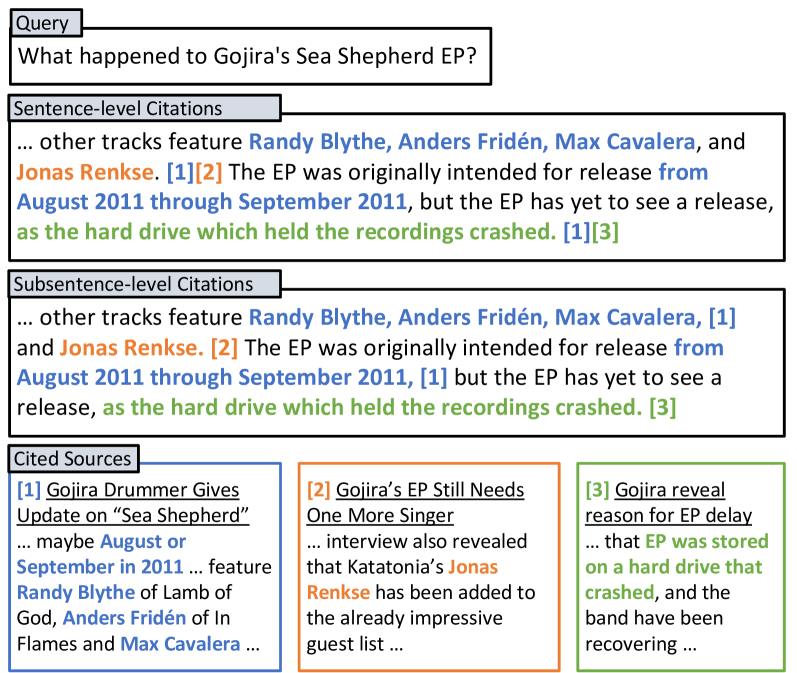
Verifiable generation requires large language models (LLMs) to cite source documents supporting their outputs, thereby improve output transparency and trustworthiness. Yet, previous work mainly targets the generation of sentence-level citations, lacking specificity about which parts of a sentence are backed by the cited sources. This work studies verifiable generation with subsentence-level fine-grained citations for more precise location of generated content supported by the cited sources. We first present a dataset, SCiFi, comprising 10K Wikipedia paragraphs with subsentence-level citations. Each paragraph is paired with a set of candidate source documents for citation and a query that triggers the generation of the paragraph content. On SCiFi, we evaluate the performance of state-of-the-art LLMs and strategies for processing long documents designed for these models. Our experiment results reveals key factors that could enhance the quality of citations, including the expansion of the source documents' context accessible to the models and the implementation of specialized model tuning.
6/11/2024