Learning to Optimize for Reinforcement Learning
2302.01470
0
0
🏅
Abstract
In recent years, by leveraging more data, computation, and diverse tasks, learned optimizers have achieved remarkable success in supervised learning, outperforming classical hand-designed optimizers. Reinforcement learning (RL) is essentially different from supervised learning, and in practice, these learned optimizers do not work well even in simple RL tasks. We investigate this phenomenon and identify two issues. First, the agent-gradient distribution is non-independent and identically distributed, leading to inefficient meta-training. Moreover, due to highly stochastic agent-environment interactions, the agent-gradients have high bias and variance, which increases the difficulty of learning an optimizer for RL. We propose pipeline training and a novel optimizer structure with a good inductive bias to address these issues, making it possible to learn an optimizer for reinforcement learning from scratch. We show that, although only trained in toy tasks, our learned optimizer can generalize to unseen complex tasks in Brax.
Create account to get full access
Overview
- Learned optimizers have achieved impressive results in supervised learning, outperforming classical hand-designed optimizers.
- However, these learned optimizers do not perform well even in simple reinforcement learning (RL) tasks.
- The paper investigates this phenomenon and identifies two key issues that make learning an optimizer for RL challenging.
Plain English Explanation
Machine learning models have made significant progress in recent years, thanks to the availability of more data, increased computational power, and the ability to tackle diverse tasks. One particular area where learned optimizers have shown remarkable success is in supervised learning, where they have outperformed traditional, hand-designed optimizers.
However, the story is different when it comes to reinforcement learning (RL). RL is fundamentally different from supervised learning, and the learned optimizers that work so well in supervised tasks often struggle even in simple RL problems. This paper delves into the reasons behind this phenomenon and identifies two key issues that make learning an optimizer for RL a challenging task.
The first issue is that in RL, the distribution of the agent's gradients (the signals that guide the agent's learning) is not independent and identically distributed (i.i.d.), as is often the case in supervised learning. This non-i.i.d. nature of the gradients makes it difficult to efficiently train a meta-optimizer (an optimizer that learns to optimize) for RL.
The second issue is the high bias and variance in the agent's gradients, which is a result of the highly stochastic nature of the agent-environment interactions in RL. This increased gradient noise makes it even harder for a meta-optimizer to learn effectively.
To address these challenges, the researchers propose a new approach called "pipeline training" and a novel optimizer structure with a good inductive bias. These innovations help overcome the issues identified, making it possible to learn an optimizer for reinforcement learning from scratch.
Technical Explanation
The paper investigates why learned optimizers, which have been so successful in supervised learning tasks, do not perform well in reinforcement learning (RL) environments. The researchers identify two key issues that contribute to this problem.
First, in RL, the distribution of the agent's gradients (the signals that guide the agent's learning) is non-independent and identically distributed (non-i.i.d.), unlike in supervised learning where the gradients are typically i.i.d. This non-i.i.d. nature of the gradients leads to inefficient meta-training, as the meta-optimizer struggles to learn effectively from the diverse and interrelated gradients.
Second, due to the highly stochastic nature of the agent-environment interactions in RL, the agent's gradients have high bias and variance. This increased gradient noise makes it even more challenging for a meta-optimizer to learn an effective update rule.
To address these issues, the researchers propose a "pipeline training" approach, where the meta-optimizer is trained on a sequence of progressively more complex RL tasks. This helps the meta-optimizer learn a good inductive bias for RL optimization.
Additionally, the researchers introduce a novel optimizer structure that is designed to capture the unique characteristics of RL problems, such as the non-i.i.d. and high-variance nature of the gradients. This specialized optimizer architecture enables the meta-optimizer to learn an effective update rule for RL tasks, even starting from scratch.
The researchers evaluate their approach on a range of RL tasks and demonstrate that their learned optimizer can generalize to unseen, complex tasks in the Brax environment, outperforming classical optimizers.
Critical Analysis
The paper presents a thoughtful analysis of the challenges in applying learned optimizers to reinforcement learning tasks, and the proposed solutions appear promising. However, there are a few potential areas for further exploration and improvement:
-
The paper focuses on a limited set of RL tasks, primarily in the Brax environment. It would be valuable to test the learned optimizer on a wider range of RL problems, including more complex and real-world scenarios, to fully evaluate its generalization capabilities.
-
The pipeline training approach, while effective, may be time-consuming and computationally expensive, especially when scaling to larger and more diverse RL tasks. Investigating more efficient meta-training strategies could further improve the practicality of the approach.
-
The paper does not provide a detailed analysis of the inductive bias and inner workings of the proposed optimizer structure. A deeper understanding of how the optimizer architecture captures the unique characteristics of RL problems could lead to further improvements and insights.
-
The researchers could explore ways to incorporate additional domain knowledge or task-specific insights into the meta-optimizer, which may help it learn more effective update rules and further enhance its performance.
Despite these potential areas for improvement, the paper presents a significant contribution to the field of reinforcement learning, highlighting the importance of understanding the unique challenges in this domain and proposing novel solutions to address them.
Conclusion
This paper delves into the challenges of applying learned optimizers, which have been highly successful in supervised learning, to the domain of reinforcement learning (RL). The researchers identify two key issues that make learning an optimizer for RL tasks particularly difficult: the non-i.i.d. nature of the agent's gradients and the high bias and variance in these gradients due to the stochastic nature of RL.
To overcome these challenges, the researchers propose a "pipeline training" approach and a novel optimizer structure with a good inductive bias for RL problems. Their solutions enable the meta-optimizer to learn effective update rules for RL tasks, even starting from scratch.
The ability to learn optimizers for reinforcement learning tasks could have significant implications for the field, potentially leading to more efficient and adaptable RL algorithms that can tackle a wider range of complex problems. The insights and techniques presented in this paper represent an important step forward in this direction, paving the way for further advancements in the field of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective
Victor-Alexandru Darvariu, Stephen Hailes, Mirco Musolesi
0
0
Graphs are a natural representation for systems based on relations between connected entities. Combinatorial optimization problems, which arise when considering an objective function related to a process of interest on discrete structures, are often challenging due to the rapid growth of the solution space. The trial-and-error paradigm of Reinforcement Learning has recently emerged as a promising alternative to traditional methods, such as exact algorithms and (meta)heuristics, for discovering better decision-making strategies in a variety of disciplines including chemistry, computer science, and statistics. Despite the fact that they arose in markedly different fields, these techniques share significant commonalities. Therefore, we set out to synthesize this work in a unifying perspective that we term Graph Reinforcement Learning, interpreting it as a constructive decision-making method for graph problems. After covering the relevant technical background, we review works along the dividing line of whether the goal is to optimize graph structure given a process of interest, or to optimize the outcome of the process itself under fixed graph structure. Finally, we discuss the common challenges facing the field and open research questions. In contrast with other surveys, the present work focuses on non-canonical graph problems for which performant algorithms are typically not known and Reinforcement Learning is able to provide efficient and effective solutions.
4/10/2024
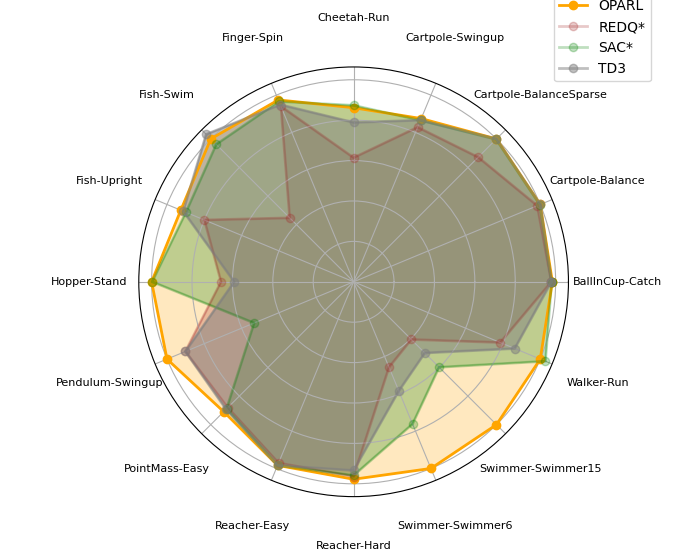
Efficient Reinforcement Learning via Decoupling Exploration and Utilization
Jingpu Yang, Helin Wang, Qirui Zhao, Zhecheng Shi, Zirui Song, Miao Fang
0
0
Reinforcement Learning (RL), recognized as an efficient learning approach, has achieved remarkable success across multiple fields and applications, including gaming, robotics, and autonomous vehicles. Classical single-agent reinforcement learning grapples with the imbalance of exploration and exploitation as well as limited generalization abilities. This methodology frequently leads to algorithms settling for suboptimal solutions that are tailored only to specific datasets. In this work, our aim is to train agent with efficient learning by decoupling exploration and utilization, so that agent can escaping the conundrum of suboptimal Solutions. In reinforcement learning, the previously imposed pessimistic punitive measures have deprived the model of its exploratory potential, resulting in diminished exploration capabilities. To address this, we have introduced an additional optimistic Actor to enhance the model's exploration ability, while employing a more constrained pessimistic Actor for performance evaluation. The above idea is implemented in the proposed OPARL (Optimistic and Pessimistic Actor Reinforcement Learning) algorithm. This unique amalgamation within the reinforcement learning paradigm fosters a more balanced and efficient approach. It facilitates the optimization of policies that concentrate on high-reward actions via pessimistic exploitation strategies while concurrently ensuring extensive state coverage through optimistic exploration. Empirical and theoretical investigations demonstrate that OPARL enhances agent capabilities in both utilization and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
5/13/2024

Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Guillermo Infante, David Kuric, Anders Jonsson, Vicenc{c} G'omez, Herke van Hoof
0
0
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
6/4/2024

Hybrid Inverse Reinforcement Learning
Juntao Ren, Gokul Swamy, Zhiwei Steven Wu, J. Andrew Bagnell, Sanjiban Choudhury
0
0
The inverse reinforcement learning approach to imitation learning is a double-edged sword. On the one hand, it can enable learning from a smaller number of expert demonstrations with more robustness to error compounding than behavioral cloning approaches. On the other hand, it requires that the learner repeatedly solve a computationally expensive reinforcement learning (RL) problem. Often, much of this computation is wasted searching over policies very dissimilar to the expert's. In this work, we propose using hybrid RL -- training on a mixture of online and expert data -- to curtail unnecessary exploration. Intuitively, the expert data focuses the learner on good states during training, which reduces the amount of exploration required to compute a strong policy. Notably, such an approach doesn't need the ability to reset the learner to arbitrary states in the environment, a requirement of prior work in efficient inverse RL. More formally, we derive a reduction from inverse RL to expert-competitive RL (rather than globally optimal RL) that allows us to dramatically reduce interaction during the inner policy search loop while maintaining the benefits of the IRL approach. This allows us to derive both model-free and model-based hybrid inverse RL algorithms with strong policy performance guarantees. Empirically, we find that our approaches are significantly more sample efficient than standard inverse RL and several other baselines on a suite of continuous control tasks.
6/6/2024