Efficient Reinforcement Learning via Decoupling Exploration and Utilization
2312.15965
0
0
Abstract
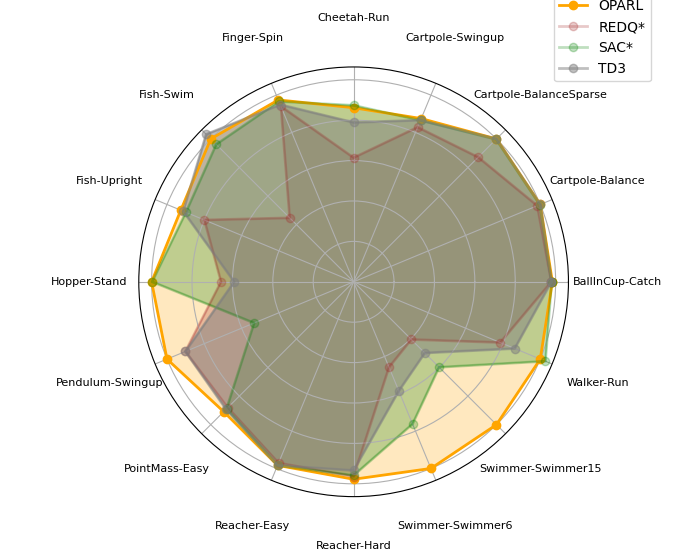
Reinforcement Learning (RL), recognized as an efficient learning approach, has achieved remarkable success across multiple fields and applications, including gaming, robotics, and autonomous vehicles. Classical single-agent reinforcement learning grapples with the imbalance of exploration and exploitation as well as limited generalization abilities. This methodology frequently leads to algorithms settling for suboptimal solutions that are tailored only to specific datasets. In this work, our aim is to train agent with efficient learning by decoupling exploration and utilization, so that agent can escaping the conundrum of suboptimal Solutions. In reinforcement learning, the previously imposed pessimistic punitive measures have deprived the model of its exploratory potential, resulting in diminished exploration capabilities. To address this, we have introduced an additional optimistic Actor to enhance the model's exploration ability, while employing a more constrained pessimistic Actor for performance evaluation. The above idea is implemented in the proposed OPARL (Optimistic and Pessimistic Actor Reinforcement Learning) algorithm. This unique amalgamation within the reinforcement learning paradigm fosters a more balanced and efficient approach. It facilitates the optimization of policies that concentrate on high-reward actions via pessimistic exploitation strategies while concurrently ensuring extensive state coverage through optimistic exploration. Empirical and theoretical investigations demonstrate that OPARL enhances agent capabilities in both utilization and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
Create account to get full access
Overview
- This paper presents a dual actor method for reinforcement learning that decouples exploration and exploitation, allowing for more effective learning.
- The method uses an "optimistic" actor to drive exploration and a "pessimistic" actor to guide exploitation, with the two actors trained separately but interacting during the learning process.
- The approach is evaluated on the DMControl benchmark, showing improved performance over existing reinforcement learning methods.
Plain English Explanation
The paper describes a new way of training reinforcement learning agents that aims to improve their ability to learn and perform well. Typical reinforcement learning methods try to balance exploration (trying new things) and exploitation (using what has been learned so far) during the learning process.
The authors propose a "dual actor" approach that separates these two objectives. One "optimistic" actor is responsible for encouraging the agent to explore and try new actions, while a separate "pessimistic" actor focuses on exploiting the agent's current knowledge to maximize rewards.
The two actors are trained independently but interact during the learning process. This decoupling of exploration and exploitation allows the agent to be more effective at both, leading to improved performance on challenging reinforcement learning benchmark tasks.
The paper evaluates this dual actor method on the DMControl benchmark, a suite of simulated control tasks, and shows it outperforms existing reinforcement learning algorithms like Proximal Policy Optimization and Evolutionary Reinforcement Learning.
Technical Explanation
The key innovation of this paper is the "dual actor" architecture, which decouples exploration and exploitation in reinforcement learning. Typically, a single policy or "actor" network must balance these two competing objectives during training.
In contrast, the authors propose using two separate actor networks: an "optimistic" actor that encourages exploration by overestimating the value of actions, and a "pessimistic" actor that focuses on exploitation by underestimating the value of actions. These two actors are trained independently using different loss functions, but interact during the learning process.
The optimistic actor is trained to maximize an "upper-confidence bound" (UCB) value, which includes both the expected reward and an exploration bonus. This encourages the agent to try new actions and explore the environment more effectively. The pessimistic actor, on the other hand, is trained to maximize the expected reward directly, focusing on exploiting the agent's current knowledge.
The authors evaluate this dual actor method on a range of DMControl benchmark tasks, showing improved performance over existing algorithms like Proximal Policy Optimization and Evolutionary Reinforcement Learning. They also provide ablation studies and analyses to better understand the contributions of the optimistic and pessimistic actors.
Critical Analysis
The dual actor method presented in this paper offers a promising approach to improving exploration and exploitation in reinforcement learning. By decoupling these two objectives, the authors demonstrate that agents can learn more effectively on challenging tasks.
However, the paper does not fully address the potential limitations of this approach. For example, the separate training of the optimistic and pessimistic actors could lead to instability or poor coordination between the two. There may also be scenarios where a more integrated exploration-exploitation strategy is preferable to the strict separation proposed here.
Additionally, the paper only evaluates the method on the DMControl benchmark, which, while challenging, may not capture the full range of real-world applications of reinforcement learning. Further research could explore the dual actor approach on more diverse task domains and investigate its scalability and robustness.
Overall, the dual actor method is a noteworthy contribution to the field of reinforcement learning, but additional work is needed to fully understand its strengths, limitations, and potential for broader applications.
Conclusion
This paper presents a novel "dual actor" approach to reinforcement learning that decouples exploration and exploitation. By training separate "optimistic" and "pessimistic" actors, the method is able to improve performance on challenging benchmark tasks compared to existing algorithms.
The key insight is that separating these two competing objectives can lead to more effective learning, as the optimistic actor drives exploration while the pessimistic actor focuses on exploiting the agent's current knowledge. While the paper demonstrates the potential of this approach, further research is needed to fully understand its limitations and explore its broader applications in real-world reinforcement learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Beyond Optimism: Exploration With Partially Observable Rewards
Simone Parisi, Alireza Kazemipour, Michael Bowling
0
0
Exploration in reinforcement learning (RL) remains an open challenge. RL algorithms rely on observing rewards to train the agent, and if informative rewards are sparse the agent learns slowly or may not learn at all. To improve exploration and reward discovery, popular algorithms rely on optimism. But what if sometimes rewards are unobservable, e.g., situations of partial monitoring in bandits and the recent formalism of monitored Markov decision process? In this case, optimism can lead to suboptimal behavior that does not explore further to collapse uncertainty. With this paper, we present a novel exploration strategy that overcomes the limitations of existing methods and guarantees convergence to an optimal policy even when rewards are not always observable. We further propose a collection of tabular environments for benchmarking exploration in RL (with and without unobservable rewards) and show that our method outperforms existing ones.
6/21/2024
A Pontryagin Perspective on Reinforcement Learning
Onno Eberhard, Claire Vernade, Michael Muehlebach
0
0
Reinforcement learning has traditionally focused on learning state-dependent policies to solve optimal control problems in a closed-loop fashion. In this work, we introduce the paradigm of open-loop reinforcement learning where a fixed action sequence is learned instead. We present three new algorithms: one robust model-based method and two sample-efficient model-free methods. Rather than basing our algorithms on Bellman's equation from dynamic programming, our work builds on Pontryagin's principle from the theory of open-loop optimal control. We provide convergence guarantees and evaluate all methods empirically on a pendulum swing-up task, as well as on two high-dimensional MuJoCo tasks, demonstrating remarkable performance compared to existing baselines.
5/29/2024
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
0
0
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
6/27/2024
🏅
Learning to Optimize for Reinforcement Learning
Qingfeng Lan, A. Rupam Mahmood, Shuicheng Yan, Zhongwen Xu
0
0
In recent years, by leveraging more data, computation, and diverse tasks, learned optimizers have achieved remarkable success in supervised learning, outperforming classical hand-designed optimizers. Reinforcement learning (RL) is essentially different from supervised learning, and in practice, these learned optimizers do not work well even in simple RL tasks. We investigate this phenomenon and identify two issues. First, the agent-gradient distribution is non-independent and identically distributed, leading to inefficient meta-training. Moreover, due to highly stochastic agent-environment interactions, the agent-gradients have high bias and variance, which increases the difficulty of learning an optimizer for RL. We propose pipeline training and a novel optimizer structure with a good inductive bias to address these issues, making it possible to learn an optimizer for reinforcement learning from scratch. We show that, although only trained in toy tasks, our learned optimizer can generalize to unseen complex tasks in Brax.
6/5/2024