Learning to Plan for Language Modeling from Unlabeled Data

0
Sign in to get full access
Overview
- This paper explores a new approach to language modeling that aims to learn planning capabilities directly from unlabeled data.
- The key idea is to incorporate planning mechanisms into the language model architecture, allowing it to learn how to plan and reason about future outputs during the training process.
- The researchers hypothesize that this planning-aware approach can lead to improved language modeling performance and more coherent and contextually-appropriate output.
Plain English Explanation
The paper presents a novel technique for training language models, which are AI systems that can generate human-like text. Traditional language models are trained to simply predict the next word in a sequence, based on the words that came before it. However, the researchers behind this paper believe that language models could be even more powerful if they were also trained to "plan" their outputs - to think ahead and reason about the implications of what they're about to say.
[The key idea is to incorporate planning mechanisms into the language model architecture, allowing it to learn how to plan and reason about future outputs during the training process.]
The researchers hypothesize that a language model with built-in planning capabilities would be able to generate more coherent, contextually-appropriate text. For example, if the model is generating a story, it might be able to anticipate how a character's actions in one paragraph will impact the rest of the narrative, leading to a more cohesive and believable outcome.
[The researchers hypothesize that this planning-aware approach can lead to improved language modeling performance and more coherent and contextually-appropriate output.]
To test this idea, the researchers developed a new language model architecture that includes specialized "planning" components. During training, the model learns to use these planning components to reason about and optimize its future outputs, in addition to just predicting the next word.
Technical Explanation
The paper introduces a new language modeling approach called "Planning-Aware Language Modeling" (PALM). The core innovation is the incorporation of planning mechanisms directly into the language model architecture.
Specifically, the PALM model includes a "Planning Module" that operates in parallel with the standard language model components. This Planning Module is responsible for generating a plan or "roadmap" for the future outputs of the language model, based on the current input and hidden state.
[The key idea is to incorporate planning mechanisms into the language model architecture, allowing it to learn how to plan and reason about future outputs during the training process.]
During training, the Planning Module is trained to output a plan that maximizes the likelihood of the language model's future outputs. In other words, the model learns to plan ahead in a way that leads to more coherent and contextually-appropriate text generation.
The researchers evaluate the PALM approach on several language modeling benchmarks, including text generation and question answering tasks. They find that the planning-aware PALM model outperforms standard language models, indicating that the ability to plan and reason about future outputs can indeed lead to performance improvements.
[The researchers hypothesize that this planning-aware approach can lead to improved language modeling performance and more coherent and contextually-appropriate output.]
Critical Analysis
The paper presents a compelling approach to improving language modeling by incorporating planning mechanisms. The key strength is the intuition that language models could be more powerful if they were trained to reason about the implications and consequences of their outputs, rather than just predicting the next word.
However, the paper does not address some potential limitations or challenges with this approach. For example, the computational overhead of the Planning Module may make the PALM model less efficient or scalable than standard language models. Additionally, the paper does not explore how the planning capabilities generalize to open-ended, real-world language generation tasks beyond the specific benchmarks evaluated.
[The paper does not address some potential limitations or challenges with this approach. For example, the computational overhead of the Planning Module may make the PALM model less efficient or scalable than standard language models.]
Further research would be needed to fully understand the strengths, weaknesses, and broader applicability of the planning-aware language modeling approach presented in this paper.
Conclusion
This paper introduces a novel technique for training language models that incorporates planning mechanisms directly into the model architecture. The key idea is to enable the language model to learn how to plan and reason about its future outputs during the training process, rather than just predicting the next word.
[The key idea is to incorporate planning mechanisms into the language model architecture, allowing it to learn how to plan and reason about future outputs during the training process.]
The researchers find that this planning-aware approach can lead to improved language modeling performance and more coherent, contextually-appropriate text generation. While the paper does not address all the potential limitations, it presents an intriguing new direction for advancing the state of the art in language modeling and generation.
[The researchers hypothesize that this planning-aware approach can lead to improved language modeling performance and more coherent and contextually-appropriate output.]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Plan for Language Modeling from Unlabeled Data
Nathan Cornille, Marie-Francine Moens, Florian Mai
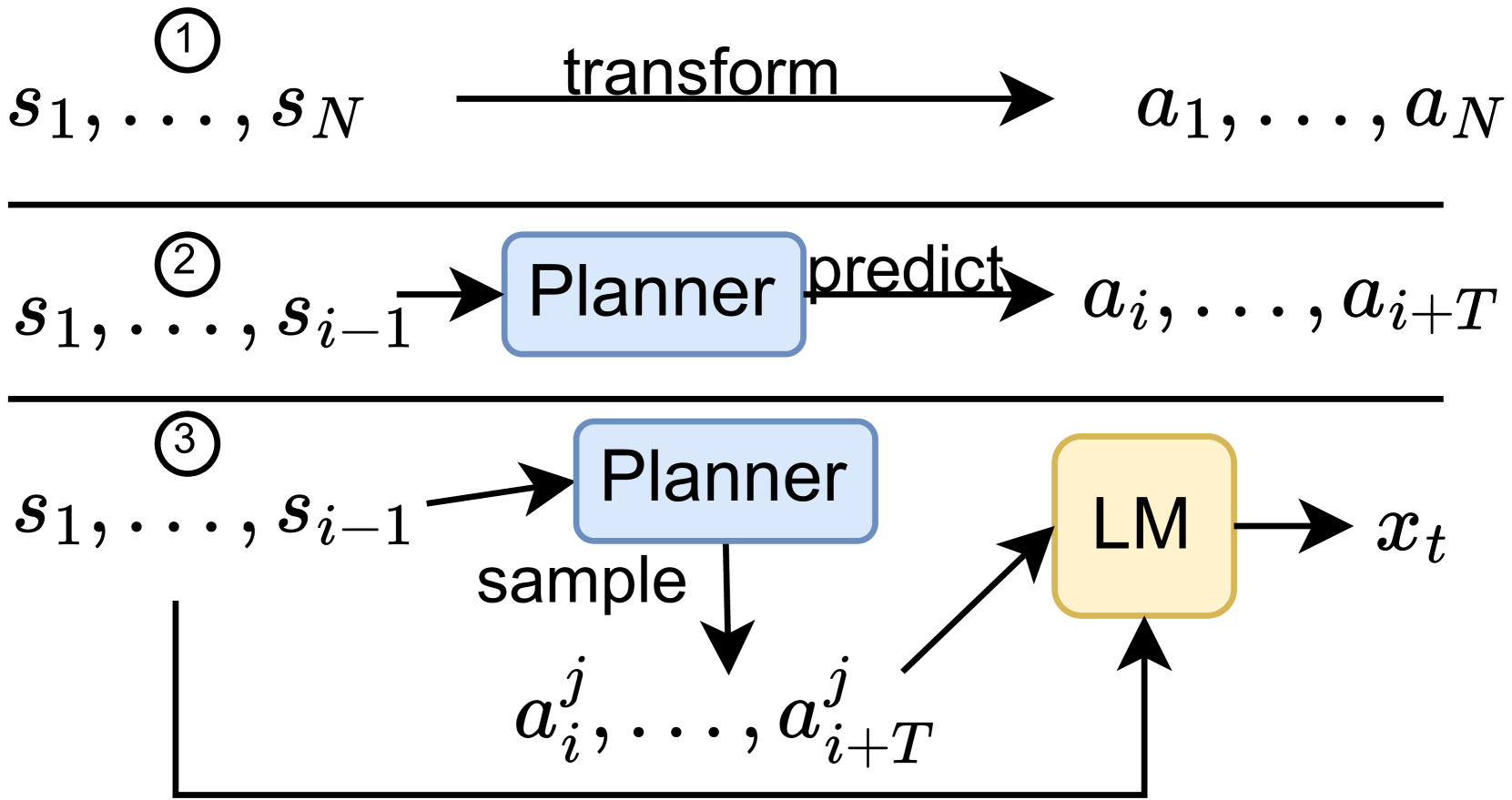
By training to predict the next token in an unlabeled corpus, large language models learn to perform many tasks without any labeled data. However, their next-token-prediction objective arguably limits their performance in scenarios that require planning, such as writing a coherent article. In this paper, we train a module for planning the future writing process via a self-supervised learning objective. Given the textual context, this planning module learns to predict future abstract writing actions, which correspond to centroids in a clustered text embedding space. By conditioning on these actions, our model extends the successful language model formula to more abstract planning in an unsupervised way. Empirically, we demonstrate that our method improves language modeling performance in general, particularly with respect to the text structure. Because our framework uses a planner module that is unsupervised and external to the language model, new planner modules can be trained at large scale and easily be shared with the community.
Read more8/1/2024
0
Learning to Plan Long-Term for Language Modeling
Florian Mai, Nathan Cornille, Marie-Francine Moens
Modern language models predict the next token in the sequence by considering the past text through a powerful function such as attention. However, language models have no explicit mechanism that allows them to spend computation time for planning long-distance future text, leading to a suboptimal token prediction. In this paper, we propose a planner that predicts a latent plan for many sentences into the future. By sampling multiple plans at once, we condition the language model on an accurate approximation of the distribution of text continuations, which leads to better next token prediction accuracy. In effect, this allows trading computation time for prediction accuracy.
Read more9/4/2024
💬
0
What's the Plan? Evaluating and Developing Planning-Aware Techniques for Language Models
Eran Hirsch, Guy Uziel, Ateret Anaby-Tavor
Planning is a fundamental task in artificial intelligence that involves finding a sequence of actions that achieve a specified goal in a given environment. Large language models (LLMs) are increasingly used for applications that require planning capabilities, such as web or embodied agents. In line with recent studies, we demonstrate through experimentation that LLMs lack necessary skills required for planning. Based on these observations, we advocate for the potential of a hybrid approach that combines LLMs with classical planning methodology. Then, we introduce SimPlan, a novel hybrid-method, and evaluate its performance in a new challenging setup. Our extensive experiments across various planning domains demonstrate that SimPlan significantly outperforms existing LLM-based planners.
Read more5/24/2024

0
Unlocking the Future: Exploring Look-Ahead Planning Mechanistic Interpretability in Large Language Models
Tianyi Men, Pengfei Cao, Zhuoran Jin, Yubo Chen, Kang Liu, Jun Zhao
Planning, as the core module of agents, is crucial in various fields such as embodied agents, web navigation, and tool using. With the development of large language models (LLMs), some researchers treat large language models as intelligent agents to stimulate and evaluate their planning capabilities. However, the planning mechanism is still unclear. In this work, we focus on exploring the look-ahead planning mechanism in large language models from the perspectives of information flow and internal representations. First, we study how planning is done internally by analyzing the multi-layer perception (MLP) and multi-head self-attention (MHSA) components at the last token. We find that the output of MHSA in the middle layers at the last token can directly decode the decision to some extent. Based on this discovery, we further trace the source of MHSA by information flow, and we reveal that MHSA mainly extracts information from spans of the goal states and recent steps. According to information flow, we continue to study what information is encoded within it. Specifically, we explore whether future decisions have been encoded in advance in the representation of flow. We demonstrate that the middle and upper layers encode a few short-term future decisions to some extent when planning is successful. Overall, our research analyzes the look-ahead planning mechanisms of LLMs, facilitating future research on LLMs performing planning tasks.
Read more6/26/2024