Unlocking the Future: Exploring Look-Ahead Planning Mechanistic Interpretability in Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of look-ahead planning techniques to improve the mechanistic interpretability of large language models.
- The researchers conduct experiments to understand how language models can learn to plan ahead and reason about the future consequences of their actions.
- The insights from this research could lead to more transparent and accountable AI systems that can explain their decision-making processes.
Plain English Explanation
Large language models, such as GPT-3, have become increasingly powerful at understanding and generating human-like text. However, these models can often behave in unpredictable or opaque ways, making it difficult to understand how they arrive at their outputs.
This research paper investigates the use of "look-ahead planning" as a way to improve the interpretability of these language models. The idea is that by training the models to reason about the future consequences of their actions, they may become more transparent and able to explain their decision-making process.
For example, imagine a language model that is asked to write a story. Instead of simply generating the next sentence without considering the broader context, a look-ahead planning model would try to anticipate how its current choice of words might shape the overall narrative and long-term trajectory of the story. This type of forward-thinking could help make the model's reasoning more accessible to human users.
The researchers conducted a series of experiments to test different approaches to incorporating look-ahead planning into language models. They explored techniques like reinforcement learning and multi-task training, which aim to imbue the models with a sense of "planning awareness" and the ability to consider future outcomes.
The insights from this research could have important implications for the development of more transparent and accountable AI systems. By making language models' decision-making processes more interpretable, we may be able to build AI assistants that can better explain their actions and align with human values and intentions.
Technical Explanation
The paper begins by highlighting the challenge of mechanistic interpretability in large language models. The authors note that while these models have become extremely capable at language tasks, their inner workings are often opaque, making it difficult to understand how they arrive at their outputs.
To address this, the researchers explore the use of look-ahead planning as a way to improve the interpretability of language models. The core idea is to train the models to reason about the future consequences of their actions, rather than just generating text reactively.
The paper describes several experimental approaches to incorporating look-ahead planning:
-
Reinforcement Learning: The authors train the language model using reinforcement learning, where the model is rewarded for making choices that lead to desirable future outcomes.
-
Multi-Task Training: The model is trained on both the primary language task (e.g., text generation) as well as an additional "planning" task, where the model must predict future states of the environment.
-
Prompt-based Planning: The authors explore ways of directly incorporating planning-related prompts into the language model's input, prompting it to consider future outcomes.
Through these experiments, the researchers aim to imbue the language models with a sense of "planning awareness" - the ability to reason about the long-term implications of their actions and communicate this reasoning to human users.
Critical Analysis
The paper presents a compelling approach to improving the interpretability of large language models, but it also acknowledges several limitations and areas for further research.
One key concern is the potential trade-off between improved interpretability and overall model performance. The authors note that the planning-focused training approaches may come at the cost of slightly degraded performance on the primary language tasks. Further research is needed to find the right balance and ensure that the planning capabilities do not come at the expense of the model's core functionality.
Additionally, the paper highlights the challenge of evaluating the effectiveness of the proposed planning-aware techniques. Assessing the models' ability to reason about future outcomes and communicate their decision-making process is inherently difficult and may require the development of new benchmarking frameworks.
Another area for further exploration is the integration of these planning-aware language models into interactive, real-world applications. The paper focuses on the underlying technical approaches, but more research is needed to understand how these models might perform in dynamic, open-ended environments where the ability to plan and explain one's actions is particularly crucial.
Finally, the paper's approach to incorporating planning capabilities could potentially be combined with other techniques, such as graph-based reasoning or multi-agent coordination, to further enhance the language models' transparency and decision-making abilities.
Conclusion
This paper presents an intriguing exploration of using look-ahead planning to improve the mechanistic interpretability of large language models. By training models to reason about the future consequences of their actions, the researchers aim to make these powerful AI systems more transparent and accountable.
The insights from this work could have significant implications for the development of AI assistants and other interactive technologies that must operate in complex, real-world environments. As language models continue to grow in capability and influence, the need for interpretable and aligned decision-making processes becomes increasingly important. This research represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unlocking the Future: Exploring Look-Ahead Planning Mechanistic Interpretability in Large Language Models
Tianyi Men, Pengfei Cao, Zhuoran Jin, Yubo Chen, Kang Liu, Jun Zhao
Planning, as the core module of agents, is crucial in various fields such as embodied agents, web navigation, and tool using. With the development of large language models (LLMs), some researchers treat large language models as intelligent agents to stimulate and evaluate their planning capabilities. However, the planning mechanism is still unclear. In this work, we focus on exploring the look-ahead planning mechanism in large language models from the perspectives of information flow and internal representations. First, we study how planning is done internally by analyzing the multi-layer perception (MLP) and multi-head self-attention (MHSA) components at the last token. We find that the output of MHSA in the middle layers at the last token can directly decode the decision to some extent. Based on this discovery, we further trace the source of MHSA by information flow, and we reveal that MHSA mainly extracts information from spans of the goal states and recent steps. According to information flow, we continue to study what information is encoded within it. Specifically, we explore whether future decisions have been encoded in advance in the representation of flow. We demonstrate that the middle and upper layers encode a few short-term future decisions to some extent when planning is successful. Overall, our research analyzes the look-ahead planning mechanisms of LLMs, facilitating future research on LLMs performing planning tasks.
Read more6/26/2024
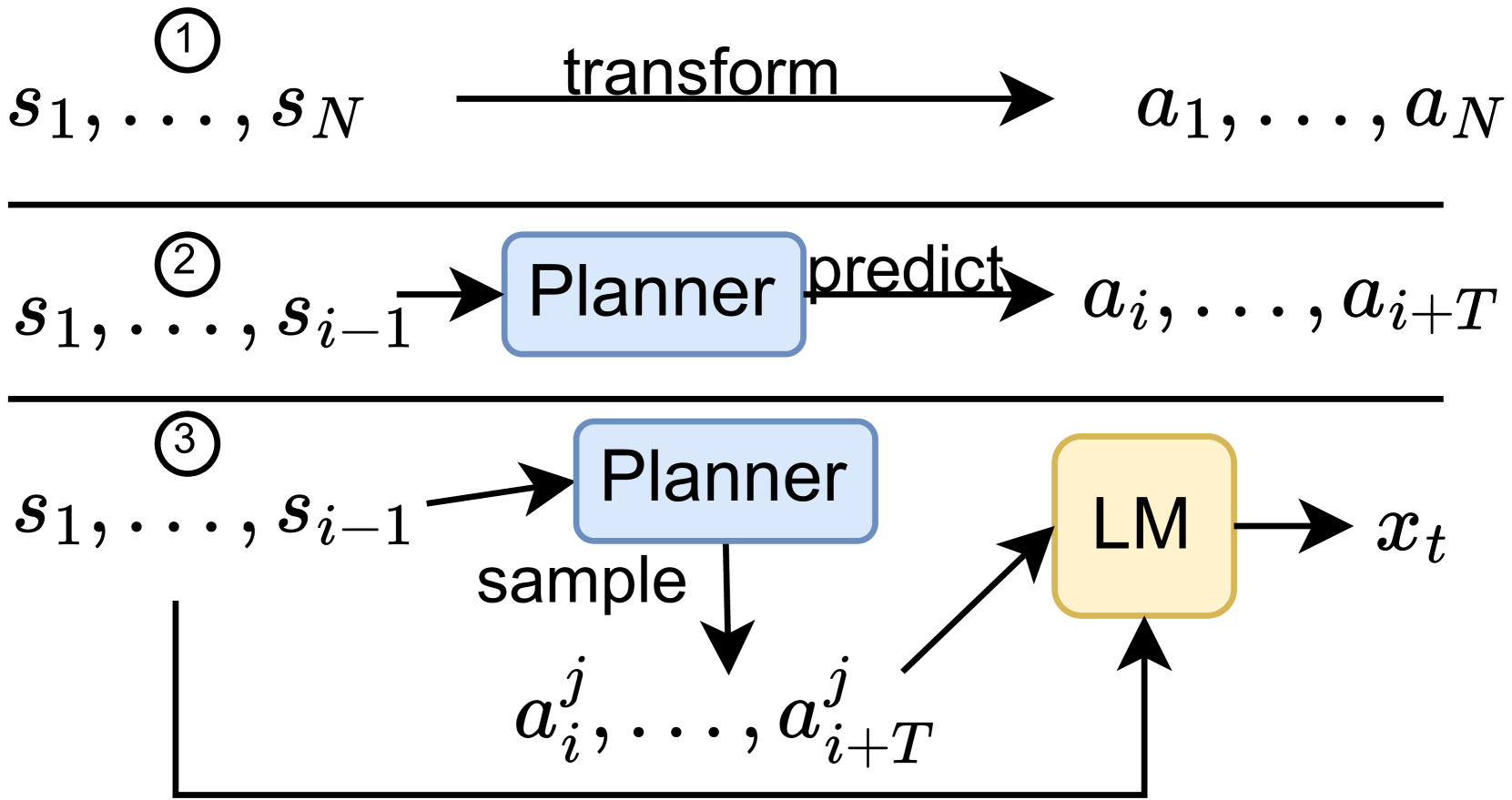
0
Learning to Plan Long-Term for Language Modeling
Florian Mai, Nathan Cornille, Marie-Francine Moens
Modern language models predict the next token in the sequence by considering the past text through a powerful function such as attention. However, language models have no explicit mechanism that allows them to spend computation time for planning long-distance future text, leading to a suboptimal token prediction. In this paper, we propose a planner that predicts a latent plan for many sentences into the future. By sampling multiple plans at once, we condition the language model on an accurate approximation of the distribution of text continuations, which leads to better next token prediction accuracy. In effect, this allows trading computation time for prediction accuracy.
Read more9/4/2024
💬
0
LASP: Surveying the State-of-the-Art in Large Language Model-Assisted AI Planning
Haoming Li, Zhaoliang Chen, Jonathan Zhang, Fei Liu
Effective planning is essential for the success of any task, from organizing a vacation to routing autonomous vehicles and developing corporate strategies. It involves setting goals, formulating plans, and allocating resources to achieve them. LLMs are particularly well-suited for automated planning due to their strong capabilities in commonsense reasoning. They can deduce a sequence of actions needed to achieve a goal from a given state and identify an effective course of action. However, it is frequently observed that plans generated through direct prompting often fail upon execution. Our survey aims to highlight the existing challenges in planning with language models, focusing on key areas such as embodied environments, optimal scheduling, competitive and cooperative games, task decomposition, reasoning, and planning. Through this study, we explore how LLMs transform AI planning and provide unique insights into the future of LM-assisted planning.
Read more9/4/2024
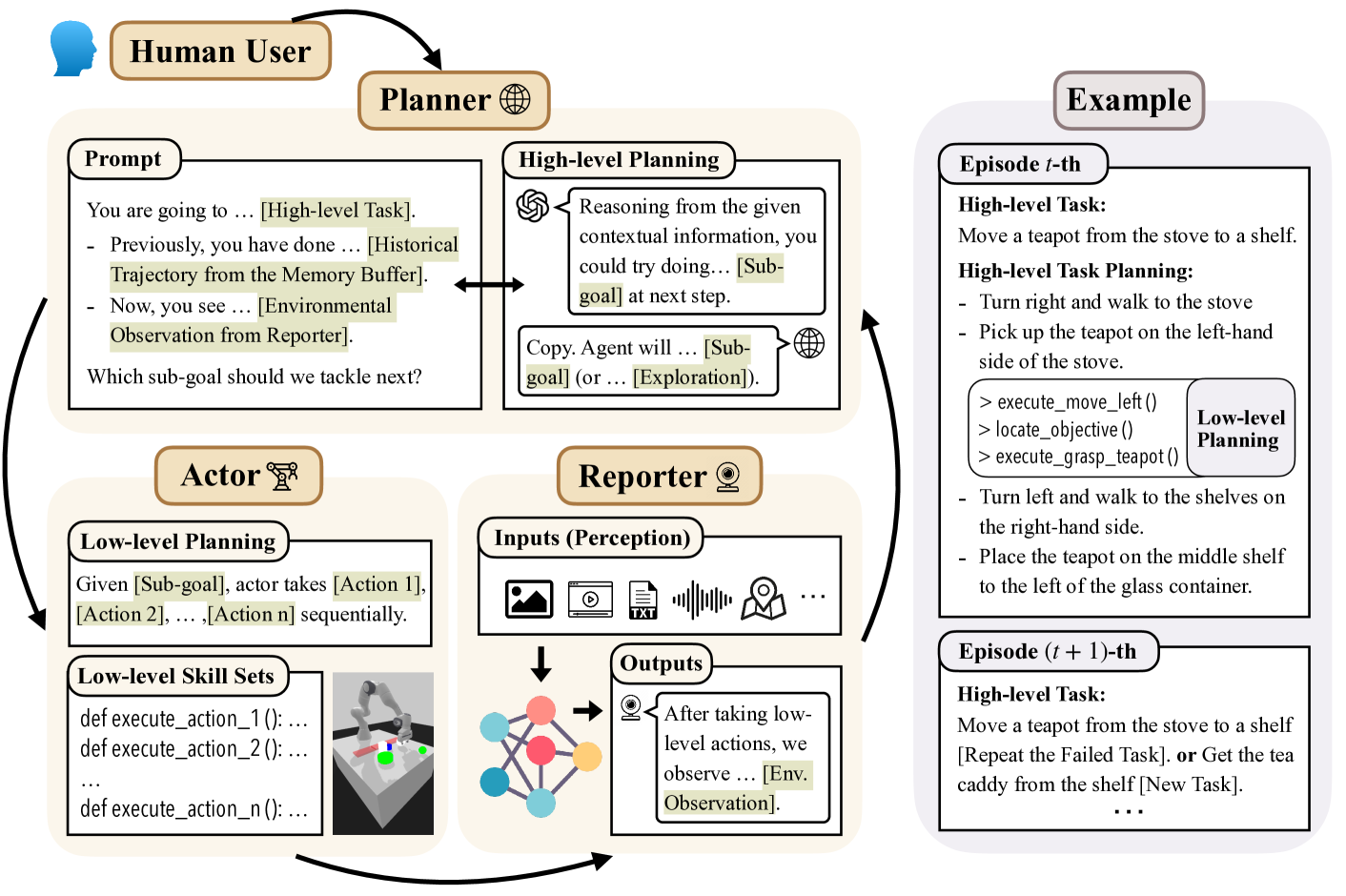
0
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Read more7/23/2024