Learning to Play Air Hockey with Model-Based Deep Reinforcement Learning

0

Sign in to get full access
Overview
- This paper explores how to train an AI agent to play air hockey using model-based deep reinforcement learning.
- The researchers developed a simulation environment to train the agent and tested its performance on a real-world air hockey table.
- The agent was able to learn complex air hockey skills, such as scoring goals and blocking shots, by learning an internal model of the physics and dynamics of the game.
Plain English Explanation
The researchers in this paper wanted to teach an AI system how to play air hockey. They created a simulated air hockey environment where the AI could practice and learn the game. The key idea was to have the AI build an internal model of how the air hockey puck moves and interacts with the table and paddles. This allowed the AI to plan its actions more effectively, like [learning-robot-soccer-from-egocentric-vision-deep] and [learning-agile-soccer-skills-bipedal-robot-deep], rather than just reacting to the current state of the game.
By training the AI in this simulated environment, it was able to develop sophisticated air hockey skills, such as aiming shots precisely to score goals and positioning its paddle to block incoming shots. This suggests that model-based reinforcement learning, where the AI learns an internal model of the environment, can be a powerful approach for training agents to excel at complex real-world tasks, [imitation-game-model-based-imitation-learning-deep] and [advancing-household-robotics-deep-interactive-reinforcement-learning].
The researchers then tested the trained AI agent on a real air hockey table to see how well it could apply its learned skills in the physical world. This [robot-air-hockey-manipulation-testbed-robot-learning] setup allowed them to evaluate the effectiveness of the model-based training approach in a realistic setting.
Technical Explanation
The researchers developed a simulation environment to train their air hockey agent using model-based deep reinforcement learning. The agent's goal was to score points by hitting the puck into the opponent's goal, while also defending its own goal from the opponent's shots.
The key innovation was that the agent learned an internal model of the air hockey dynamics, including how the puck and paddles interact with the table. This allowed the agent to plan its actions more effectively, rather than just reacting to the current state of the game. The agent's policy was represented by a deep neural network that took in the current state of the game (e.g., puck and paddle positions) and outputted the optimal action (e.g., paddle movement) to take.
The researchers trained the agent by having it play many simulated games and optimizing its policy to maximize the expected cumulative reward (i.e., points scored). They used a model-based reinforcement learning algorithm that alternated between learning the environment model and learning the optimal policy given that model.
Once the agent was trained in simulation, the researchers tested its performance on a real-world air hockey table. They found that the agent was able to successfully transfer its learned skills to the physical environment, demonstrating the effectiveness of the model-based training approach.
Critical Analysis
The researchers' approach of using model-based deep reinforcement learning to train an air hockey agent is a promising step towards developing intelligent robotic systems that can excel at complex real-world tasks. By learning an internal model of the game dynamics, the agent was able to plan its actions more strategically and develop sophisticated air hockey skills.
However, the paper does not provide a detailed analysis of the agent's performance compared to human players or other AI approaches. It would be valuable to understand the strengths and weaknesses of the model-based approach relative to other techniques, such as purely data-driven reinforcement learning or imitation learning.
Additionally, the paper does not address the potential limitations of training in a simulated environment and transferring the learned skills to the physical world. While the researchers demonstrated successful transfer to the real air hockey table, there may be inherent challenges in capturing all the nuances of the real-world dynamics in the simulation.
Further research could explore ways to improve the fidelity of the simulation or develop techniques to better bridge the gap between the simulated and physical environments. Addressing these challenges could lead to even more robust and capable robotic systems that can excel at a wide range of complex tasks.
Conclusion
This paper presents a novel approach for training an AI agent to play air hockey using model-based deep reinforcement learning. By learning an internal model of the game dynamics, the agent was able to develop sophisticated air hockey skills, such as scoring goals and blocking shots, and successfully transfer these skills to a real-world air hockey table.
The researchers' work demonstrates the potential of model-based reinforcement learning for training intelligent robotic systems to excel at complex real-world tasks. This approach could have broader applications in fields like [robot-air-hockey-manipulation-testbed-robot-learning], [learning-agile-soccer-skills-bipedal-robot-deep], [learning-robot-soccer-from-egocentric-vision-deep], [imitation-game-model-based-imitation-learning-deep], and [advancing-household-robotics-deep-interactive-reinforcement-learning], where robots need to interact with dynamic environments and develop advanced motor skills.
Further research is needed to fully understand the strengths and limitations of model-based reinforcement learning and explore ways to improve the realism of simulation environments and the transfer of learned skills to the physical world. Nevertheless, this paper represents an important step forward in the development of intelligent robotic systems that can master complex real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Play Air Hockey with Model-Based Deep Reinforcement Learning
Andrej Orsula
In the context of addressing the Robot Air Hockey Challenge 2023, we investigate the applicability of model-based deep reinforcement learning to acquire a policy capable of autonomously playing air hockey. Our agents learn solely from sparse rewards while incorporating self-play to iteratively refine their behaviour over time. The robotic manipulator is interfaced using continuous high-level actions for position-based control in the Cartesian plane while having partial observability of the environment with stochastic transitions. We demonstrate that agents are prone to overfitting when trained solely against a single playstyle, highlighting the importance of self-play for generalization to novel strategies of unseen opponents. Furthermore, the impact of the imagination horizon is explored in the competitive setting of the highly dynamic game of air hockey, with longer horizons resulting in more stable learning and better overall performance.
Read more6/4/2024

0
Robot Air Hockey: A Manipulation Testbed for Robot Learning with Reinforcement Learning
Caleb Chuck, Carl Qi, Michael J. Munje, Shuozhe Li, Max Rudolph, Chang Shi, Siddhant Agarwal, Harshit Sikchi, Abhinav Peri, Sarthak Dayal, Evan Kuo, Kavan Mehta, Anthony Wang, Peter Stone, Amy Zhang, Scott Niekum
Reinforcement Learning is a promising tool for learning complex policies even in fast-moving and object-interactive domains where human teleoperation or hard-coded policies might fail. To effectively reflect this challenging category of tasks, we introduce a dynamic, interactive RL testbed based on robot air hockey. By augmenting air hockey with a large family of tasks ranging from easy tasks like reaching, to challenging ones like pushing a block by hitting it with a puck, as well as goal-based and human-interactive tasks, our testbed allows a varied assessment of RL capabilities. The robot air hockey testbed also supports sim-to-real transfer with three domains: two simulators of increasing fidelity and a real robot system. Using a dataset of demonstration data gathered through two teleoperation systems: a virtualized control environment, and human shadowing, we assess the testbed with behavior cloning, offline RL, and RL from scratch.
Read more5/7/2024
🤿
9
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Tuomas Haarnoja, Ben Moran, Guy Lever, Sandy H. Huang, Dhruva Tirumala, Jan Humplik, Markus Wulfmeier, Saran Tunyasuvunakool, Noah Y. Siegel, Roland Hafner, Michael Bloesch, Kristian Hartikainen, Arunkumar Byravan, Leonard Hasenclever, Yuval Tassa, Fereshteh Sadeghi, Nathan Batchelor, Federico Casarini, Stefano Saliceti, Charles Game, Neil Sreendra, Kushal Patel, Marlon Gwira, Andrea Huber, Nicole Hurley, Francesco Nori, Raia Hadsell, Nicolas Heess
We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. The resulting agent exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and it transitions between them in a smooth, stable, and efficient manner. The agent's locomotion and tactical behavior adapts to specific game contexts in a way that would be impractical to manually design. The agent also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. Our agent was trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer. Although the robots are inherently fragile, basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way -- well beyond what is intuitively expected from the robot. Indeed, in experiments, they walked 181% faster, turned 302% faster, took 63% less time to get up, and kicked a ball 34% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives.
Read more4/12/2024
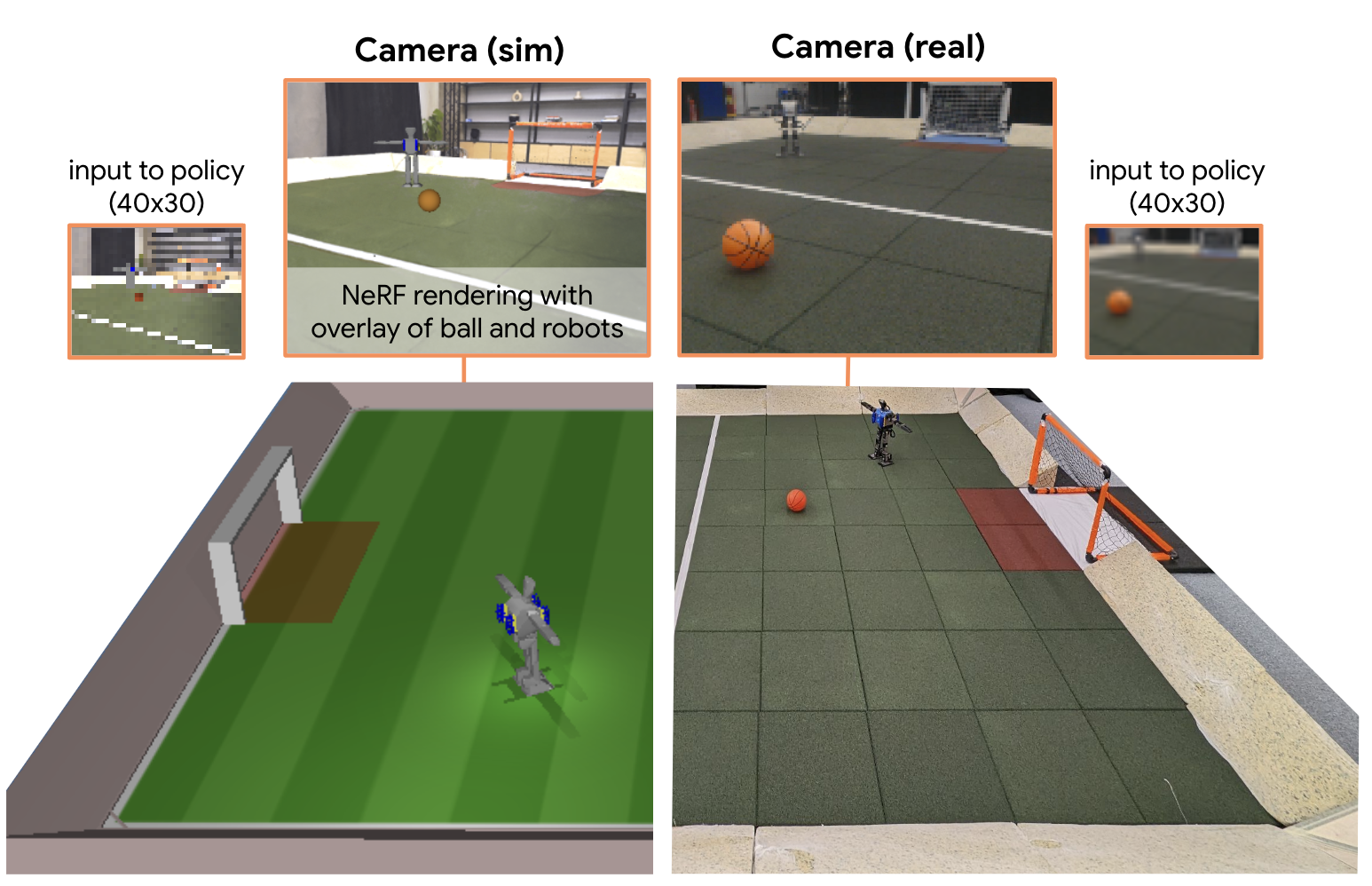
0
Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
Dhruva Tirumala, Markus Wulfmeier, Ben Moran, Sandy Huang, Jan Humplik, Guy Lever, Tuomas Haarnoja, Leonard Hasenclever, Arunkumar Byravan, Nathan Batchelor, Neil Sreendra, Kushal Patel, Marlon Gwira, Francesco Nori, Martin Riedmiller, Nicolas Heess
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Read more5/7/2024