Learning to Select the Best Forecasting Tasks for Clinical Outcome Prediction

0
Sign in to get full access
Overview
- The paper discusses a method for learning to select the best forecasting tasks for clinical outcome prediction.
- The key idea is to learn which forecasting tasks are most useful for predicting clinical outcomes, rather than manually choosing them.
- The method involves training a neural network to predict the performance of different forecasting tasks on held-out data, and then using this to choose the best tasks.
Plain English Explanation
The paper presents a way to automatically figure out which forecasting tasks are the most helpful for predicting important clinical outcomes, like whether a patient will have a good or bad healthcare result. Rather than relying on human experts to choose the forecasting tasks, the approach uses a neural network to learn which tasks work best.
The neural network is trained to look at the data from past patients and predict how well different forecasting tasks would do at predicting the clinical outcome for those patients. Once the network has learned this, it can be used to select the forecasting tasks that are likely to be the most useful for making predictions on new patients. This helps ensure that the most relevant and powerful forecasting capabilities are used, without requiring manual effort to choose them.
Technical Explanation
The paper introduces a method for Learning to Select the Best Forecasting Tasks for Clinical Outcome Prediction. The key idea is to train a neural network to predict the performance of different forecasting tasks on held-out data, and then use this to automatically select the best tasks for predicting clinical outcomes.
The neural network is trained on a dataset of past patients, where each patient has a set of clinical features and a known clinical outcome. The network is tasked with predicting how well different forecasting models would perform at predicting the clinical outcome for each patient, based on the patient's features.
Once the network has learned to predict forecasting performance, it can be used to select the best set of forecasting tasks for a new patient cohort. By choosing the tasks that the network predicts will work best, the authors show that they can achieve better clinical outcome prediction accuracy compared to manually selected forecasting tasks.
Critical Analysis
The paper presents a thoughtful approach to the challenge of selecting the most relevant forecasting tasks for clinical outcome prediction. By learning to predict forecasting performance, the method avoids the need for manual task selection, which can be time-consuming and prone to human bias.
However, the paper does acknowledge some limitations and areas for further research. For example, the performance of the method may be sensitive to the quality and diversity of the training data used to learn the forecasting task selection. Additionally, the paper does not explore the interpretability of the learned forecasting task selection, which could be an important consideration in a clinical setting.
Overall, the paper presents a promising approach that could help improve the reliability and efficiency of clinical outcome prediction models. Further research on the robustness and explainability of the method would be valuable contributions to the field.
Conclusion
The paper introduces a novel method for automatically selecting the most useful forecasting tasks for predicting clinical outcomes. By training a neural network to predict forecasting performance, the approach avoids the need for manual task selection and can achieve better predictive accuracy.
This work represents an important step towards more reliable and efficient clinical outcome prediction models, which could have significant impacts on healthcare decision-making and patient outcomes. Further research on the limitations and interpretability of the method could help strengthen its real-world applicability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Select the Best Forecasting Tasks for Clinical Outcome Prediction
Yuan Xue, Nan Du, Anne Mottram, Martin Seneviratne, Andrew M. Dai
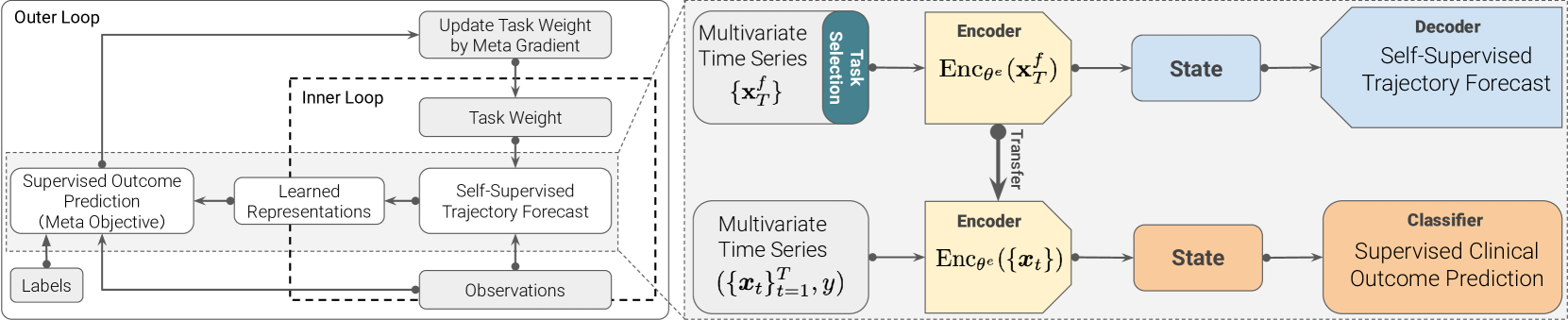
We propose to meta-learn an a self-supervised patient trajectory forecast learning rule by meta-training on a meta-objective that directly optimizes the utility of the patient representation over the subsequent clinical outcome prediction. This meta-objective directly targets the usefulness of a representation generated from unlabeled clinical measurement forecast for later supervised tasks. The meta-learned can then be directly used in target risk prediction, and the limited available samples can be used for further fine-tuning the model performance. The effectiveness of our approach is tested on a real open source patient EHR dataset MIMIC-III. We are able to demonstrate that our attention-based patient state representation approach can achieve much better performance for predicting target risk with low resources comparing with both direct supervised learning and pretraining with all-observation trajectory forecast.
Read more7/30/2024

0
SMART: Towards Pre-trained Missing-Aware Model for Patient Health Status Prediction
Zhihao Yu, Xu Chu, Yujie Jin, Yasha Wang, Junfeng Zhao
Electronic health record (EHR) data has emerged as a valuable resource for analyzing patient health status. However, the prevalence of missing data in EHR poses significant challenges to existing methods, leading to spurious correlations and suboptimal predictions. While various imputation techniques have been developed to address this issue, they often obsess unnecessary details and may introduce additional noise when making clinical predictions. To tackle this problem, we propose SMART, a Self-Supervised Missing-Aware RepresenTation Learning approach for patient health status prediction, which encodes missing information via elaborated attentions and learns to impute missing values through a novel self-supervised pre-training approach that reconstructs missing data representations in the latent space. By adopting missing-aware attentions and focusing on learning higher-order representations, SMART promotes better generalization and robustness to missing data. We validate the effectiveness of SMART through extensive experiments on six EHR tasks, demonstrating its superiority over state-of-the-art methods.
Read more5/16/2024

0
Automated Multi-Task Learning for Joint Disease Prediction on Electronic Health Records
Suhan Cui, Prasenjit Mitra
In the realm of big data and digital healthcare, Electronic Health Records (EHR) have become a rich source of information with the potential to improve patient care and medical research. In recent years, machine learning models have proliferated for analyzing EHR data to predict patients future health conditions. Among them, some studies advocate for multi-task learning (MTL) to jointly predict multiple target diseases for improving the prediction performance over single task learning. Nevertheless, current MTL frameworks for EHR data have significant limitations due to their heavy reliance on human experts to identify task groups for joint training and design model architectures. To reduce human intervention and improve the framework design, we propose an automated approach named AutoDP, which can search for the optimal configuration of task grouping and architectures simultaneously. To tackle the vast joint search space encompassing task combinations and architectures, we employ surrogate model-based optimization, enabling us to efficiently discover the optimal solution. Experimental results on real-world EHR data demonstrate the efficacy of the proposed AutoDP framework. It achieves significant performance improvements over both hand-crafted and automated state-of-the-art methods, also maintains a feasible search cost at the same time.
Read more5/31/2024

0
Dynamic feature selection in medical predictive monitoring by reinforcement learning
Yutong Chen, Jiandong Gao, Ji Wu
In this paper, we investigate dynamic feature selection within multivariate time-series scenario, a common occurrence in clinical prediction monitoring where each feature corresponds to a bio-test result. Many existing feature selection methods fall short in effectively leveraging time-series information, primarily because they are designed for static data. Our approach addresses this limitation by enabling the selection of time-varying feature subsets for each patient. Specifically, we employ reinforcement learning to optimize a policy under maximum cost restrictions. The prediction model is subsequently updated using synthetic data generated by trained policy. Our method can seamlessly integrate with non-differentiable prediction models. We conducted experiments on a sizable clinical dataset encompassing regression and classification tasks. The results demonstrate that our approach outperforms strong feature selection baselines, particularly when subjected to stringent cost limitations. Code will be released once paper is accepted.
Read more5/31/2024