SMART: Towards Pre-trained Missing-Aware Model for Patient Health Status Prediction

0

Sign in to get full access
Overview
- The paper proposes a pre-trained missing-aware model called SMART for predicting patient health status.
- SMART aims to handle missing data in electronic health records (EHRs) by leveraging prototype representations and adaptive attention mechanisms.
- The model is pre-trained on a large EHR dataset and can then be fine-tuned for specific healthcare prediction tasks.
Plain English Explanation
Electronic health records (EHRs) contain a wealth of information about patients' medical history, treatments, and health status. However, EHR data is often incomplete, with some patient information missing. This can make it challenging to use the data for tasks like predicting a patient's future health status.
The researchers behind the SMART model have developed a way to address this issue. SMART is a pre-trained machine learning model that is designed to work with EHR data that has missing information. It does this by leveraging prototype representations and adaptive attention mechanisms to extract relevant information from the available data.
By pre-training SMART on a large dataset of EHRs, the researchers have created a model that can be fine-tuned for specific healthcare prediction tasks, such as predicting a patient's next diagnosis or imputing missing data. This can help healthcare providers make more informed decisions and improve the predictive modeling of electronic health data.
Technical Explanation
The SMART model is designed to address the challenge of missing data in electronic health records (EHRs) by leveraging prototype representations and adaptive attention mechanisms.
The researchers first pre-train SMART on a large dataset of EHRs, which allows the model to learn general patterns and representations that are useful for healthcare prediction tasks. This pre-training step is crucial, as it enables SMART to be fine-tuned for specific tasks, such as predicting a patient's future health status or imputing missing data.
During the fine-tuning process, SMART uses prototype representations to capture the essential features of patient data, even when some information is missing. These prototypes act as anchors that help the model focus on the most relevant information for the task at hand.
Additionally, SMART employs adaptive attention mechanisms to dynamically adjust the importance of different patient features based on the available data. This allows the model to effectively utilize the information that is present in the EHR, while also accounting for the missing data.
By combining these techniques, SMART is able to make accurate predictions and handle missing data more effectively than traditional machine learning models. The researchers demonstrate the effectiveness of SMART on several healthcare prediction tasks, showing that it outperforms other state-of-the-art approaches.
Critical Analysis
The SMART model presents a promising approach to addressing the challenge of missing data in electronic health records (EHRs). The researchers have developed a robust pre-training strategy and innovative techniques, such as prototype representations and adaptive attention, to effectively leverage the available information in EHRs.
One potential limitation of the SMART model is that it may be sensitive to the distribution and patterns of missing data in the pre-training dataset. If the pre-training data has a significantly different missingness profile compared to the target task data, the model's performance may be affected. It would be valuable for the researchers to investigate the model's robustness to various missingness patterns and distributions.
Additionally, while the paper demonstrates the effectiveness of SMART on several healthcare prediction tasks, it would be interesting to see how the model performs on a more diverse set of tasks, including those that may require more complex reasoning or longitudinal patient data. Expanding the evaluation to a broader range of healthcare applications could further validate the model's capabilities and uncover any potential limitations.
Overall, the SMART model presents an innovative and promising approach to handling missing data in EHRs, with the potential to significantly improve healthcare prediction and decision-making. As the field of AI-powered healthcare continues to evolve, research like this will play a crucial role in unlocking the full potential of electronic health data.
Conclusion
The SMART model proposed in this paper offers a novel solution to the challenge of missing data in electronic health records (EHRs). By leveraging prototype representations and adaptive attention mechanisms, SMART is able to effectively utilize the available information in EHRs to make accurate predictions, even when some data is missing.
The researchers' approach of pre-training SMART on a large dataset and then fine-tuning it for specific healthcare tasks is a key strength of the model. This enables SMART to capture general patterns and representations that are broadly applicable, while also allowing for customization to the unique requirements of different prediction problems.
The critical analysis of the SMART model highlights the need to further investigate its robustness to various missingness patterns and its performance on a wider range of healthcare applications. Addressing these areas could help solidify SMART's position as a valuable tool for healthcare providers and researchers working to unlock the full potential of electronic health data.
Overall, the SMART model represents an important step forward in the field of AI-powered healthcare, demonstrating the potential of innovative techniques like prototype representations and adaptive attention to overcome the challenges posed by missing data in EHRs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SMART: Towards Pre-trained Missing-Aware Model for Patient Health Status Prediction
Zhihao Yu, Xu Chu, Yujie Jin, Yasha Wang, Junfeng Zhao
Electronic health record (EHR) data has emerged as a valuable resource for analyzing patient health status. However, the prevalence of missing data in EHR poses significant challenges to existing methods, leading to spurious correlations and suboptimal predictions. While various imputation techniques have been developed to address this issue, they often obsess unnecessary details and may introduce additional noise when making clinical predictions. To tackle this problem, we propose SMART, a Self-Supervised Missing-Aware RepresenTation Learning approach for patient health status prediction, which encodes missing information via elaborated attentions and learns to impute missing values through a novel self-supervised pre-training approach that reconstructs missing data representations in the latent space. By adopting missing-aware attentions and focusing on learning higher-order representations, SMART promotes better generalization and robustness to missing data. We validate the effectiveness of SMART through extensive experiments on six EHR tasks, demonstrating its superiority over state-of-the-art methods.
Read more5/16/2024
📊
0
PRISM: Leveraging Prototype Patient Representations with Feature-Missing-Aware Calibration for EHR Data Sparsity Mitigation
Yinghao Zhu, Zixiang Wang, Long He, Shiyun Xie, Xiaochen Zheng, Liantao Ma, Chengwei Pan
Electronic Health Records (EHRs) contain a wealth of patient data; however, the sparsity of EHRs data often presents significant challenges for predictive modeling. Conventional imputation methods inadequately distinguish between real and imputed data, leading to potential inaccuracies of patient representations. To address these issues, we introduce PRISM, a framework that indirectly imputes data by leveraging prototype representations of similar patients, thus ensuring compact representations that preserve patient information. PRISM also includes a feature confidence learner module, which evaluates the reliability of each feature considering missing statuses. Additionally, PRISM introduces a new patient similarity metric that accounts for feature confidence, avoiding overreliance on imprecise imputed values. Our extensive experiments on the MIMIC-III, MIMIC-IV, PhysioNet Challenge 2012, eICU datasets demonstrate PRISM's superior performance in predicting in-hospital mortality and 30-day readmission tasks, showcasing its effectiveness in handling EHR data sparsity. For the sake of reproducibility and further research, we have made the code publicly available at https://github.com/yhzhu99/PRISM.
Read more5/28/2024

0
MUSE-Net: Missingness-aware mUlti-branching Self-attention Encoder for Irregular Longitudinal Electronic Health Records
Zekai Wang, Tieming Liu, Bing Yao
The era of big data has made vast amounts of clinical data readily available, particularly in the form of electronic health records (EHRs), which provides unprecedented opportunities for developing data-driven diagnostic tools to enhance clinical decision making. However, the application of EHRs in data-driven modeling faces challenges such as irregularly spaced multi-variate time series, issues of incompleteness, and data imbalance. Realizing the full data potential of EHRs hinges on the development of advanced analytical models. In this paper, we propose a novel Missingness-aware mUlti-branching Self-attention Encoder (MUSE-Net) to cope with the challenges in modeling longitudinal EHRs for data-driven disease prediction. The MUSE-Net leverages a multi-task Gaussian process (MGP) with missing value masks for data imputation, a multi-branching architecture to address the data imbalance problem, and a time-aware self-attention encoder to account for the irregularly spaced time interval in longitudinal EHRs. We evaluate the proposed MUSE-Net using both synthetic and real-world datasets. Experimental results show that our MUSE-Net outperforms existing methods that are widely used to investigate longitudinal signals.
Read more7/2/2024
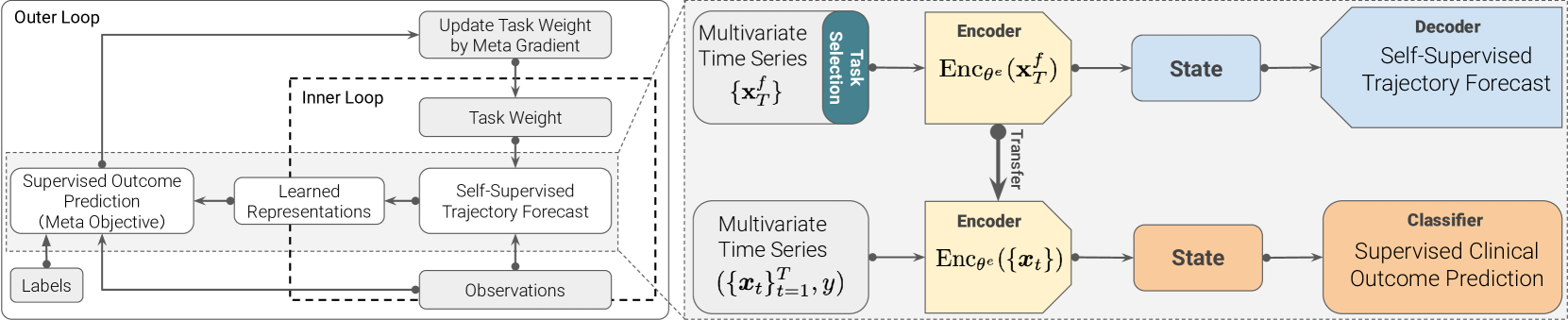
0
Learning to Select the Best Forecasting Tasks for Clinical Outcome Prediction
Yuan Xue, Nan Du, Anne Mottram, Martin Seneviratne, Andrew M. Dai
We propose to meta-learn an a self-supervised patient trajectory forecast learning rule by meta-training on a meta-objective that directly optimizes the utility of the patient representation over the subsequent clinical outcome prediction. This meta-objective directly targets the usefulness of a representation generated from unlabeled clinical measurement forecast for later supervised tasks. The meta-learned can then be directly used in target risk prediction, and the limited available samples can be used for further fine-tuning the model performance. The effectiveness of our approach is tested on a real open source patient EHR dataset MIMIC-III. We are able to demonstrate that our attention-based patient state representation approach can achieve much better performance for predicting target risk with low resources comparing with both direct supervised learning and pretraining with all-observation trajectory forecast.
Read more7/30/2024