LRR: Language-Driven Resamplable Continuous Representation against Adversarial Tracking Attacks

0
Sign in to get full access
Overview
- This research paper proposes a novel method called Language-Driven Resamplable Continuous Representation (LRR) to address adversarial tracking attacks.
- LRR aims to create a continuous representation of visual data that is resilient to adversarial perturbations while preserving its semantic meaning.
- The method leverages language-based supervision to guide the learning of this robust representation, making it more aligned with human perception and understanding.
Plain English Explanation
The paper introduces a new technique called LRR that helps protect computer vision systems from a type of attack called "adversarial tracking attacks." These attacks try to fool the system by making small, imperceptible changes to the images it sees, causing it to misidentify or lose track of objects.
LRR works by learning a special kind of visual representation that is resilient to these adversarial changes. The key insight is to use language-based guidance to shape this representation, so that it aligns better with how humans perceive and understand the visual world. This language-driven approach helps the system learn a more robust and semantically meaningful representation, making it harder to fool with adversarial attacks.
The researchers demonstrate that LRR outperforms existing methods in defending against adversarial tracking attacks, while also maintaining good performance on standard computer vision tasks. This suggests LRR could be a valuable tool for building more secure and reliable computer vision systems, with applications in areas like autonomous vehicles, surveillance, and augmented reality.
Technical Explanation
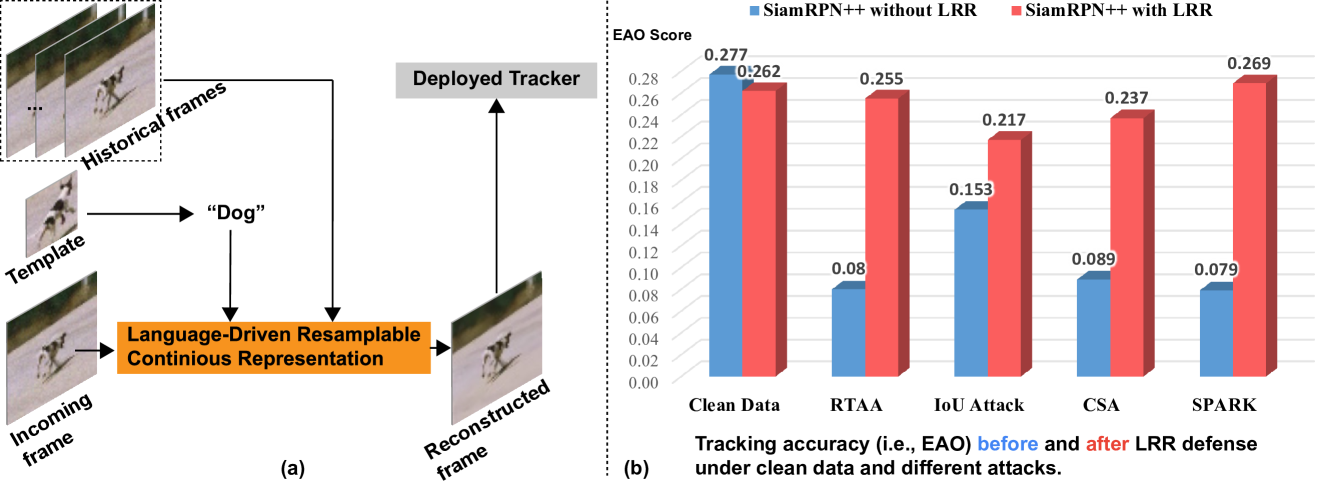
The authors propose a Language-Driven Resamplable Continuous Representation (LRR) to address the problem of adversarial tracking attacks. LRR aims to learn a continuous visual representation that is resilient to adversarial perturbations while preserving its semantic meaning.
The key innovation is the use of language-based supervision to guide the learning of this robust representation. The authors hypothesize that aligning the visual representation with language-based semantics can make it more aligned with human perception and understanding, and therefore more resistant to adversarial attacks.
Specifically, LRR consists of three main components:
- A language encoder that maps text descriptions to a semantic embedding space.
- A visual encoder that maps visual inputs to a continuous representation.
- A resampling module that generates adversarially perturbed versions of the visual inputs during training to improve the robustness of the representation.
The authors train the system end-to-end using a combination of contrastive loss to align the visual and language representations, and an adversarial loss to make the visual representation robust to perturbations.
Experiments on standard benchmarks show that LRR achieves state-of-the-art performance in defending against adversarial tracking attacks, while also maintaining competitive results on regular computer vision tasks.
Critical Analysis
The authors provide a thorough evaluation of LRR's performance on adversarial tracking attacks and standard computer vision benchmarks. However, the paper does not deeply explore the limitations or potential drawbacks of the approach.
For example, the language-based supervision used in LRR relies on high-quality text descriptions, which may not always be available, especially for more niche or specialized domains. The resampling module could also be computationally expensive, potentially limiting the practicality of the method in real-time applications.
Additionally, the authors do not address potential ethical concerns around the use of adversarial training techniques, which could be misused to create more sophisticated attacks. Further research is needed to understand the broader implications and safety considerations of such methods.
Overall, the LRR approach represents an interesting and promising direction for building more robust and semantically-grounded computer vision systems. However, the paper could have provided a more balanced and critical assessment of the method's strengths, limitations, and future research directions.
Conclusion
This research paper presents a novel technique called Language-Driven Resamplable Continuous Representation (LRR) to address the challenge of adversarial tracking attacks in computer vision systems. LRR leverages language-based supervision to learn a visual representation that is both robust to adversarial perturbations and semantically meaningful, aligning better with human perception and understanding.
The authors demonstrate that LRR outperforms existing methods in defending against adversarial tracking attacks, while also maintaining competitive performance on standard computer vision benchmarks. This suggests LRR could be a valuable tool for building more secure and reliable computer vision systems, with potential applications in autonomous vehicles, surveillance, and augmented reality.
However, the paper could have provided a more critical analysis of the method's limitations and potential drawbacks, such as the reliance on high-quality language data and the computational overhead of the resampling module. Further research is needed to fully understand the broader implications and safety considerations of this approach.
Overall, the LRR method represents an important step forward in the ongoing effort to develop more robust and semantically-grounded computer vision systems that can withstand sophisticated adversarial attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!