Learning Two-factor Representation for Magnetic Resonance Image Super-resolution

0

Sign in to get full access
Overview
- MR image super-resolution is the task of enhancing the resolution of low-quality magnetic resonance (MR) images.
- This paper proposes a novel two-factor representation approach to tackle this challenge.
- The key ideas are a coordinate-based encoding and a task-specific feature fusion module.
Plain English Explanation
Magnetic resonance (MR) imaging is a powerful medical technology that allows doctors to see detailed images of the inside of the body. However, sometimes the images produced can be low in quality, with blurry or pixelated details. This paper introduces a new approach to enhance the resolution of these low-quality MR images, making them clearer and more useful for medical diagnosis and treatment.
The core of the approach is a "two-factor representation" that combines two key components:
- Coordinate-based encoding: The method encodes the spatial coordinates of the image pixels in a way that helps the model understand the overall structure and layout of the image.
- Task-specific feature fusion: The model then fuses this spatial information with other image features in a way that is tailored to the specific task of super-resolution, helping it generate sharper, higher-quality images.
By using this two-factor representation, the model is able to better understand the context and structure of the original low-quality MR image, and then generate a high-quality enhanced version that is more useful for medical applications. The paper demonstrates that this approach outperforms other state-of-the-art methods for MR image super-resolution.
Technical Explanation
The paper proposes a novel two-factor representation learning approach for magnetic resonance (MR) image super-resolution. The key elements of the method are:
-
Coordinate-based Encoding: The model encodes the spatial coordinates of the input MR image in a way that captures the overall structure and layout of the image. This is done using a multilayer perceptron (MLP) that maps the 2D coordinates to a higher-dimensional feature representation.
-
Task-specific Feature Fusion: The encoded spatial features are then fused with other image features using a task-specific feature fusion module. This module learns to combine the coordinate-based and content-based features in an optimal way for the super-resolution task, helping the model generate sharper, higher-quality output images.
The authors evaluate their approach on several MR image super-resolution benchmarks and show that it outperforms other state-of-the-art methods in terms of both quantitative metrics and visual quality. The experiments demonstrate the effectiveness of the two-factor representation in capturing the necessary information for high-quality MR image super-resolution.
Critical Analysis
The paper presents a well-designed and effective approach for MR image super-resolution. The key strengths are the novel two-factor representation and the task-specific feature fusion module, which allow the model to better leverage the spatial structure and content of the input images.
However, the paper does not discuss some potential limitations or areas for future work. For example, the approach may be computationally intensive due to the MLP-based coordinate encoding and the feature fusion module. Additionally, the paper only evaluates the method on standard MR image datasets, and it would be interesting to see how it performs on more challenging or diverse MR imaging scenarios.
Further research could also explore ways to make the two-factor representation more efficient or generalizable, or to integrate it with other super-resolution techniques to achieve even better results. Exploring these directions could lead to further advancements in this important area of medical imaging.
Conclusion
This paper presents a novel two-factor representation approach for magnetic resonance (MR) image super-resolution. The key ideas are a coordinate-based encoding to capture the spatial structure of the input image, and a task-specific feature fusion module to optimally combine this spatial information with content-based features.
The authors demonstrate the effectiveness of this two-factor representation through extensive experiments, showing that it outperforms other state-of-the-art methods for MR image super-resolution. This work represents an important step forward in enhancing the quality and utility of MR imaging for medical applications.
While the paper does not discuss certain limitations or future research directions, the core ideas introduced here have the potential to inspire further advancements in this critical field of medical imaging technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Two-factor Representation for Magnetic Resonance Image Super-resolution
Weifeng Wei, Heng Chen, Pengxiang Su
Magnetic Resonance Imaging (MRI) requires a trade-off between resolution, signal-to-noise ratio, and scan time, making high-resolution (HR) acquisition challenging. Therefore, super-resolution for MR image is a feasible solution. However, most existing methods face challenges in accurately learning a continuous volumetric representation from low-resolution image or require HR image for supervision. To solve these challenges, we propose a novel method for MR image super-resolution based on two-factor representation. Specifically, we factorize intensity signals into a linear combination of learnable basis and coefficient factors, enabling efficient continuous volumetric representation from low-resolution MR image. Besides, we introduce a coordinate-based encoding to capture structural relationships between sparse voxels, facilitating smooth completion in unobserved regions. Experiments on BraTS 2019 and MSSEG 2016 datasets demonstrate that our method achieves state-of-the-art performance, providing superior visual fidelity and robustness, particularly in large up-sampling scale MR image super-resolution.
Read more9/17/2024

0
Inter-slice Super-resolution of Magnetic Resonance Images by Pre-training and Self-supervised Fine-tuning
Xin Wang, Zhiyun Song, Yitao Zhu, Sheng Wang, Lichi Zhang, Dinggang Shen, Qian Wang
In clinical practice, 2D magnetic resonance (MR) sequences are widely adopted. While individual 2D slices can be stacked to form a 3D volume, the relatively large slice spacing can pose challenges for both image visualization and subsequent analysis tasks, which often require isotropic voxel spacing. To reduce slice spacing, deep-learning-based super-resolution techniques are widely investigated. However, most current solutions require a substantial number of paired high-resolution and low-resolution images for supervised training, which are typically unavailable in real-world scenarios. In this work, we propose a self-supervised super-resolution framework for inter-slice super-resolution of MR images. Our framework is first featured by pre-training on video dataset, as temporal correlation of videos is found beneficial for modeling the spatial relation among MR slices. Then, we use public high-quality MR dataset to fine-tune our pre-trained model, for enhancing awareness of our model to medical data. Finally, given a target dataset at hand, we utilize self-supervised fine-tuning to further ensure our model works well with user-specific super-resolution tasks. The proposed method demonstrates superior performance compared to other self-supervised methods and also holds the potential to benefit various downstream applications.
Read more6/11/2024

0
Hyperspectral and multispectral image fusion with arbitrary resolution through self-supervised representations
Ting Wang, Zipei Yan, Jizhou Li, Xile Zhao, Chao Wang, Michael Ng
The fusion of a low-resolution hyperspectral image (LR-HSI) with a high-resolution multispectral image (HR-MSI) has emerged as an effective technique for achieving HSI super-resolution (SR). Previous studies have mainly concentrated on estimating the posterior distribution of the latent high-resolution hyperspectral image (HR-HSI), leveraging an appropriate image prior and likelihood computed from the discrepancy between the latent HSI and observed images. Low rankness stands out for preserving latent HSI characteristics through matrix factorization among the various priors. However, this method only enhances resolution within the dimensions of the two modalities. To overcome this limitation, we propose a novel continuous low-rank factorization (CLoRF) by integrating two neural representations into the matrix factorization, capturing spatial and spectral information, respectively. This approach enables us to harness both the low rankness from the matrix factorization and the continuity from neural representation in a self-supervised manner. Theoretically, we prove the low-rank property and Lipschitz continuity in the proposed continuous low-rank factorization. Experimentally, our method significantly surpasses existing techniques and achieves user-desired resolutions without the need for neural network retraining.
Read more5/29/2024
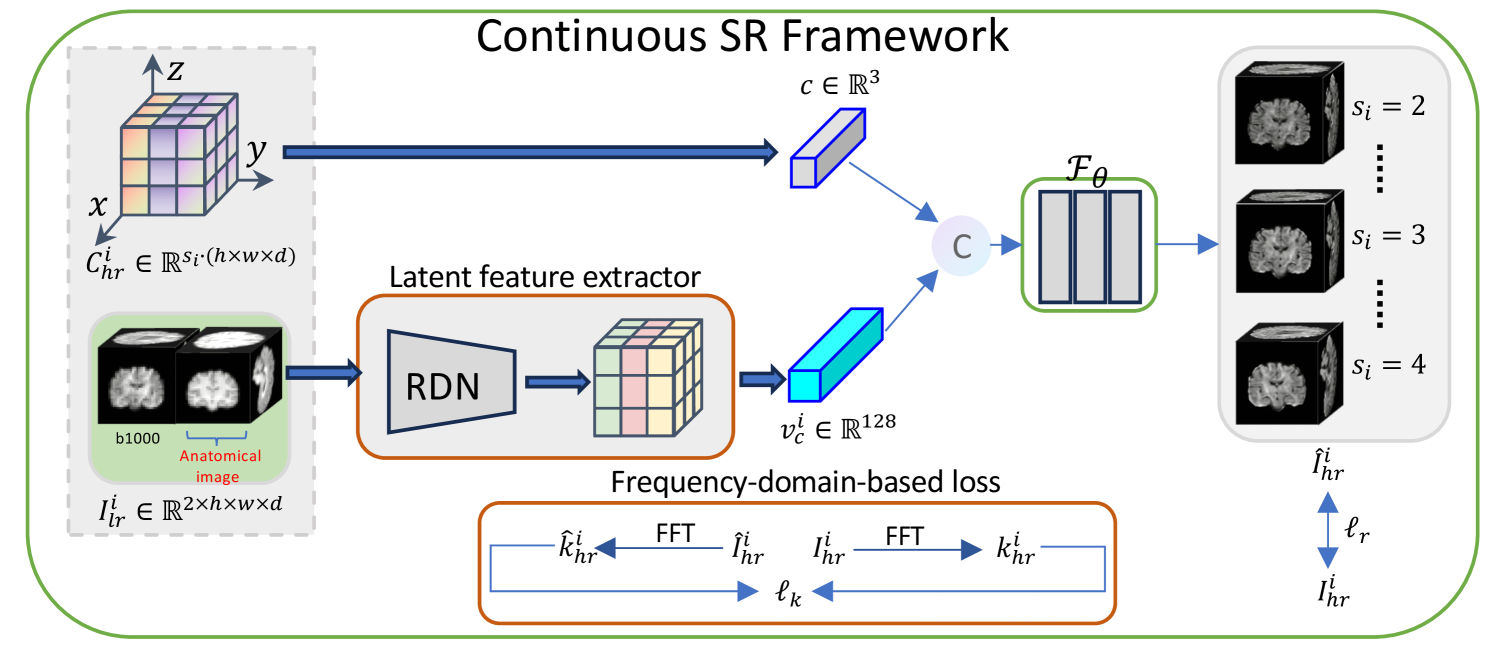
0
CSR-dMRI: Continuous Super-Resolution of Diffusion MRI with Anatomical Structure-assisted Implicit Neural Representation Learning
Ruoyou Wu, Jian Cheng, Cheng Li, Juan Zou, Jing Yang, Wenxin Fan, Yong Liang, Shanshan Wang
Deep learning-based dMRI super-resolution methods can effectively enhance image resolution by leveraging the learning capabilities of neural networks on large datasets. However, these methods tend to learn a fixed scale mapping between low-resolution (LR) and high-resolution (HR) images, overlooking the need for radiologists to scale the images at arbitrary resolutions. Moreover, the pixel-wise loss in the image domain tends to generate over-smoothed results, losing fine textures and edge information. To address these issues, we propose a novel continuous super-resolution method for dMRI, called CSR-dMRI, which utilizes an anatomical structure-assisted implicit neural representation learning approach. Specifically, the CSR-dMRI model consists of two components. The first is the latent feature extractor, which primarily extracts latent space feature maps from LR dMRI and anatomical images while learning structural prior information from the anatomical images. The second is the implicit function network, which utilizes voxel coordinates and latent feature vectors to generate voxel intensities at corresponding positions. Additionally, a frequency-domain-based loss is introduced to preserve the structural and texture information, further enhancing the image quality. Extensive experiments on the publicly available HCP dataset validate the effectiveness of our approach. Furthermore, our method demonstrates superior generalization capability and can be applied to arbitrary-scale super-resolution, including non-integer scale factors, expanding its applicability beyond conventional approaches.
Read more8/15/2024