Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection

0

Sign in to get full access
Overview
- The paper presents a novel unsupervised multi-class anomaly detection method that learns a unified reference representation.
- It addresses the challenge of detecting multiple types of anomalies in complex, high-dimensional datasets without relying on labeled data.
- The proposed approach, called Learning Unified Reference Representation (LURR), leverages self-supervised feature reconstruction to capture the underlying data distribution and identify anomalies.
Plain English Explanation
In many real-world applications, such as industrial anomaly detection or time series analysis, it's important to be able to identify unusual or abnormal patterns in data. This is known as anomaly detection. However, this can be challenging when there are multiple types of anomalies, and the dataset is complex and high-dimensional, like images or sensor readings.
The researchers in this paper developed a new method called LURR that can detect different kinds of anomalies without needing labeled data. The key idea is to train an artificial intelligence system to learn a "reference representation" of the normal data patterns. Then, it can identify anomalies as data points that don't fit well with this learned representation.
This is done through a process called self-supervised feature reconstruction. The AI system tries to reconstruct the original data from a distorted or "masked" version of it. By learning to do this reconstruction well for normal data, the system builds an internal understanding of the dataset's structure. Anomalies are then detected as data points that are hard to reconstruct accurately.
This approach is more flexible than methods that rely on labeled anomaly examples, and it can handle complex, high-dimensional data like industrial sensor data or time series. The researchers show that their LURR method outperforms other state-of-the-art anomaly detection techniques on a variety of benchmark datasets.
Technical Explanation
The core idea behind LURR is to learn a unified reference representation that captures the underlying data distribution, which can then be used to identify anomalies in an unsupervised manner. This is achieved through a self-supervised feature reconstruction task, where the model tries to reconstruct the original data from a distorted or "masked" version of it.
The LURR architecture consists of an encoder-decoder network, where the encoder maps the input data to a latent representation, and the decoder reconstructs the original data from this latent representation. The key innovation is that the latent representation is shared across all classes, rather than learning separate representations for each class, as is common in clustering-based anomaly detection approaches.
During training, the model is optimized to minimize the reconstruction error for normal data samples. Anomalies are then identified as data points that have high reconstruction errors, indicating that they do not fit well with the learned reference representation.
The authors conduct extensive experiments on several benchmark datasets, including industrial sensor data, network traffic logs, and time series data. They show that LURR outperforms other state-of-the-art unsupervised anomaly detection methods, demonstrating its effectiveness in identifying diverse types of anomalies in complex, high-dimensional datasets.
Critical Analysis
The LURR approach presented in this paper addresses an important problem in the field of anomaly detection and has several notable strengths. By learning a unified reference representation, it can effectively handle multi-class anomaly detection without requiring labeled data, which is a significant advantage over many supervised methods.
However, the paper also acknowledges some limitations and potential areas for further research. For example, the authors note that LURR may struggle with rare anomalies that are very different from the normal data distribution, as the reconstruction-based approach may not be able to detect them accurately.
Additionally, the paper does not provide a thorough analysis of the computational complexity or training time of the LURR method, which could be an important consideration for real-world applications with large-scale or time-sensitive data.
Researchers interested in this work may also want to explore ways to further improve the interpretability of the learned reference representation, as well as investigate potential extensions to handle dynamic or evolving data distributions.
Conclusion
The LURR method presented in this paper is a promising approach for unsupervised multi-class anomaly detection in complex, high-dimensional datasets. By learning a unified reference representation through self-supervised feature reconstruction, it can effectively identify diverse types of anomalies without relying on labeled data.
The strong empirical results on various benchmark datasets demonstrate the potential of this technique to be applied in real-world scenarios, such as industrial monitoring, network security, and time series analysis. As the field of anomaly detection continues to evolve, the insights and innovations from this work may inspire further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection
Liren He, Zhengkai Jiang, Jinlong Peng, Liang Liu, Qiangang Du, Xiaobin Hu, Wenbing Zhu, Mingmin Chi, Yabiao Wang, Chengjie Wang
In the field of multi-class anomaly detection, reconstruction-based methods derived from single-class anomaly detection face the well-known challenge of learning shortcuts, wherein the model fails to learn the patterns of normal samples as it should, opting instead for shortcuts such as identity mapping or artificial noise elimination. Consequently, the model becomes unable to reconstruct genuine anomalies as normal instances, resulting in a failure of anomaly detection. To counter this issue, we present a novel unified feature reconstruction-based anomaly detection framework termed RLR (Reconstruct features from a Learnable Reference representation). Unlike previous methods, RLR utilizes learnable reference representations to compel the model to learn normal feature patterns explicitly, thereby prevents the model from succumbing to the learning shortcuts issue. Additionally, RLR incorporates locality constraints into the learnable reference to facilitate more effective normal pattern capture and utilizes a masked learnable key attention mechanism to enhance robustness. Evaluation of RLR on the 15-category MVTec-AD dataset and the 12-category VisA dataset shows superior performance compared to state-of-the-art methods under the unified setting. The code of RLR will be publicly available.
Read more7/17/2024
0
Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Zhijin Dong, Hongzhi Liu, Boyuan Ren, Weimin Xiong, Zhonghai Wu
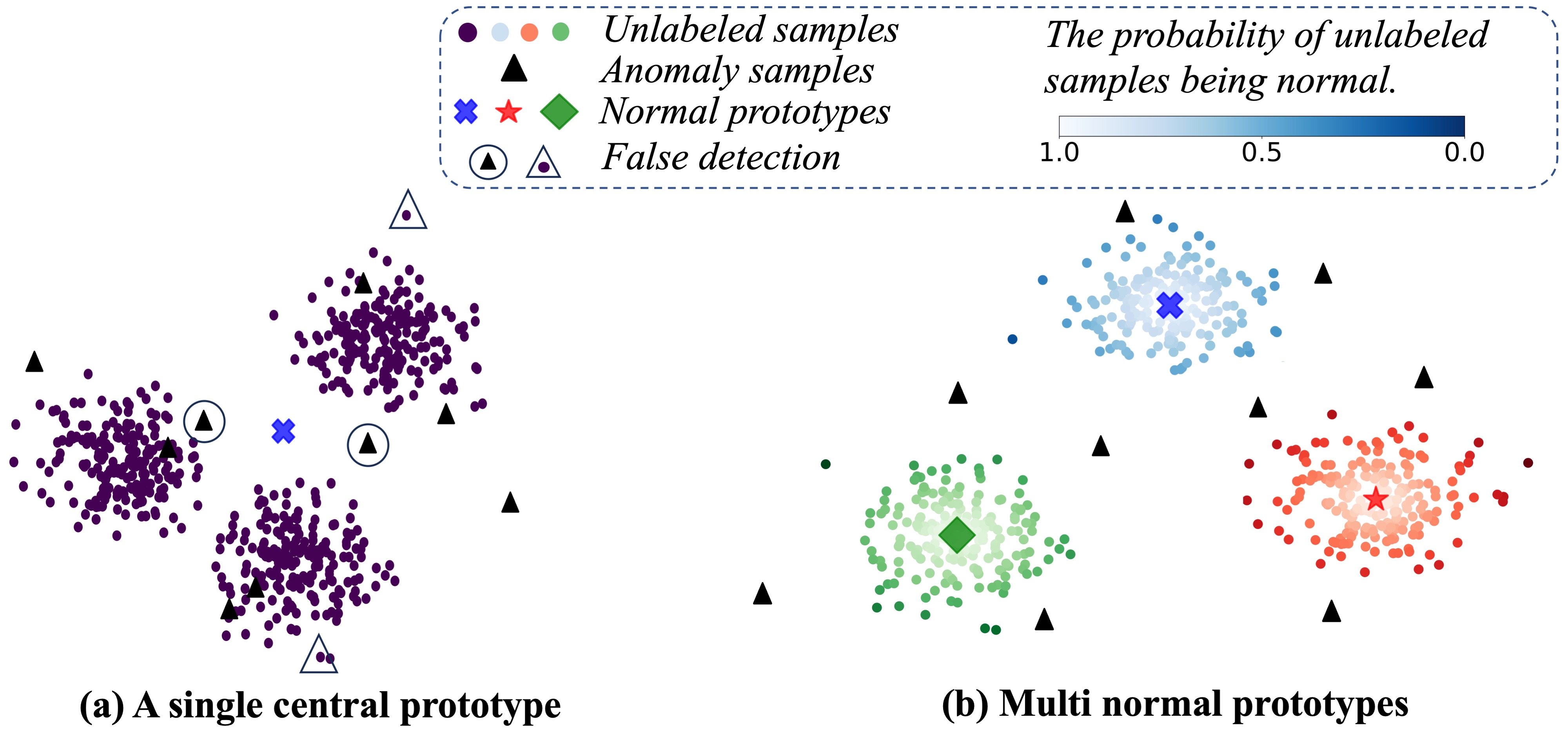
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
Read more8/28/2024
❗
0
REB: Reducing Biases in Representation for Industrial Anomaly Detection
Shuai Lyu, Dongmei Mo, Waikeung Wong
Existing representation-based methods usually conduct industrial anomaly detection in two stages: obtain feature representations with a pre-trained model and perform distance measures for anomaly detection. Among them, K-nearest neighbor (KNN) retrieval-based anomaly detection methods show promising results. However, the features are not fully exploited as these methods ignore domain bias of pre-trained models and the difference of local density in feature space, which limits the detection performance. In this paper, we propose Reducing Biases (REB) in representation by considering the domain bias and building a self-supervised learning task for better domain adaption with a defect generation strategy (DefectMaker) that ensures a strong diversity in the synthetic defects. Additionally, we propose a local-density KNN (LDKNN) to reduce the local density bias in the feature space and obtain effective anomaly detection. The proposed REB method achieves a promising result of 99.5% Im.AUROC on the widely used MVTec AD, with smaller backbone networks such as Vgg11 and Resnet18. The method also achieves an impressive 88.8% Im.AUROC on the MVTec LOCO AD dataset and a remarkable 96.0% on the BTAD dataset, outperforming other representation-based approaches. These results indicate the effectiveness and efficiency of REB for practical industrial applications. Code:https://github.com/ShuaiLYU/REB.
Read more5/20/2024
0
Multi-feature Reconstruction Network using Crossed-mask Restoration for Unsupervised Anomaly Detection
Junpu Wang, Guili Xu, Chunlei Li, Guangshuai Gao, Yuehua Cheng
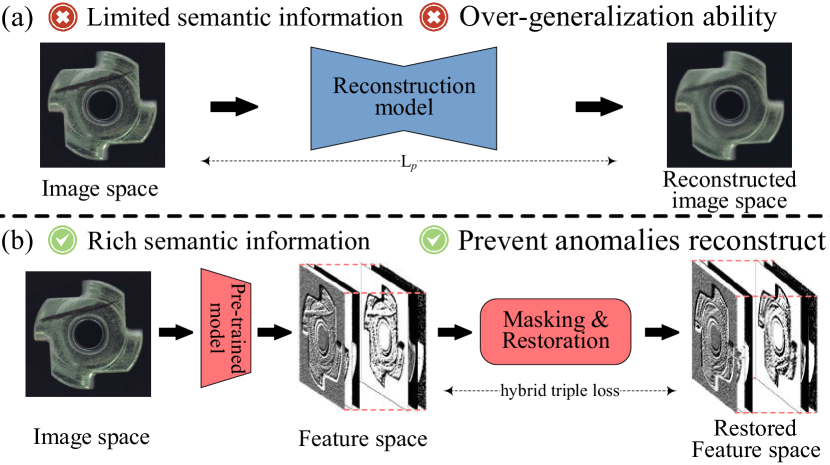
Unsupervised anomaly detection using only normal samples is of great significance for quality inspection in industrial manufacturing. Although existing reconstruction-based methods have achieved promising results, they still face two problems: poor distinguishable information in image reconstruction and well abnormal regeneration caused by model over-generalization ability. To overcome the above issues, we convert the image reconstruction into a combination of parallel feature restorations and propose a multi-feature reconstruction network, MFRNet, using crossed-mask restoration in this paper. Specifically, a multi-scale feature aggregator is first developed to generate more discriminative hierarchical representations of the input images from a pre-trained model. Subsequently, a crossed-mask generator is adopted to randomly cover the extracted feature map, followed by a restoration network based on the transformer structure for high-quality repair of the missing regions. Finally, a hybrid loss is equipped to guide model training and anomaly estimation, which gives consideration to both the pixel and structural similarity. Extensive experiments show that our method is highly competitive with or significantly outperforms other state-of-the-arts on four public available datasets and one self-made dataset.
Read more4/23/2024