Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection

0
Sign in to get full access
Overview
- This paper presents a novel method for weakly supervised anomaly detection using reconstruction-based multi-normal prototypes learning.
- The key idea is to learn a set of representative "normal" prototypes that can accurately reconstruct normal data samples, while anomalies cannot be well reconstructed.
- The model is trained in a weakly supervised manner, only requiring classification labels (normal/anomaly) for a subset of the training data.
Plain English Explanation
The paper introduces a new technique for detecting anomalies or unusual data points, even when only a small portion of the training data has been labeled as normal or anomalous. The core idea is to learn a set of "prototypes" that represent typical or normal data patterns.
These prototypes are trained to be able to accurately reconstruct normal data samples when used as a reference. However, anomalous data points that don't fit the normal patterns won't be well reconstructed by the prototypes. By measuring how well a data sample can be reconstructed using the learned prototypes, the model can identify anomalies without needing a lot of labeled training data.
This is an important advance because in many real-world scenarios, it's difficult or expensive to obtain detailed labels for all the data. The proposed approach can work effectively with just a few labeled examples, making it more practical for many applications.
Technical Explanation
The paper proposes a reconstruction-based multi-normal prototypes learning (RMNP) framework for weakly supervised anomaly detection. The key components include:
-
Prototype Learning: The model learns a set of "normal" prototypes that can effectively reconstruct normal data samples. These prototypes capture the common patterns in the normal data.
-
Reconstruction-based Anomaly Score: The ability of a data sample to be reconstructed using the learned prototypes is used as the anomaly score. Samples that cannot be well reconstructed by the prototypes are considered anomalies.
-
Weakly Supervised Training: The model is trained in a weakly supervised manner, only requiring classification labels (normal/anomaly) for a subset of the training data. This makes the approach more practical than fully supervised methods that need detailed labels for all samples.
The technical details involve optimizing a reconstruction-based objective function to learn the prototypes, while also ensuring they can distinguish normal from anomalous data. Experiments on benchmark datasets demonstrate the advantages of the RMNP approach compared to other weakly supervised and unsupervised anomaly detection methods.
Critical Analysis
The paper presents a well-designed and empirically validated anomaly detection framework that addresses the common challenge of limited labeled training data. However, a few potential limitations or areas for further research are:
-
Sensitivity to Prototype Number: The performance of the RMNP model seems to depend on the number of prototypes learned. Determining the optimal number of prototypes may require additional tuning or heuristics.
-
Interpretability of Prototypes: While the prototypes are used as a basis for anomaly detection, the paper does not explore how interpretable or meaningful these prototypes are. Providing more insight into the learned prototypes could improve the model's explainability.
-
Real-world Deployment Challenges: The paper evaluated the approach on benchmark datasets, but deploying such a system in a real-world setting may introduce additional challenges, such as handling concept drift or incorporating domain-specific knowledge.
Overall, the RMNP framework is a promising contribution to the field of weakly supervised anomaly detection, but further research could explore ways to address these potential limitations and make the approach more robust and practical for real-world applications.
Conclusion
This paper introduces a novel reconstruction-based multi-normal prototypes learning (RMNP) framework for weakly supervised anomaly detection. By learning a set of representative "normal" prototypes that can accurately reconstruct typical data samples, the model can effectively identify anomalies without requiring detailed labels for the entire training dataset.
The key innovation of the RMNP approach is its ability to work with limited labeled data, making it more practical for many real-world applications where obtaining comprehensive labels is challenging. The empirical results demonstrate the advantages of this method over other weakly supervised and unsupervised anomaly detection techniques.
While the paper highlights some potential areas for further improvement, the RMNP framework represents an important step forward in developing effective anomaly detection solutions that can be deployed in settings with scarce labeled data. This work could inspire future research to enhance the interpretability, robustness, and practical applicability of such weakly supervised anomaly detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Zhijin Dong, Hongzhi Liu, Boyuan Ren, Weimin Xiong, Zhonghai Wu
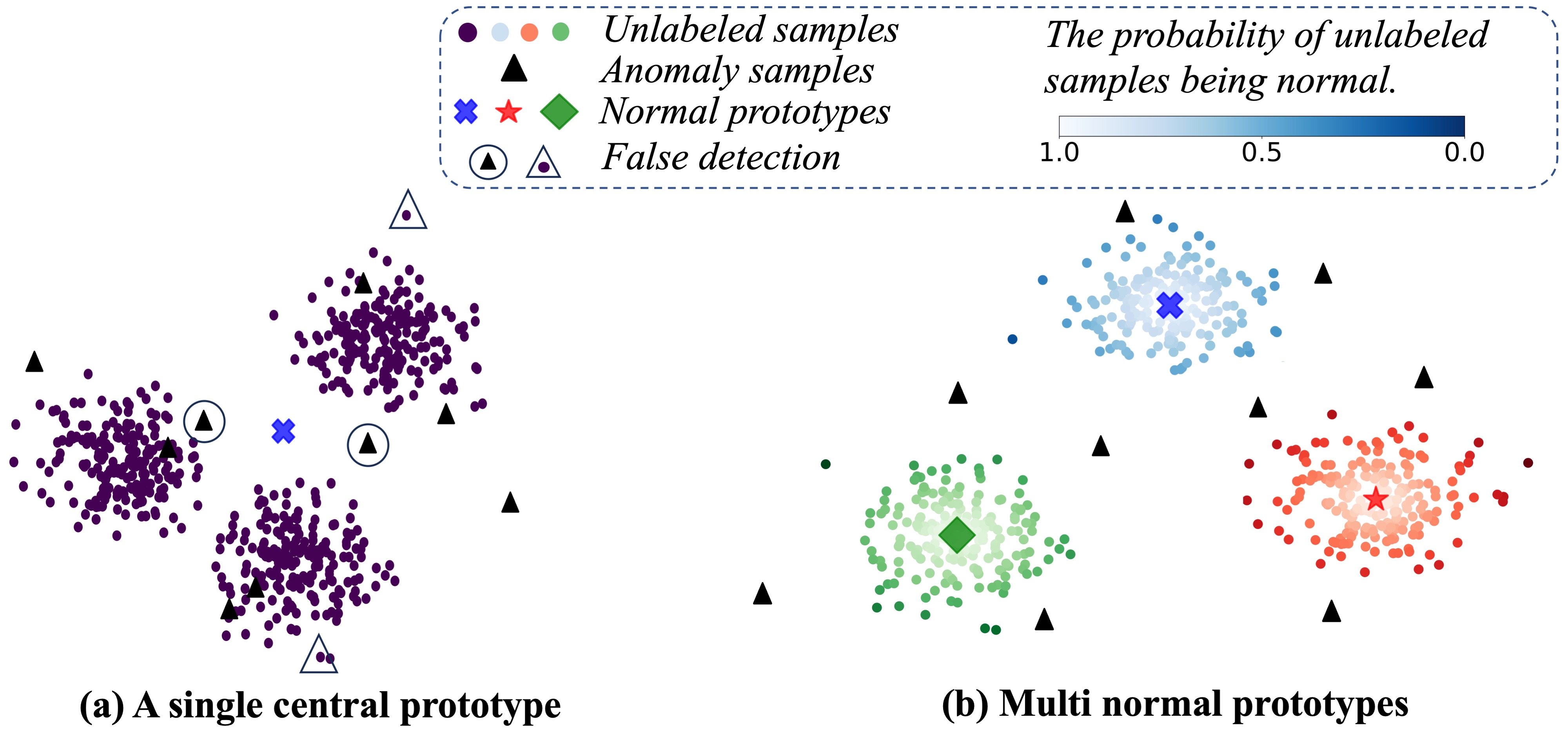
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
Read more8/28/2024

0
Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection
Liren He, Zhengkai Jiang, Jinlong Peng, Liang Liu, Qiangang Du, Xiaobin Hu, Wenbing Zhu, Mingmin Chi, Yabiao Wang, Chengjie Wang
In the field of multi-class anomaly detection, reconstruction-based methods derived from single-class anomaly detection face the well-known challenge of learning shortcuts, wherein the model fails to learn the patterns of normal samples as it should, opting instead for shortcuts such as identity mapping or artificial noise elimination. Consequently, the model becomes unable to reconstruct genuine anomalies as normal instances, resulting in a failure of anomaly detection. To counter this issue, we present a novel unified feature reconstruction-based anomaly detection framework termed RLR (Reconstruct features from a Learnable Reference representation). Unlike previous methods, RLR utilizes learnable reference representations to compel the model to learn normal feature patterns explicitly, thereby prevents the model from succumbing to the learning shortcuts issue. Additionally, RLR incorporates locality constraints into the learnable reference to facilitate more effective normal pattern capture and utilizes a masked learnable key attention mechanism to enhance robustness. Evaluation of RLR on the 15-category MVTec-AD dataset and the 12-category VisA dataset shows superior performance compared to state-of-the-art methods under the unified setting. The code of RLR will be publicly available.
Read more7/17/2024
0
Weakly-supervised anomaly detection for multimodal data distributions
Xu Tan, Junqi Chen, Sylwan Rahardja, Jiawei Yang, Susanto Rahardja
Weakly-supervised anomaly detection can outperform existing unsupervised methods with the assistance of a very small number of labeled anomalies, which attracts increasing attention from researchers. However, existing weakly-supervised anomaly detection methods are limited as these methods do not factor in the multimodel nature of the real-world data distribution. To mitigate this, we propose the Weakly-supervised Variational-mixture-model-based Anomaly Detector (WVAD). WVAD excels in multimodal datasets. It consists of two components: a deep variational mixture model, and an anomaly score estimator. The deep variational mixture model captures various features of the data from different clusters, then these features are delivered to the anomaly score estimator to assess the anomaly levels. Experimental results on three real-world datasets demonstrate WVAD's superiority.
Read more6/14/2024

0
Deep Positive-Unlabeled Anomaly Detection for Contaminated Unlabeled Data
Hiroshi Takahashi, Tomoharu Iwata, Atsutoshi Kumagai, Yuuki Yamanaka
Semi-supervised anomaly detection, which aims to improve the performance of the anomaly detector by using a small amount of anomaly data in addition to unlabeled data, has attracted attention. Existing semi-supervised approaches assume that unlabeled data are mostly normal. They train the anomaly detector to minimize the anomaly scores for the unlabeled data, and to maximize those for the anomaly data. However, in practice, the unlabeled data are often contaminated with anomalies. This weakens the effect of maximizing the anomaly scores for anomalies, and prevents us from improving the detection performance. To solve this problem, we propose the positive-unlabeled autoencoder, which is based on positive-unlabeled learning and the anomaly detector such as the autoencoder. With our approach, we can approximate the anomaly scores for normal data using the unlabeled and anomaly data. Therefore, without the labeled normal data, we can train the anomaly detector to minimize the anomaly scores for normal data, and to maximize those for the anomaly data. In addition, our approach is applicable to various anomaly detectors such as the DeepSVDD. Experiments on various datasets show that our approach achieves better detection performance than existing approaches.
Read more5/30/2024