Learning Velocity-based Humanoid Locomotion: Massively Parallel Learning with Brax and MJX

0

Sign in to get full access
Overview
- This paper presents a novel approach to learning velocity-based humanoid locomotion using massively parallel learning with Brax and MJX.
- The researchers developed a system that can learn complex locomotion behaviors for humanoid robots through a highly scalable and efficient training process.
- The work has been accepted for presentation at the CLAWAR 2024 conference in Kaiserslautern, Germany.
Plain English Explanation
The paper describes a new method for teaching humanoid robots how to walk and move around effectively. Traditionally, programming robots to perform complex movements like walking has been a challenging task. The researchers in this study found a way to make the training process much faster and more efficient.
They used a simulation environment called Brax to create virtual humanoid robots, and then trained these robots to learn different locomotion behaviors through a technique called "massively parallel learning." This means they trained many robot simulations at the same time, rather than just one at a time. This allowed them to explore a wide range of possible walking and movement strategies very quickly.
The researchers also incorporated a machine learning system called MJX, which helped the robots learn optimal movement patterns even more effectively. By combining Brax and MJX, the team was able to develop a highly scalable and efficient training process for teaching humanoid robots how to move around in a natural and effective way.
The paper's findings have been accepted for presentation at a major robotics conference, indicating that the research represents an important advance in the field of humanoid locomotion.
Technical Explanation
The paper presents a novel approach to learning velocity-based humanoid locomotion using massively parallel learning with Brax and MJX. Brax is a simulation environment for training virtual humanoid robots, and MJX is a machine learning system that helps the robots learn optimal movement patterns.
The researchers developed a training process that allows them to explore a wide range of possible locomotion behaviors for humanoid robots very quickly. They did this by training many robot simulations in parallel, rather than just one at a time. This "massively parallel learning" approach is highly scalable and efficient, as it allows the researchers to test many different walking and movement strategies simultaneously.
The incorporation of MJX into the training process further enhances the robots' ability to learn effective locomotion behaviors. MJX helps the robots identify the optimal movement patterns for different tasks and environments, leading to more natural and efficient locomotion.
The paper's findings have been accepted for presentation at the CLAWAR 2024 conference in Kaiserslautern, Germany, indicating that the research represents an important advancement in the field of humanoid robotics and locomotion. The techniques developed in this study could have significant implications for the development of more agile and capable humanoid robots that can navigate and interact with the world in a more natural and effective way.
Critical Analysis
The paper presents a compelling approach to learning velocity-based humanoid locomotion, but it is important to consider some potential limitations and areas for further research.
One potential concern is the reliance on simulation environments, such as Brax, to train the robot models. While simulation can be a powerful tool for rapid exploration and testing, there may be some discrepancies between the simulated environments and the real-world conditions that the robots would encounter. Further research may be needed to bridge the gap between simulation and real-world performance.
Additionally, the paper does not provide a detailed analysis of the computational resources required for the massively parallel learning approach. Scaling this technique to larger and more complex robot models may require significant computational power, which could limit its practical application in some scenarios.
Another area for further investigation is the integration of the MJX machine learning system with the Brax simulation environment. While the paper suggests that MJX enhances the robots' ability to learn effective locomotion behaviors, more detailed analysis of the specific algorithms and training processes used could provide valuable insights for researchers working on similar problems.
Despite these potential limitations, the paper represents an important advancement in the field of humanoid robotics and locomotion. The techniques developed in this study could pave the way for the creation of more agile and capable humanoid robots that can navigate and interact with the world in more natural and effective ways, with potential applications in areas such as assistive robotics and humanoid interaction.
Conclusion
The paper presents a novel approach to learning velocity-based humanoid locomotion using massively parallel learning with Brax and MJX. The researchers developed a highly scalable and efficient training process that allows virtual humanoid robots to learn a wide range of complex locomotion behaviors.
By combining the capabilities of Brax and MJX, the researchers were able to create a system that can identify optimal movement patterns for different tasks and environments, leading to more natural and effective humanoid locomotion. The paper's findings have been accepted for presentation at a major robotics conference, indicating the significance of this research within the field.
While the paper presents some potential limitations and areas for further investigation, the techniques developed in this study represent an important step forward in the development of more agile and capable humanoid robots. The ability to train robots to move and interact with the world in a more natural and effective way could have far-reaching implications for a variety of applications, from assistive robotics to humanoid interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Velocity-based Humanoid Locomotion: Massively Parallel Learning with Brax and MJX
William Thibault, William Melek, Katja Mombaur
Humanoid locomotion is a key skill to bring humanoids out of the lab and into the real-world. Many motion generation methods for locomotion have been proposed including reinforcement learning (RL). RL locomotion policies offer great versatility and generalizability along with the ability to experience new knowledge to improve over time. This work presents a velocity-based RL locomotion policy for the REEM-C robot. The policy uses a periodic reward formulation and is implemented in Brax/MJX for fast training. Simulation results for the policy are demonstrated with future experimental results in progress.
Read more7/9/2024

0
Learning Skateboarding for Humanoid Robots through Massively Parallel Reinforcement Learning
William Thibault, Vidyasagar Rajendran, William Melek, Katja Mombaur
Learning-based methods have proven useful at generating complex motions for robots, including humanoids. Reinforcement learning (RL) has been used to learn locomotion policies, some of which leverage a periodic reward formulation. This work extends the periodic reward formulation of locomotion to skateboarding for the REEM-C robot. Brax/MJX is used to implement the RL problem to achieve fast training. Initial results in simulation are presented with hardware experiments in progress.
Read more9/14/2024

0
Exciting Action: Investigating Efficient Exploration for Learning Musculoskeletal Humanoid Locomotion
Henri-Jacques Gei{ss}, Firas Al-Hafez, Andre Seyfarth, Jan Peters, Davide Tateo
Learning a locomotion controller for a musculoskeletal system is challenging due to over-actuation and high-dimensional action space. While many reinforcement learning methods attempt to address this issue, they often struggle to learn human-like gaits because of the complexity involved in engineering an effective reward function. In this paper, we demonstrate that adversarial imitation learning can address this issue by analyzing key problems and providing solutions using both current literature and novel techniques. We validate our methodology by learning walking and running gaits on a simulated humanoid model with 16 degrees of freedom and 92 Muscle-Tendon Units, achieving natural-looking gaits with only a few demonstrations.
Read more7/17/2024
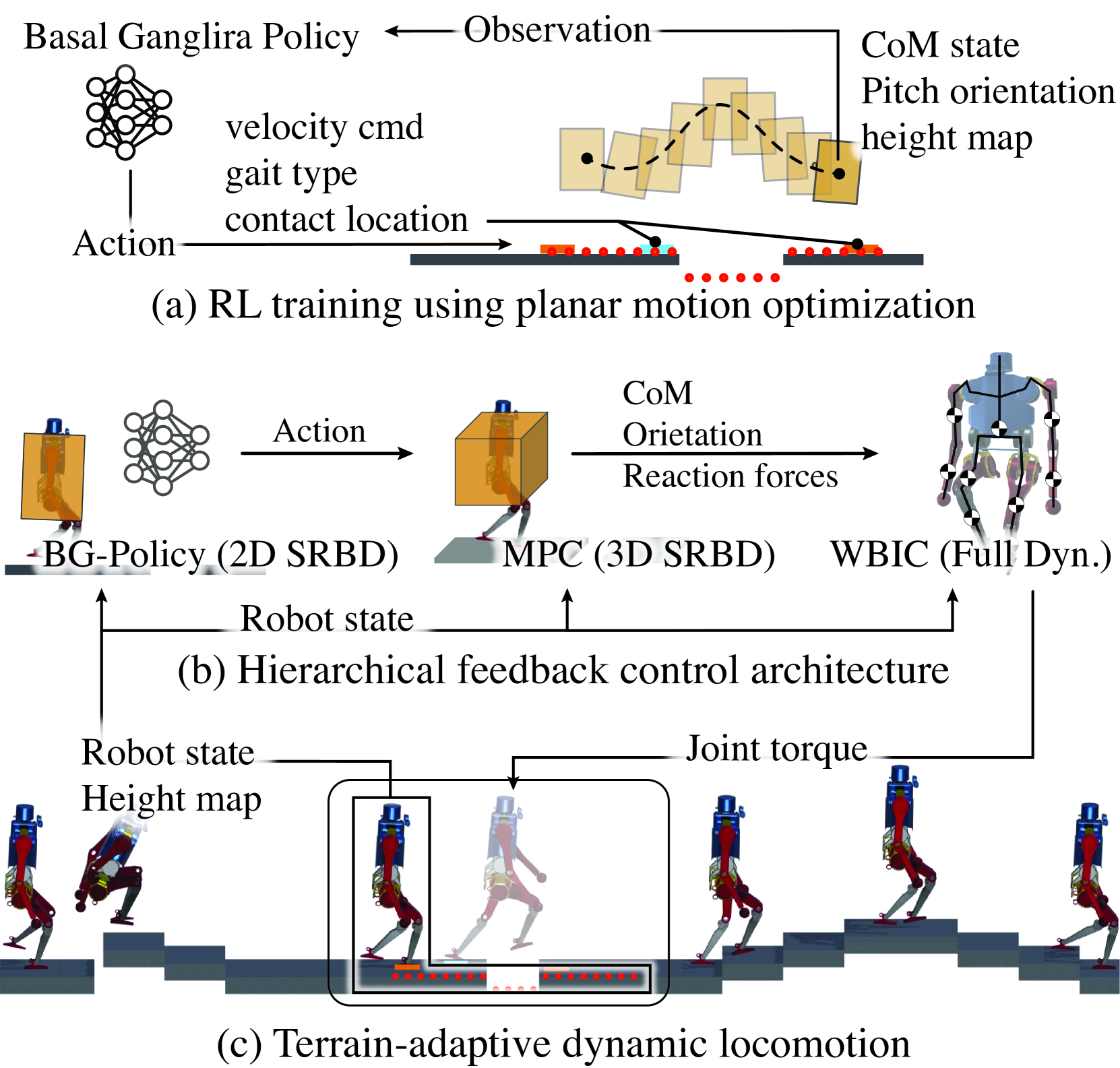
0
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Read more7/30/2024