Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs

0

Sign in to get full access
Overview
- This paper explores the role of in-context examples in regression tasks using large language models (LLMs).
- The researchers investigate whether LLMs primarily learn from the provided examples (learning) or simply retrieve relevant information (retrieval).
- They conduct experiments to understand how in-context examples affect model performance and generalization.
Plain English Explanation
The paper examines how large language models (LLMs) like GPT-3 use the examples provided during a task to make predictions. Specifically, the researchers want to understand if the models are truly learning from the examples or simply retrieving relevant information from their training data.
For example, if you ask an LLM to predict the price of a house given some information about the property, does the model use the example house prices you provided to learn how to make better predictions, or does it simply recall similar houses it has seen before? This distinction between learning and retrieval is important for understanding how these powerful models work and how we can best use them.
The researchers design experiments to tease apart the learning and retrieval behaviors of LLMs in regression tasks, where the goal is to predict a numerical value. By analyzing the models' performance and generalization, they aim to shed light on the underlying mechanisms at play.
Technical Explanation
The paper focuses on studying the role of in-context examples in regression tasks with large language models (LLMs). The researchers investigate whether LLMs primarily learn from the provided examples or simply retrieve relevant information from their training data.
To this end, they conduct a series of experiments on regression tasks, where the models are asked to predict a numeric output given some input features. The key manipulations are:
- In-context examples: The researchers vary the number and relevance of example inputs and outputs provided to the LLM during the task.
- Model performance: They measure the models' prediction accuracy on both the provided examples and new, unseen test cases.
- Generalization: The researchers analyze how well the models generalize their learned knowledge to make predictions on test cases that differ from the examples.
By analyzing the models' behavior under these different conditions, the researchers aim to understand whether the LLMs are primarily learning from the examples or simply retrieving relevant information from their training. This has important implications for how we can best leverage these powerful models for real-world applications.
Critical Analysis
The paper presents a thoughtful and systematic investigation into the learning and retrieval behaviors of large language models in regression tasks. The experimental design and analysis provide valuable insights into the underlying mechanisms of these models.
One potential limitation is the specific focus on regression tasks, as the findings may not generalize directly to other problem domains, such as classification or generation. However, the researchers acknowledge this and suggest that future work could explore the learning-retrieval dynamics in a broader range of tasks.
Additionally, the paper does not delve deeply into the architectural details or training procedures of the LLMs used in the experiments. A more comprehensive understanding of how these factors might influence the observed behaviors could further strengthen the analysis.
Overall, the paper makes a valuable contribution to the understanding of large language models and highlights the importance of closely examining their learning and reasoning processes. The insights gained from this research can inform the development of more effective and transparent AI systems.
Conclusion
This paper provides an insightful investigation into the role of in-context examples in regression tasks using large language models. The researchers explore whether LLMs primarily learn from the provided examples or simply retrieve relevant information from their training data.
Through carefully designed experiments, the study sheds light on the underlying mechanisms of these powerful models, revealing important implications for how we can best leverage them in real-world applications. The findings suggest that a nuanced understanding of the learning-retrieval dynamics is crucial for developing more effective and transparent AI systems.
The paper's contribution to the understanding of large language models is a valuable step forward in the field of artificial intelligence, and the insights gained can inspire further research and innovative applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
Generative Large Language Models (LLMs) are capable of being in-context learners. However, the underlying mechanism of in-context learning (ICL) is still a major research question, and experimental research results about how models exploit ICL are not always consistent. In this work, we propose a framework for evaluating in-context learning mechanisms, which we claim are a combination of retrieving internal knowledge and learning from in-context examples by focusing on regression tasks. First, we show that LLMs can perform regression on real-world datasets and then design experiments to measure the extent to which the LLM retrieves its internal knowledge versus learning from in-context examples. We argue that this process lies on a spectrum between these two extremes. We provide an in-depth analysis of the degrees to which these mechanisms are triggered depending on various factors, such as prior knowledge about the tasks and the type and richness of the information provided by the in-context examples. We employ three LLMs and utilize multiple datasets to corroborate the robustness of our findings. Our results shed light on how to engineer prompts to leverage meta-learning from in-context examples and foster knowledge retrieval depending on the problem being addressed.
Read more9/9/2024

0
Large Language Models Know What Makes Exemplary Contexts
Quanyu Long, Jianda Chen, Wenya Wang, Sinno Jialin Pan
In-context learning (ICL) has proven to be a significant capability with the advancement of Large Language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without needing to update millions of parameters. This paper presents a unified framework for LLMs that allows them to self-select influential in-context examples to compose their contexts; self-rank candidates with different demonstration compositions; self-optimize the demonstration selection and ordering through reinforcement learning. Specifically, our method designs a parameter-efficient retrieval head that generates the optimized demonstration after training with rewards from LLM's own preference. Experimental results validate the proposed method's effectiveness in enhancing ICL performance. Additionally, our approach effectively identifies and selects the most representative examples for the current task, and includes more diversity in retrieval.
Read more8/21/2024
🌿
0
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
Read more6/19/2024
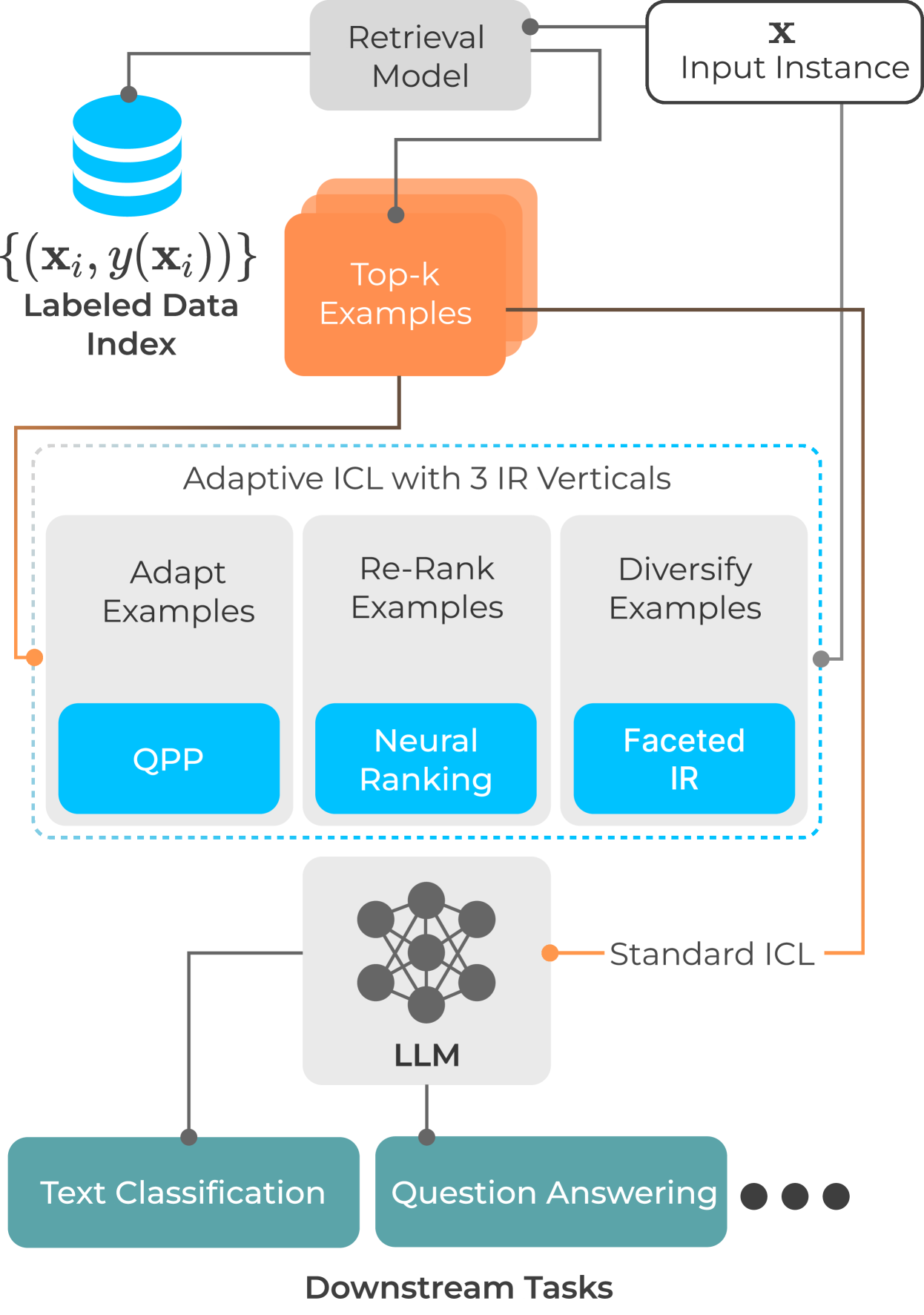
0
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
Read more5/3/2024