Learnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech

0

Sign in to get full access
Overview
- Curating a trustworthy, well-annotated dataset of disordered English speech
- Expanding data diversity to improve speech recognition systems
- Identifying and addressing biases in automatic transcription
Plain English Explanation
The provided paper discusses the lessons learned from curating a dataset of disordered English speech. This is an important task, as speech recognition systems often struggle with non-standard speech patterns, leading to inaccuracies and biases in the transcribed text.
By expanding the diversity of the dataset, the researchers aimed to improve the performance of these systems and make them more inclusive. This involves collecting speech samples from a wider range of speakers, including those with speech disorders, non-native speakers, and others who may not conform to the "standard" speech patterns.
The paper also discusses the challenges of accurately transcribing disfluent or non-standard speech, and the potential biases that can arise in the automatic transcription process. The researchers explored ways to annotate the speech in a more detailed and useful manner, to support the development of more inclusive and accurate speech recognition systems.
Technical Explanation
The paper describes the process of curating a dataset of disordered English speech, which includes samples from speakers with a variety of speech disorders, non-native speakers, and other individuals whose speech patterns may not fit the "standard" model.
The researchers collected a diverse range of speech samples and annotated them with detailed information, such as phonemic and prosodic features. This allowed for the development of more comprehensive speech recognition models that can better handle non-standard speech patterns.
The paper also explores the challenges of accurately transcribing disfluent or non-standard speech, and the potential biases that can arise in the automatic transcription process. The researchers investigated methods to identify and quantify these biases, with the goal of developing more inclusive and accurate speech recognition systems.
Critical Analysis
The paper presents a valuable contribution to the field of speech recognition, particularly in addressing the challenges of handling disordered or non-standard speech patterns. By expanding the diversity of the dataset and exploring methods to accurately annotate the speech samples, the researchers have laid the groundwork for the development of more inclusive speech recognition systems.
However, the paper does not delve deeply into the potential limitations or caveats of the research. For example, it would be interesting to understand the extent to which the curated dataset is representative of the full spectrum of disordered speech patterns, and whether there are any biases or gaps in the data collection process.
Additionally, the paper could have explored the potential ethical implications of developing more accurate speech recognition systems for individuals with speech disorders, such as privacy concerns or the risk of perpetuating stigma.
Conclusion
The provided paper highlights the importance of curating diverse and well-annotated datasets to improve the performance and inclusivity of speech recognition systems. By focusing on disordered English speech, the researchers have made a significant contribution to the field, laying the foundation for more accurate and accessible speech recognition technologies.
The insights and methodologies presented in this paper have the potential to benefit a wide range of applications, from assistive technologies for individuals with speech disorders to more inclusive voice interfaces for diverse populations. As the field of speech recognition continues to evolve, this research serves as a valuable reference for addressing the challenges of non-standard speech patterns and promoting equitable access to these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech
Pan-Pan Jiang, Jimmy Tobin, Katrin Tomanek, Robert L. MacDonald, Katie Seaver, Richard Cave, Marilyn Ladewig, Rus Heywood, Jordan R. Green
Project Euphonia, a Google initiative, is dedicated to improving automatic speech recognition (ASR) of disordered speech. A central objective of the project is to create a large, high-quality, and diverse speech corpus. This report describes the project's latest advancements in data collection and annotation methodologies, such as expanding speaker diversity in the database, adding human-reviewed transcript corrections and audio quality tags to 350K (of the 1.2M total) audio recordings, and amassing a comprehensive set of metadata (including more than 40 speech characteristic labels) for over 75% of the speakers in the database. We report on the impact of transcript corrections on our machine-learning (ML) research, inter-rater variability of assessments of disordered speech patterns, and our rationale for gathering speech metadata. We also consider the limitations of using automated off-the-shelf annotation methods for assessing disordered speech.
Read more9/17/2024

0
LearnerVoice: A Dataset of Non-Native English Learners' Spontaneous Speech
Haechan Kim, Junho Myung, Seoyoung Kim, Sungpah Lee, Dongyeop Kang, Juho Kim
Prevalent ungrammatical expressions and disfluencies in spontaneous speech from second language (L2) learners pose unique challenges to Automatic Speech Recognition (ASR) systems. However, few datasets are tailored to L2 learner speech. We publicly release LearnerVoice, a dataset consisting of 50.04 hours of audio and transcriptions of L2 learners' spontaneous speech. Our linguistic analysis reveals that transcriptions in our dataset contain L2S (L2 learner's Spontaneous speech) features, consisting of ungrammatical expressions and disfluencies (e.g., filler words, word repetitions, self-repairs, false starts), significantly more than native speech datasets. Fine-tuning whisper-small.en with LearnerVoice achieves a WER of 10.26%, 44.2% lower than vanilla whisper-small.en. Furthermore, our qualitative analysis indicates that 54.2% of errors from the vanilla model on LearnerVoice are attributable to L2S features, with 48.1% of them being reduced in the fine-tuned model.
Read more7/8/2024

0
Inclusive ASR for Disfluent Speech: Cascaded Large-Scale Self-Supervised Learning with Targeted Fine-Tuning and Data Augmentation
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Caryn Herring, Jia Bin
Automatic speech recognition (ASR) systems often falter while processing stuttering-related disfluencies -- such as involuntary blocks and word repetitions -- yielding inaccurate transcripts. A critical barrier to progress is the scarcity of large, annotated disfluent speech datasets. Therefore, we present an inclusive ASR design approach, leveraging large-scale self-supervised learning on standard speech followed by targeted fine-tuning and data augmentation on a smaller, curated dataset of disfluent speech. Our data augmentation technique enriches training datasets with various disfluencies, enhancing ASR processing of these speech patterns. Results show that fine-tuning wav2vec 2.0 with even a relatively small, labeled dataset, alongside data augmentation, can significantly reduce word error rates for disfluent speech. Our approach not only advances ASR inclusivity for people who stutter, but also paves the way for ASRs that can accommodate wider speech variations.
Read more6/17/2024
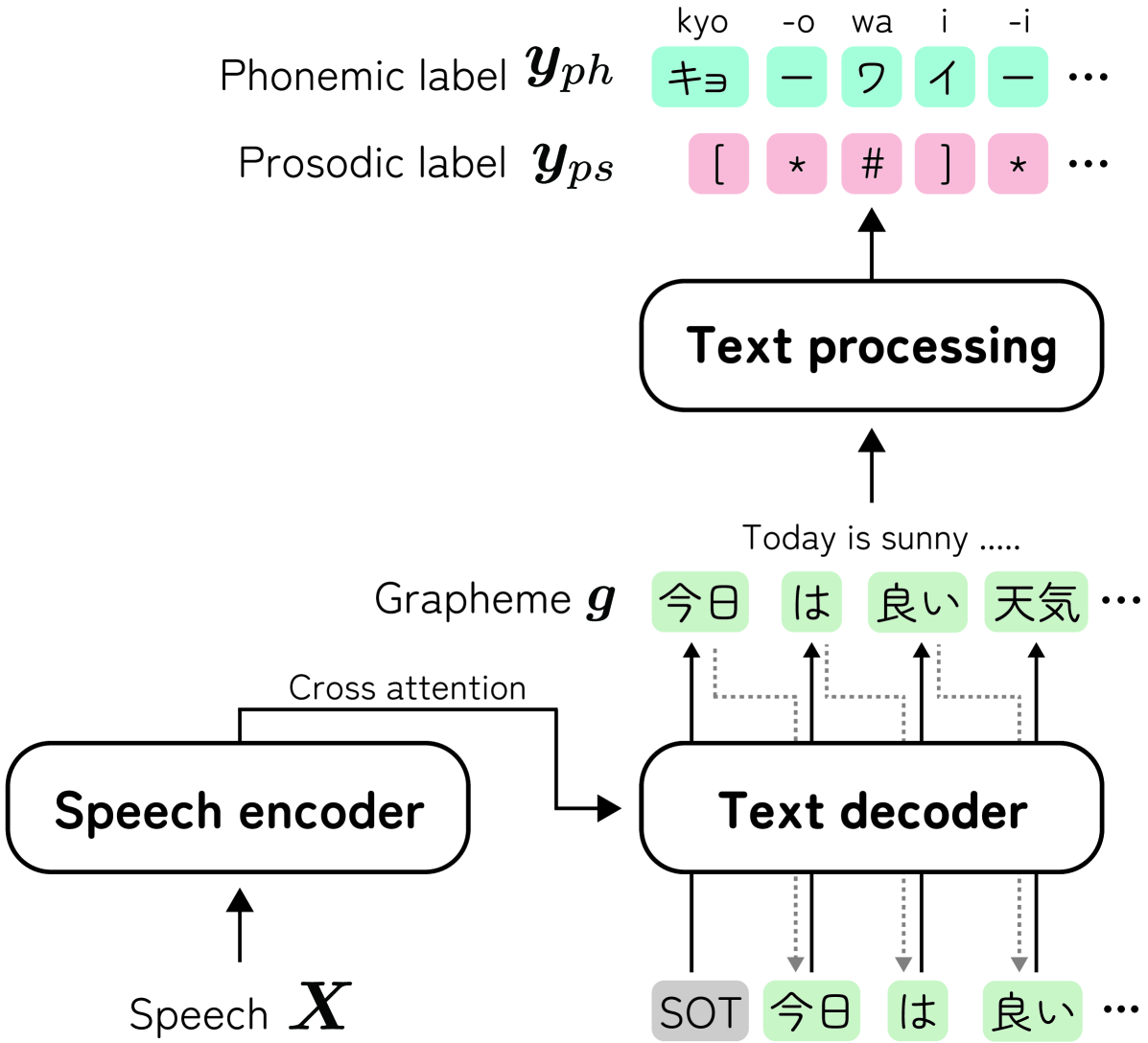
0
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Yuma Shirahata, Byeongseon Park, Ryuichi Yamamoto, Kentaro Tachibana
This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
Read more6/13/2024