Legal Minds, Algorithmic Decisions: How LLMs Apply Constitutional Principles in Complex Scenarios

0
Sign in to get full access
Overview
- The paper examines how large language models (LLMs) apply constitutional principles in complex legal scenarios.
- It explores the ability of LLMs to reason about constitutional rights and principles in hypothetical cases.
- The research provides insights into the potential implications of using LLMs for high-stakes decision-making.
Plain English Explanation
The paper investigates how advanced AI language models, known as large language models (LLMs), handle complex legal and constitutional questions. LLMs are trained on massive amounts of text data, which allows them to understand and generate human-like language. The researchers were interested in seeing how these LLMs would apply constitutional principles and rights when presented with hypothetical legal scenarios.
The researchers created a dataset of challenging legal cases that involved constitutional issues, such as freedom of speech, due process, and equal protection. They then had the LLMs analyze these cases and provide their reasoning for how they would rule on the legal questions. The goal was to better understand the capabilities and limitations of LLMs when it comes to high-stakes decision-making that requires nuanced legal and ethical reasoning.
The findings suggest that LLMs can provide thoughtful and principled responses to these complex legal cases, often citing relevant constitutional provisions and case law to support their decisions. However, the researchers also identified areas where the LLMs struggled, such as fully grasping the context and potential societal impacts of their rulings. The paper highlights the need for careful oversight and human involvement when using LLMs for tasks that have significant real-world consequences.
Technical Explanation
The researchers constructed a dataset of 100 hypothetical legal scenarios that involved complex constitutional issues, such as freedom of speech, due process, and equal protection. These cases were designed to be ambiguous and challenging, requiring nuanced legal reasoning to navigate the tradeoffs between individual rights and societal interests.
They then evaluated the performance of several state-of-the-art LLMs, including GPT-3, BERT, and T5, in analyzing these legal cases and providing justifications for their rulings. The LLMs were instructed to review the case details, identify the relevant constitutional principles at play, and explain their legal reasoning and ultimate decision.
The researchers found that the LLMs were generally able to recognize the key constitutional issues and provide principled arguments to support their rulings. They often cited specific constitutional provisions, Supreme Court precedents, and legal doctrines to justify their decisions. However, the LLMs also exhibited some limitations, such as a tendency to overlook important contextual factors or to struggle with balancing competing rights and interests.
Additionally, the researchers noted that the LLMs' responses could be inconsistent across different runs, highlighting the need for further work to improve the reliability and robustness of these models when applied to high-stakes decision-making.
Critical Analysis
The paper provides a valuable contribution to understanding the potential and limitations of using LLMs for legal decision-making. The researchers should be commended for their thoughtful approach in designing a challenging dataset of hypothetical legal scenarios that capture the nuances and complexities of constitutional law.
One notable strength of the study is its focus on not just the final decisions made by the LLMs, but also their reasoning and justifications. This provides important insights into the models' ability to engage in the type of detailed, context-sensitive analysis that is central to legal reasoning.
However, the paper also acknowledges some key limitations and areas for further research. For example, the researchers note that the LLMs' responses could be inconsistent across different runs, which raises concerns about the reliability and reproducibility of their decision-making. Additionally, the paper highlights the models' tendency to overlook important contextual factors, which could lead to flawed or biased rulings in real-world settings.
Moving forward, it will be important to continue exploring ways to improve the robustness and accountability of LLMs when applied to high-stakes decision-making. This may involve developing more comprehensive datasets, refining the models' training and evaluation procedures, and implementing stronger oversight and transparency mechanisms.
Conclusion
This paper provides valuable insights into the capabilities and limitations of using LLMs for legal decision-making that involves complex constitutional principles. While the models demonstrated an impressive ability to reason about constitutional rights and apply legal precedents, the research also identified areas where they struggled to fully capture the nuances and societal implications of their rulings.
As LLMs become more advanced and integrated into high-stakes decision-making processes, it will be crucial to carefully consider the ethical and legal implications of their use. The findings of this paper suggest that while LLMs hold promise as tools to assist legal professionals, they should not be treated as infallible or fully autonomous decision-makers. Ongoing research, oversight, and human involvement will be essential to ensure that the application of these powerful AI systems aligns with fundamental constitutional principles and societal values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Legal Minds, Algorithmic Decisions: How LLMs Apply Constitutional Principles in Complex Scenarios
Camilla Bignotti, Carolina Camassa
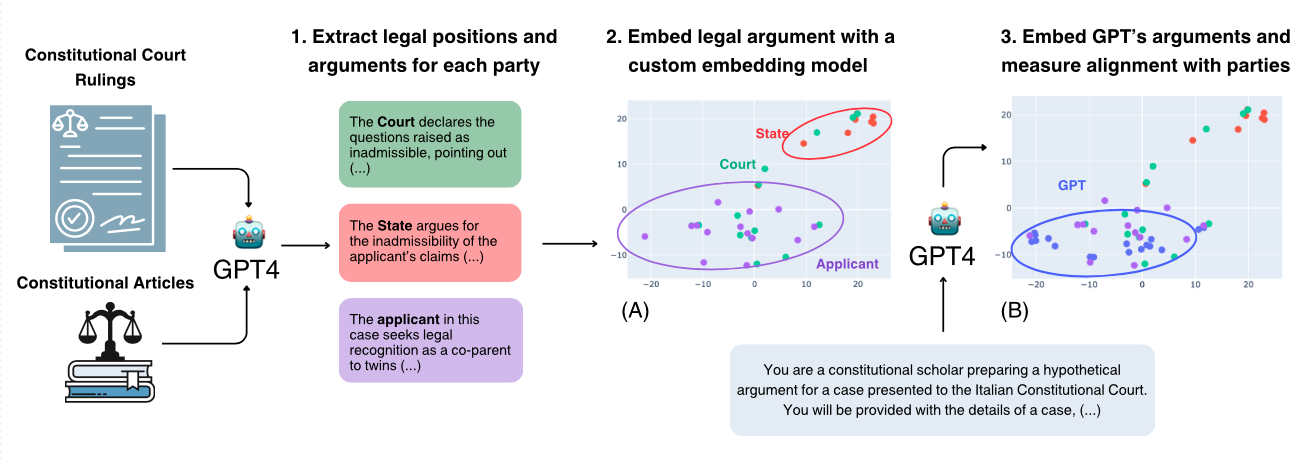
In this paper, we conduct an empirical analysis of how large language models (LLMs), specifically GPT-4, interpret constitutional principles in complex decision-making scenarios. We examine rulings from the Italian Constitutional Court on bioethics issues that involve trade-offs between competing values and compare model-generated legal arguments on these issues to those presented by the State, the Court, and the applicants. Our results indicate that GPT-4 consistently aligns more closely with progressive interpretations of the Constitution, often overlooking competing values and mirroring the applicants' views rather than the more conservative perspectives of the State or the Court's moderate positions. Our experiments reveal a distinct tendency of GPT-4 to favor progressive legal interpretations, underscoring the influence of underlying data biases. We thus underscore the importance of testing alignment in real-world scenarios and considering the implications of deploying LLMs in decision-making processes.
Read more8/12/2024
👨🏫
0
Towards Human-Level Text Coding with LLMs: The Case of Fatherhood Roles in Public Policy Documents
Lorenzo Lupo, Oscar Magnusson, Dirk Hovy, Elin Naurin, Lena Wangnerud
Recent advances in large language models (LLMs) like GPT-3.5 and GPT-4 promise automation with better results and less programming, opening up new opportunities for text analysis in political science. In this study, we evaluate LLMs on three original coding tasks involving typical complexities encountered in political science settings: a non-English language, legal and political jargon, and complex labels based on abstract constructs. Along the paper, we propose a practical workflow to optimize the choice of the model and the prompt. We find that the best prompting strategy consists of providing the LLMs with a detailed codebook, as the one provided to human coders. In this setting, an LLM can be as good as or possibly better than a human annotator while being much faster, considerably cheaper, and much easier to scale to large amounts of text. We also provide a comparison of GPT and popular open-source LLMs, discussing the trade-offs in the model's choice. Our software allows LLMs to be easily used as annotators and is publicly available: https://github.com/lorelupo/pappa.
Read more8/29/2024
💬
0
On Large Language Models in National Security Applications
William N. Caballero, Phillip R. Jenkins
The overwhelming success of GPT-4 in early 2023 highlighted the transformative potential of large language models (LLMs) across various sectors, including national security. This article explores the implications of LLM integration within national security contexts, analyzing their potential to revolutionize information processing, decision-making, and operational efficiency. Whereas LLMs offer substantial benefits, such as automating tasks and enhancing data analysis, they also pose significant risks, including hallucinations, data privacy concerns, and vulnerability to adversarial attacks. Through their coupling with decision-theoretic principles and Bayesian reasoning, LLMs can significantly improve decision-making processes within national security organizations. Namely, LLMs can facilitate the transition from data to actionable decisions, enabling decision-makers to quickly receive and distill available information with less manpower. Current applications within the US Department of Defense and beyond are explored, e.g., the USAF's use of LLMs for wargaming and automatic summarization, that illustrate their potential to streamline operations and support decision-making. However, these applications necessitate rigorous safeguards to ensure accuracy and reliability. The broader implications of LLM integration extend to strategic planning, international relations, and the broader geopolitical landscape, with adversarial nations leveraging LLMs for disinformation and cyber operations, emphasizing the need for robust countermeasures. Despite exhibiting sparks of artificial general intelligence, LLMs are best suited for supporting roles rather than leading strategic decisions. Their use in training and wargaming can provide valuable insights and personalized learning experiences for military personnel, thereby improving operational readiness.
Read more7/8/2024
0
Large Language Model in Financial Regulatory Interpretation
Zhiyu Cao, Zachary Feinstein
This study explores the innovative use of Large Language Models (LLMs) as analytical tools for interpreting complex financial regulations. The primary objective is to design effective prompts that guide LLMs in distilling verbose and intricate regulatory texts, such as the Basel III capital requirement regulations, into a concise mathematical framework that can be subsequently translated into actionable code. This novel approach aims to streamline the implementation of regulatory mandates within the financial reporting and risk management systems of global banking institutions. A case study was conducted to assess the performance of various LLMs, demonstrating that GPT-4 outperforms other models in processing and collecting necessary information, as well as executing mathematical calculations. The case study utilized numerical simulations with asset holdings -- including fixed income, equities, currency pairs, and commodities -- to demonstrate how LLMs can effectively implement the Basel III capital adequacy requirements. Keywords: Large Language Models, Prompt Engineering, LLMs in Finance, Basel III, Minimum Capital Requirements, LLM Ethics
Read more7/11/2024