Towards Human-Level Text Coding with LLMs: The Case of Fatherhood Roles in Public Policy Documents

0
👨🏫
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) like GPT-3.5 and GPT-4 for text analysis tasks in political science.
- The researchers evaluate LLMs on three coding tasks that involve complexities commonly found in political science research, such as non-English language, legal and political jargon, and abstract constructs.
- The paper proposes a practical workflow to optimize the choice of LLM and the prompting strategy for these tasks.
- The key finding is that providing LLMs with a detailed codebook, similar to what is given to human coders, allows them to perform as well as or potentially better than human annotators, while being faster, cheaper, and more scalable.
Plain English Explanation
[Overview of Large Language Models (LLMs) and their Potential for Political Science Research]
Large language models (LLMs) like GPT-3.5 and GPT-4 are powerful artificial intelligence systems that can understand and generate human-like text. Researchers in this study wanted to explore how these LLMs could be used to automate text analysis tasks in political science research.
[Evaluating LLMs on Challenging Political Science Coding Tasks]
The researchers tested the LLMs on three specific coding tasks that are typical in political science research. These tasks involved:
- Working with non-English language text
- Handling legal and political jargon
- Classifying text based on complex, abstract concepts
[Optimizing LLM Performance Through Prompting]
The researchers found that the key to getting the best results from the LLMs was to provide them with a detailed "codebook" - the same kind of information that would be given to human coders. This allowed the LLMs to understand the context and nuances of the coding task, and perform as well as or even better than human annotators.
[Advantages of Using LLMs for Text Analysis]
Compared to human coders, the LLMs were much faster, considerably cheaper, and easier to scale up to large amounts of text. This opens up new possibilities for automating text analysis in political science research, which often involves processing large volumes of documents.
Technical Explanation
The researchers evaluated the performance of large language models (LLMs) like GPT-3.5 and GPT-4 on three text coding tasks that are commonly encountered in political science research:
- Non-English Language: Coding text in a language other than English, which tests the LLM's ability to handle linguistic complexity.
- Legal and Political Jargon: Coding text that contains specialized vocabulary and concepts from the legal and political domains.
- Complex Labels based on Abstract Constructs: Classifying text based on abstract, multidimensional concepts that require deep understanding of the context.
To optimize the LLM's performance, the researchers explored different prompting strategies. They found that providing the LLM with a detailed "codebook" - the same kind of guidance given to human coders - resulted in the best performance, allowing the LLM to match or exceed human-level accuracy while being much faster and more cost-effective.
The researchers also compared the performance of GPT models to popular open-source LLMs, discussing the trade-offs in terms of accuracy, speed, and cost. They provide an open-source software tool (https://github.com/lorelupo/pappa) that makes it easy to use LLMs as automated annotators for text analysis tasks.
Critical Analysis
The researchers have provided a compelling case for using large language models (LLMs) to automate text analysis tasks in political science research. By testing the LLMs on specific complexities commonly encountered in this domain, they have demonstrated the potential for these models to match or surpass human-level performance.
However, the study does not address some important caveats and limitations:
[Potential Biases and Lack of Contextual Understanding] While the LLMs may perform well on the specific coding tasks, they may still lack the deeper contextual understanding and nuanced judgment that human coders can bring to the analysis of political texts. There is a risk of the LLMs reflecting societal biases present in their training data.
[Generalizability and Scalability Concerns] The study focuses on a limited set of coding tasks and datasets. More research is needed to determine how well the findings would generalize to a wider range of political science research questions and text corpora.
[Ethical Considerations of Automating Text Analysis] The ease and scalability of using LLMs for text analysis raises important ethical questions about the responsible use of these technologies, particularly in sensitive domains like political research.
Overall, the researchers have made a valuable contribution by demonstrating the potential of LLMs for text analysis in political science. However, additional research and careful consideration of the limitations and ethical implications will be crucial as these technologies become more widely adopted.
Conclusion
This study explores the use of large language models (LLMs) like GPT-3.5 and GPT-4 for automating text analysis tasks in political science research. The researchers found that by providing LLMs with a detailed "codebook" similar to what is given to human coders, the models can perform as well as or even better than human annotators on tasks involving non-English language, legal and political jargon, and complex abstract constructs.
The key advantages of using LLMs for these tasks are their speed, cost-effectiveness, and scalability, which could dramatically improve the efficiency of text analysis in political science research. However, the study also highlights the need to carefully consider the potential biases, limitations, and ethical implications of these powerful AI technologies.
As LLMs continue to advance, their application in fields like political science offers exciting opportunities, but also requires thoughtful implementation and ongoing evaluation to ensure responsible and effective use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Towards Human-Level Text Coding with LLMs: The Case of Fatherhood Roles in Public Policy Documents
Lorenzo Lupo, Oscar Magnusson, Dirk Hovy, Elin Naurin, Lena Wangnerud
Recent advances in large language models (LLMs) like GPT-3.5 and GPT-4 promise automation with better results and less programming, opening up new opportunities for text analysis in political science. In this study, we evaluate LLMs on three original coding tasks involving typical complexities encountered in political science settings: a non-English language, legal and political jargon, and complex labels based on abstract constructs. Along the paper, we propose a practical workflow to optimize the choice of the model and the prompt. We find that the best prompting strategy consists of providing the LLMs with a detailed codebook, as the one provided to human coders. In this setting, an LLM can be as good as or possibly better than a human annotator while being much faster, considerably cheaper, and much easier to scale to large amounts of text. We also provide a comparison of GPT and popular open-source LLMs, discussing the trade-offs in the model's choice. Our software allows LLMs to be easily used as annotators and is publicly available: https://github.com/lorelupo/pappa.
Read more8/29/2024
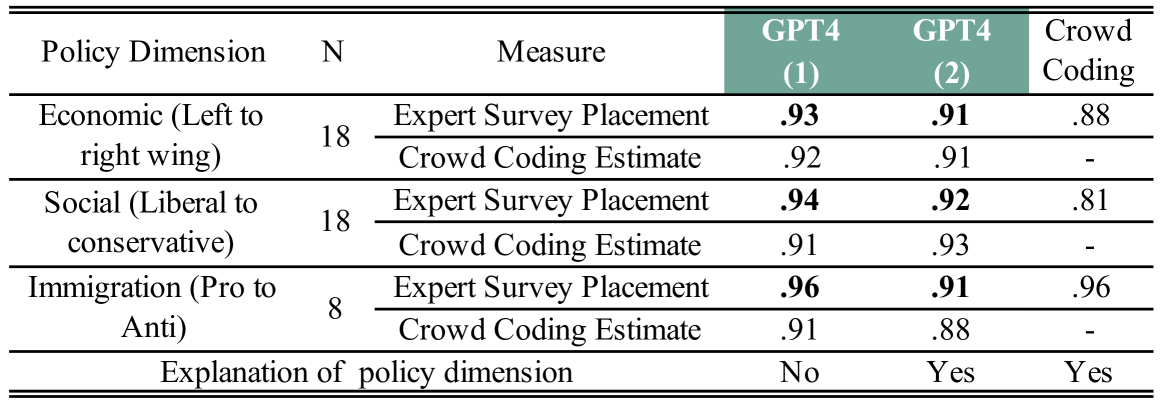
0
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
We use instruction-tuned Large Language Models (LLMs) like GPT-4, Llama 3, MiXtral, or Aya to position political texts within policy and ideological spaces. We ask an LLM where a tweet or a sentence of a political text stands on the focal dimension and take the average of the LLM responses to position political actors such as US Senators, or longer texts such as UK party manifestos or EU policy speeches given in 10 different languages. The correlations between the position estimates obtained with the best LLMs and benchmarks based on text coding by experts, crowdworkers, or roll call votes exceed .90. This approach is generally more accurate than the positions obtained with supervised classifiers trained on large amounts of research data. Using instruction-tuned LLMs to position texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
Read more9/6/2024

0
PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science
Menglin Liu, Ge Shi
Recent advancements in large language models (LLMs) have opened new avenues for enhancing text classification efficiency in political science, surpassing traditional machine learning methods that often require extensive feature engineering, human labeling, and task-specific training. However, their effectiveness in achieving high classification accuracy remains questionable. This paper introduces a three-stage in-context learning approach that leverages LLMs to improve classification accuracy while minimizing experimental costs. Our method incorporates automatic enhanced prompt generation, adaptive exemplar selection, and a consensus mechanism that resolves discrepancies between two weaker LLMs, refined by an advanced LLM. We validate our approach using datasets from the BBC news reports, Kavanaugh Supreme Court confirmation, and 2018 election campaign ads. The results show significant improvements in classification F1 score (+0.36 for zero-shot classification) with manageable economic costs (-78% compared with human labeling), demonstrating that our method effectively addresses the limitations of traditional machine learning while offering a scalable and reliable solution for text analysis in political science.
Read more9/4/2024

0
The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
Read more5/3/2024