LEMoE: Advanced Mixture of Experts Adaptor for Lifelong Model Editing of Large Language Models
2406.20030
0
0
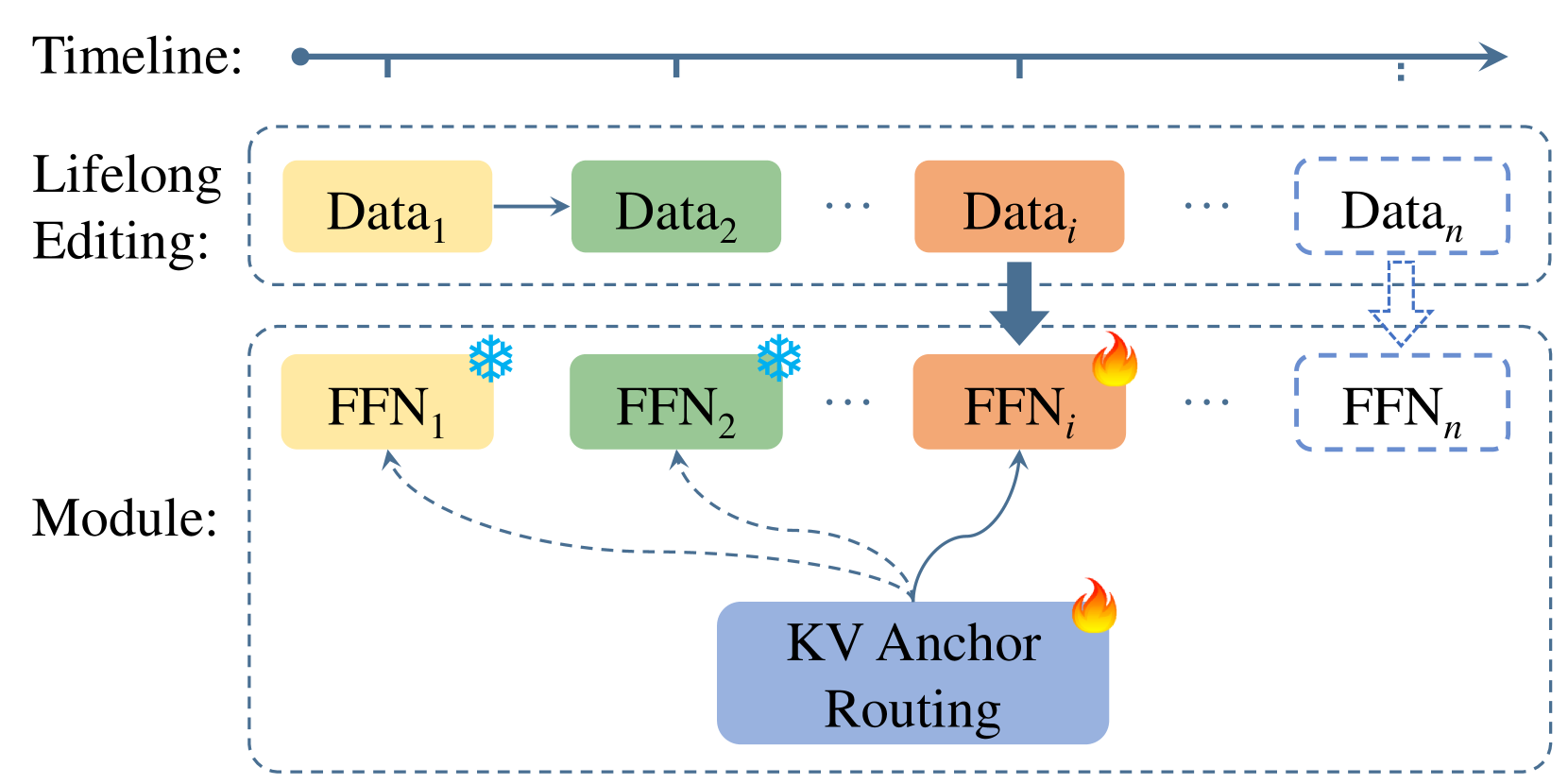
Abstract
Large language models (LLMs) require continual knowledge updates to stay abreast of the ever-changing world facts, prompting the formulation of lifelong model editing task. While recent years have witnessed the development of various techniques for single and batch editing, these methods either fail to apply or perform sub-optimally when faced with lifelong editing. In this paper, we introduce LEMoE, an advanced Mixture of Experts (MoE) adaptor for lifelong model editing. We first analyze the factors influencing the effectiveness of conventional MoE adaptor in lifelong editing, including catastrophic forgetting, inconsistent routing and order sensitivity. Based on these insights, we propose a tailored module insertion method to achieve lifelong editing, incorporating a novel KV anchor routing to enhance routing consistency between training and inference stage, along with a concise yet effective clustering-based editing order planning. Experimental results demonstrate the effectiveness of our method in lifelong editing, surpassing previous model editing techniques while maintaining outstanding performance in batch editing task. Our code will be available.
Create account to get full access
Overview
- This paper introduces LEMoE, an advanced Mixture of Experts (MoE) adaptor for lifelong model editing of large language models (LLMs).
- LEMoE builds on prior work on MoE adaptors and compositional LLMs to enable efficient and effective fine-tuning of LLMs.
- The key innovations of LEMoE include a gating mechanism to dynamically route inputs to different expert modules, a regularization technique to encourage experts to learn diverse capabilities, and a meta-learning approach to rapidly adapt the model to new tasks.
Plain English Explanation
LEMoE is a system that helps large language models (LLMs) like GPT-3 learn new skills or "edit" their knowledge and capabilities over time. LLMs are powerful AI systems that can generate human-like text, answer questions, and perform other language-related tasks. However, it's challenging to update these models with new information or skills without degrading their original capabilities.
LEMoE addresses this challenge by using a "mixture of experts" approach. Instead of having a single, monolithic model, LEMoE divides the model into several "expert" modules, each specializing in different skills or knowledge. When presented with a new task, LEMoE can dynamically route the input to the most relevant expert(s), allowing the model to rapidly adapt without forgetting what it already knows.
Additionally, LEMoE includes techniques to encourage the experts to learn diverse capabilities, and a meta-learning approach to help the model quickly adapt to new tasks. This makes the overall system more efficient and effective at lifelong learning, where the model can continuously expand its skills and knowledge over time.
Technical Explanation
The core idea behind LEMoE is to leverage a Mixture of Experts (MoE) architecture to enable efficient and effective fine-tuning of LLMs. The model consists of a shared encoder, a gating network, and multiple expert modules. The gating network dynamically routes the input to the most relevant expert(s) based on the input, allowing the model to specialize in different tasks or capabilities.
To encourage the experts to learn diverse capabilities, LEMoE employs a regularization technique that penalizes experts for producing similar outputs. This helps ensure that each expert develops unique skills and knowledge, rather than simply duplicating the work of others.
Furthermore, LEMoE uses a meta-learning approach to rapidly adapt the model to new tasks. This involves training the model to learn how to learn, so that it can quickly acquire new skills or knowledge by fine-tuning on small amounts of data. This meta-learning component is crucial for enabling lifelong model editing, where the LLM can continuously expand its capabilities without forgetting what it has learned previously.
The authors evaluate LEMoE on a range of language tasks, including text generation, question answering, and few-shot learning. The results demonstrate that LEMoE outperforms standard fine-tuning approaches, as well as other MoE-based methods like LocMoE and Self-MoE, in terms of both task performance and computational efficiency.
Critical Analysis
The authors provide a comprehensive evaluation of LEMoE, exploring its performance on a diverse set of language tasks. However, the paper does not delve into potential limitations or caveats of the approach. For example, it would be helpful to understand how the model's performance scales as the number of experts or tasks increases, or how the meta-learning component affects training time and computational resources.
Additionally, the paper does not discuss potential societal impacts or ethical considerations of LEMoE. As LLMs become more capable and flexible, it is crucial to consider how these technologies can be developed and deployed responsibly, with safeguards against misuse or unintended consequences.
Overall, the LEMoE system represents an important step forward in enabling efficient and effective lifelong learning for large language models. However, further research is needed to fully understand the implications and limitations of this approach.
Conclusion
The LEMoE system introduced in this paper addresses a key challenge in the field of large language models: how to efficiently and effectively fine-tune these powerful models to acquire new skills and knowledge over time. By leveraging a Mixture of Experts architecture with a dynamic gating mechanism, regularization techniques, and meta-learning, LEMoE demonstrates significant improvements in task performance and computational efficiency compared to standard fine-tuning approaches.
This work has important implications for the development of more capable and adaptable language AI systems, which could enable a wide range of applications, from personalized assistants to specialized domain-specific models. However, as these systems become more advanced, it will be crucial to carefully consider the ethical and societal implications of their use. Overall, the LEMoE system represents an important step forward in the field of lifelong learning for large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors
Renzhi Wang, Piji Li
0
0
Model editing aims to efficiently alter the behavior of Large Language Models (LLMs) within a desired scope, while ensuring no adverse impact on other inputs. Recent years have witnessed various model editing methods been proposed. However, these methods either exhibit poor overall performance or struggle to strike a balance between generalization and locality. We propose MEMoE, a model editing adapter utilizing a Mixture of Experts (MoE) architecture with a knowledge anchor routing strategy. MEMoE updates knowledge using a bypass MoE structure, keeping the original parameters unchanged to preserve the general ability of LLMs. And, the knowledge anchor routing ensures that inputs requiring similar knowledge are routed to the same expert, thereby enhancing the generalization of the updated knowledge. Experimental results show the superiority of our approach over both batch editing and sequential batch editing tasks, exhibiting exceptional overall performance alongside outstanding balance between generalization and locality. Our code will be available.
6/4/2024
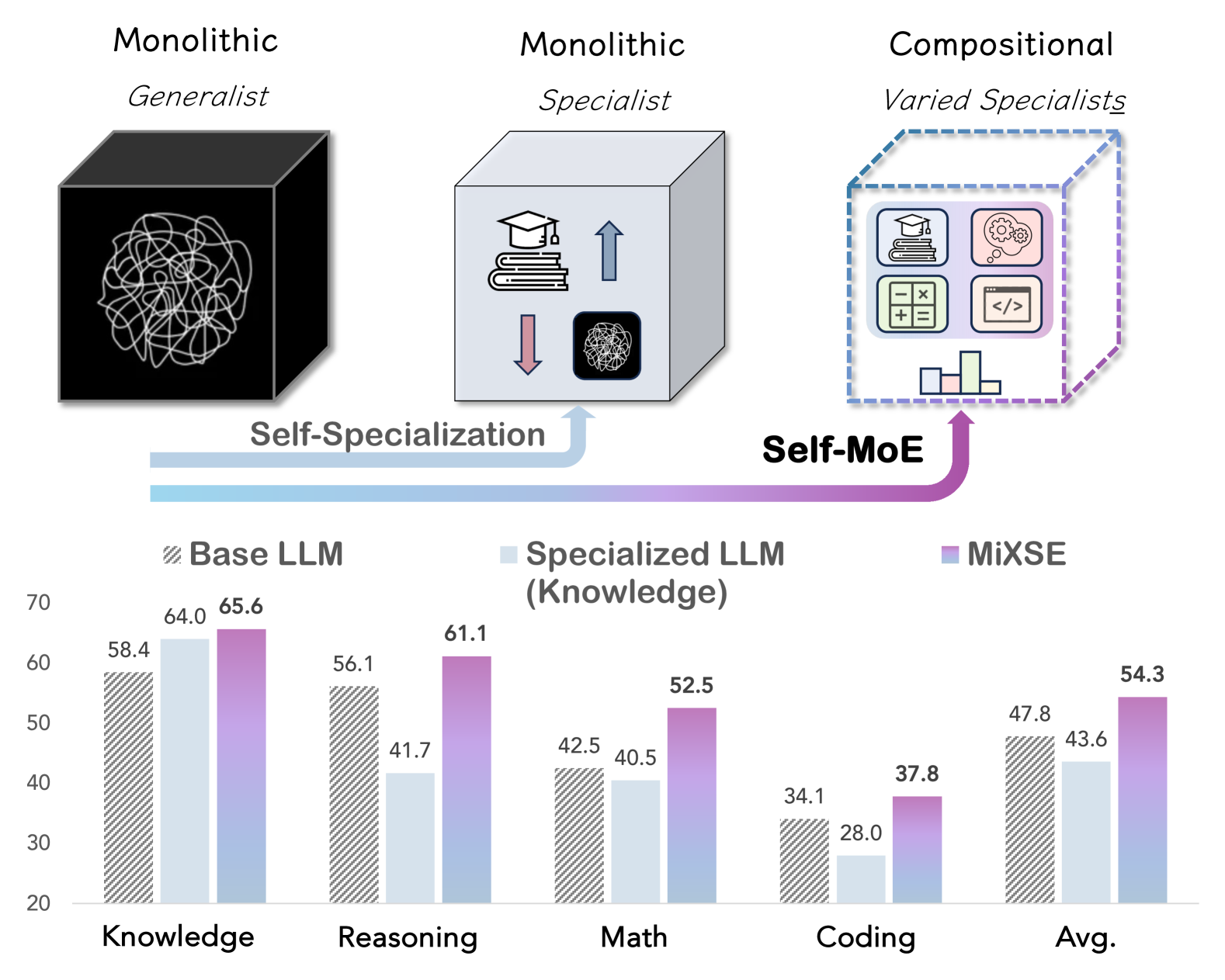
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts
Junmo Kang, Leonid Karlinsky, Hongyin Luo, Zhen Wang, Jacob Hansen, James Glass, David Cox, Rameswar Panda, Rogerio Feris, Alan Ritter
0
0
We present Self-MoE, an approach that transforms a monolithic LLM into a compositional, modular system of self-specialized experts, named MiXSE (MiXture of Self-specialized Experts). Our approach leverages self-specialization, which constructs expert modules using self-generated synthetic data, each equipped with a shared base LLM and incorporating self-optimized routing. This allows for dynamic and capability-specific handling of various target tasks, enhancing overall capabilities, without extensive human-labeled data and added parameters. Our empirical results reveal that specializing LLMs may exhibit potential trade-offs in performances on non-specialized tasks. On the other hand, our Self-MoE demonstrates substantial improvements over the base LLM across diverse benchmarks such as knowledge, reasoning, math, and coding. It also consistently outperforms other methods, including instance merging and weight merging, while offering better flexibility and interpretability by design with semantic experts and routing. Our findings highlight the critical role of modularity and the potential of self-improvement in achieving efficient, scalable, and adaptable systems.
6/19/2024
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024

LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training
Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, Yu Cheng
0
0
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, training MoE from scratch in a large-scale setting still suffers from data-hungry and instability problems. Motivated by this limit, we investigate building MoE models from existing dense large language models. Specifically, based on the well-known LLaMA-2 7B model, we obtain an MoE model by: (1) Expert Construction, which partitions the parameters of original Feed-Forward Networks (FFNs) into multiple experts; (2) Continual Pre-training, which further trains the transformed MoE model and additional gate networks. In this paper, we comprehensively explore different methods for expert construction and various data sampling strategies for continual pre-training. After these stages, our LLaMA-MoE models could maintain language abilities and route the input tokens to specific experts with part of the parameters activated. Empirically, by training 200B tokens, LLaMA-MoE-3.5B models significantly outperform dense models that contain similar activation parameters. The source codes and models are available at https://github.com/pjlab-sys4nlp/llama-moe .
6/26/2024