LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation

0
Sign in to get full access
Overview
- This paper introduces LeRF, a learning-based image interpolation method that can adaptively resample images for efficient and high-quality reconstruction.
- LeRF learns a resampling function that can be applied to low-resolution images to generate high-quality, high-resolution outputs.
- The method outperforms traditional interpolation techniques and recent learning-based approaches in terms of both visual quality and computational efficiency.
Plain English Explanation
When you take a photo with a low-resolution camera, the resulting image can look blurry or pixelated. LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation proposes a new way to fix this problem.
The key idea is to use machine learning to learn a "resampling function" that can take a low-res image and intelligently expand it into a high-quality, high-resolution version. This resampling function is adaptive, meaning it can adjust its behavior based on the content of the image.
Compared to traditional interpolation methods like bilinear or bicubic interpolation, LeRF can produce much sharper and more detailed results. It also outperforms recent learning-based approaches like IRAD in terms of both visual quality and computational efficiency.
The key innovation is the way LeRF learns the resampling function. It uses a neural network to model this function, and trains the network on a large dataset of low-res and high-res image pairs. This allows it to learn the complex patterns and relationships needed to perform high-quality image upscaling.
Technical Explanation
The core of the LeRF method is a neural network that learns a resampling function to upsample low-resolution images. This resampling function takes in the low-res input and generates a high-quality, high-resolution output.
The network architecture consists of an encoder that extracts features from the low-res input, and a decoder that uses these features to predict the resampling function. This function is then applied to the low-res image to produce the final high-res output.
An important aspect of LeRF is its adaptivity. The resampling function is not fixed, but rather can adjust its behavior based on the content of the input image. This allows it to handle a wide variety of image types and upscaling scenarios effectively.
The network is trained on a large dataset of low-res and high-res image pairs. During training, the model learns to predict the optimal resampling function that can convert the low-res input into a high-quality high-res output.
Experiments show that LeRF outperforms traditional interpolation methods as well as recent learning-based approaches like IRAD and RIFE. It achieves better visual quality while also being more computationally efficient.
Critical Analysis
The authors mention several limitations and areas for future work. For example, the current LeRF model is designed for 2D image upscaling, but the techniques could potentially be extended to 3D data like volumetric medical images or videos.
Additionally, the training process requires a large dataset of low-res and high-res image pairs, which may not always be available. Techniques to reduce the amount of supervised data needed, such as unsupervised or self-supervised learning, could be explored.
It would also be interesting to see how LeRF's performance and efficiency compares to other state-of-the-art super-resolution methods, beyond just the specific techniques mentioned in the paper.
Overall, LeRF represents a promising step forward in adaptive and efficient image interpolation. With further research and refinement, it could have significant implications for a wide range of applications that require high-quality image upscaling.
Conclusion
The LeRF method introduces a novel learning-based approach to image interpolation that can adaptively resample low-resolution images into high-quality, high-resolution outputs. By learning an optimal resampling function, LeRF outperforms traditional interpolation techniques and recent learning-based methods in terms of both visual quality and computational efficiency.
While the current work has some limitations, the core ideas behind LeRF could be extended and improved upon in future research. This could lead to even more powerful and versatile image upscaling solutions, with applications in areas like photography, video streaming, medical imaging, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation
Jiacheng Li, Chang Chen, Fenglong Song, Youliang Yan, Zhiwei Xiong
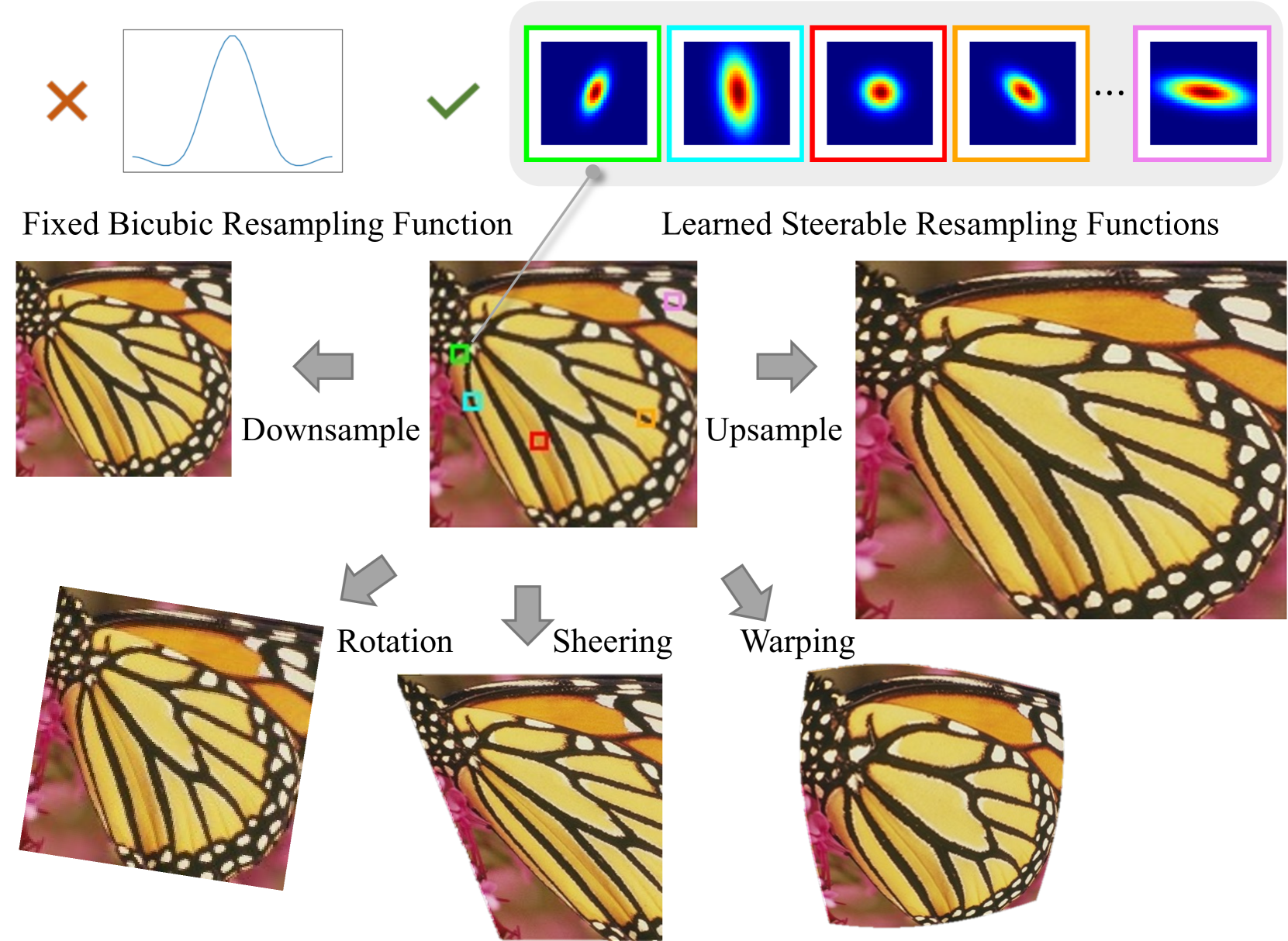
Image resampling is a basic technique that is widely employed in daily applications, such as camera photo editing. Recent deep neural networks (DNNs) have made impressive progress in performance by introducing learned data priors. Still, these methods are not the perfect substitute for interpolation, due to the drawbacks in efficiency and versatility. In this work, we propose a novel method of Learning Resampling Function (termed LeRF), which takes advantage of both the structural priors learned by DNNs and the locally continuous assumption of interpolation. Specifically, LeRF assigns spatially varying resampling functions to input image pixels and learns to predict the hyper-parameters that determine the shapes of these resampling functions with a neural network. Based on the formulation of LeRF, we develop a family of models, including both efficiency-orientated and performance-orientated ones. To achieve interpolation-level efficiency, we adopt look-up tables (LUTs) to accelerate the inference of the learned neural network. Furthermore, we design a directional ensemble strategy and edge-sensitive indexing patterns to better capture local structures. On the other hand, to obtain DNN-level performance, we propose an extension of LeRF to enable it in cooperation with pre-trained upsampling models for cascaded resampling. Extensive experiments show that the efficiency-orientated version of LeRF runs as fast as interpolation, generalizes well to arbitrary transformations, and outperforms interpolation significantly, e.g., up to 3dB PSNR gain over Bicubic for x2 upsampling on Manga109. Besides, the performance-orientated version of LeRF reaches comparable performance with existing DNNs at much higher efficiency, e.g., less than 25% running time on a desktop GPU.
Read more7/16/2024
🖼️
0
Latent Modulated Function for Computational Optimal Continuous Image Representation
Zongyao He, Zhi Jin
The recent work Local Implicit Image Function (LIIF) and subsequent Implicit Neural Representation (INR) based works have achieved remarkable success in Arbitrary-Scale Super-Resolution (ASSR) by using MLP to decode Low-Resolution (LR) features. However, these continuous image representations typically implement decoding in High-Resolution (HR) High-Dimensional (HD) space, leading to a quadratic increase in computational cost and seriously hindering the practical applications of ASSR. To tackle this problem, we propose a novel Latent Modulated Function (LMF), which decouples the HR-HD decoding process into shared latent decoding in LR-HD space and independent rendering in HR Low-Dimensional (LD) space, thereby realizing the first computational optimal paradigm of continuous image representation. Specifically, LMF utilizes an HD MLP in latent space to generate latent modulations of each LR feature vector. This enables a modulated LD MLP in render space to quickly adapt to any input feature vector and perform rendering at arbitrary resolution. Furthermore, we leverage the positive correlation between modulation intensity and input image complexity to design a Controllable Multi-Scale Rendering (CMSR) algorithm, offering the flexibility to adjust the decoding efficiency based on the rendering precision. Extensive experiments demonstrate that converting existing INR-based ASSR methods to LMF can reduce the computational cost by up to 99.9%, accelerate inference by up to 57 times, and save up to 76% of parameters, while maintaining competitive performance. The code is available at https://github.com/HeZongyao/LMF.
Read more4/26/2024

0
Realistic Extreme Image Rescaling via Generative Latent Space Learning
Ce Wang, Wanjie Sun, Zhenzhong Chen
Image rescaling aims to learn the optimal downscaled low-resolution (LR) image that can be accurately reconstructed to its original high-resolution (HR) counterpart. This process is crucial for efficient image processing and storage, especially in the era of ultra-high definition media. However, extreme downscaling factors pose significant challenges due to the highly ill-posed nature of the inverse upscaling process, causing existing methods to struggle in generating semantically plausible structures and perceptually rich textures. In this work, we propose a novel framework called Latent Space Based Image Rescaling (LSBIR) for extreme image rescaling tasks. LSBIR effectively leverages powerful natural image priors learned by a pre-trained text-to-image diffusion model to generate realistic HR images. The rescaling is performed in the latent space of a pre-trained image encoder and decoder, which offers better perceptual reconstruction quality due to its stronger sparsity and richer semantics. LSBIR adopts a two-stage training strategy. In the first stage, a pseudo-invertible encoder-decoder models the bidirectional mapping between the latent features of the HR image and the target-sized LR image. In the second stage, the reconstructed features from the first stage are refined by a pre-trained diffusion model to generate more faithful and visually pleasing details. Extensive experiments demonstrate the superiority of LSBIR over previous methods in both quantitative and qualitative evaluations. The code will be available at: https://github.com/wwangcece/LSBIR.
Read more8/20/2024

0
In-Loop Filtering via Trained Look-Up Tables
Zhuoyuan Li, Jiacheng Li, Yao Li, Li Li, Dong Liu, Feng Wu
In-loop filtering (ILF) is a key technology for removing the artifacts in image/video coding standards. Recently, neural network-based in-loop filtering methods achieve remarkable coding gains beyond the capability of advanced video coding standards, which becomes a powerful coding tool candidate for future video coding standards. However, the utilization of deep neural networks brings heavy time and computational complexity, and high demands of high-performance hardware, which is challenging to apply to the general uses of coding scene. To address this limitation, inspired by explorations in image restoration, we propose an efficient and practical in-loop filtering scheme by adopting the Look-up Table (LUT). We train the DNN of in-loop filtering within a fixed filtering reference range, and cache the output values of the DNN into a LUT via traversing all possible inputs. At testing time in the coding process, the filtered pixel is generated by locating input pixels (to-be-filtered pixel with reference pixels) and interpolating cached filtered pixel values. To further enable the large filtering reference range with the limited storage cost of LUT, we introduce the enhanced indexing mechanism in the filtering process, and clipping/finetuning mechanism in the training. The proposed method is implemented into the Versatile Video Coding (VVC) reference software, VTM-11.0. Experimental results show that the ultrafast, very fast, and fast mode of the proposed method achieves on average 0.13%/0.34%/0.51%, and 0.10%/0.27%/0.39% BD-rate reduction, under the all intra (AI) and random access (RA) configurations. Especially, our method has friendly time and computational complexity, only 101%/102%-104%/108% time increase with 0.13-0.93 kMACs/pixel, and only 164-1148 KB storage cost for a single model. Our solution may shed light on the journey of practical neural network-based coding tool evolution.
Read more9/12/2024