In-Loop Filtering via Trained Look-Up Tables

0

Sign in to get full access
Overview
- This paper presents a new in-loop filtering technique called LUT-ILF that uses a deep neural network to learn and apply look-up tables (LUTs) for efficient video coding.
- The LUT-ILF approach aims to improve the performance of the Versatile Video Coding (VVC) standard by enhancing the in-loop filtering process.
- The authors demonstrate that their LUT-ILF method can achieve significant bitrate savings compared to the default VVC in-loop filtering, with negligible quality loss.
Plain English Explanation
The paper discusses a new way to improve video compression called "in-loop filtering" using look-up tables (LUTs). In-loop filtering is a key part of modern video compression standards like Versatile Video Coding (VVC), which aim to make video files smaller without losing too much quality.
The authors' approach, called LUT-ILF, uses a type of artificial intelligence called a deep neural network to automatically learn the best LUTs to use for in-loop filtering. This allows the video encoder to apply the optimal filters to the video frames as they are being compressed, leading to better compression efficiency.
Compared to the default in-loop filtering in VVC, the LUT-ILF method can significantly reduce the file size of the compressed video (the "bitrate") with only a tiny loss in video quality. This is an important advancement, as reducing bitrate while maintaining quality is a key goal in video compression.
Technical Explanation
The paper introduces a new in-loop filtering technique called LUT-ILF that leverages deep neural networks to learn and apply custom look-up tables (LUTs) for enhanced video coding performance.
The core idea behind LUT-ILF is to replace the fixed in-loop filters used in the Versatile Video Coding (VVC) standard with a data-driven approach that can adapt to the characteristics of the input video. The authors train a deep neural network to learn the optimal LUTs for different types of video content, which can then be efficiently applied during the in-loop filtering stage of the VVC codec.
The authors demonstrate that their LUT-ILF method can achieve significant bitrate savings of up to 6.2% compared to the default VVC in-loop filtering, while maintaining nearly identical objective video quality. They also show that the LUT-ILF approach is computationally efficient, with only a modest increase in encoding time.
Critical Analysis
The paper presents a compelling approach to improving video compression efficiency through data-driven in-loop filtering. The authors provide a thorough evaluation of their LUT-ILF method, exploring various design choices and demonstrating consistent performance gains over the default VVC in-loop filtering.
One potential limitation of the LUT-ILF approach is that it requires an additional training step to learn the optimal LUTs for a given video codec and content. This could introduce additional complexity and make the system less flexible for real-world deployment, where the video content may be highly diverse. The authors acknowledge this issue and suggest further research into more adaptive or universal LUT learning techniques.
Another area for potential improvement is the incorporation of spatial-temporal information in the LUT-ILF design. The current approach focuses on spatial filtering, but taking into account the temporal evolution of video frames could lead to even greater compression gains.
Despite these minor limitations, the LUT-ILF concept represents a promising direction for enhancing the performance of modern video codecs through the judicious use of machine learning techniques. The authors have demonstrated the potential of this approach and laid the groundwork for further research and development in this area.
Conclusion
The paper presents a novel in-loop filtering technique called LUT-ILF that leverages deep neural networks to learn and apply customized look-up tables for efficient video coding. The authors show that their approach can achieve significant bitrate savings over the default in-loop filtering in the Versatile Video Coding standard, with negligible quality loss.
This work highlights the potential of data-driven methods to improve the performance of video compression algorithms, which is crucial as video content continues to dominate digital media consumption. The LUT-ILF concept offers a compelling direction for future research and development in video coding, with the possibility of further enhancing compression efficiency and quality through more advanced machine learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Loop Filtering via Trained Look-Up Tables
Zhuoyuan Li, Jiacheng Li, Yao Li, Li Li, Dong Liu, Feng Wu
In-loop filtering (ILF) is a key technology for removing the artifacts in image/video coding standards. Recently, neural network-based in-loop filtering methods achieve remarkable coding gains beyond the capability of advanced video coding standards, which becomes a powerful coding tool candidate for future video coding standards. However, the utilization of deep neural networks brings heavy time and computational complexity, and high demands of high-performance hardware, which is challenging to apply to the general uses of coding scene. To address this limitation, inspired by explorations in image restoration, we propose an efficient and practical in-loop filtering scheme by adopting the Look-up Table (LUT). We train the DNN of in-loop filtering within a fixed filtering reference range, and cache the output values of the DNN into a LUT via traversing all possible inputs. At testing time in the coding process, the filtered pixel is generated by locating input pixels (to-be-filtered pixel with reference pixels) and interpolating cached filtered pixel values. To further enable the large filtering reference range with the limited storage cost of LUT, we introduce the enhanced indexing mechanism in the filtering process, and clipping/finetuning mechanism in the training. The proposed method is implemented into the Versatile Video Coding (VVC) reference software, VTM-11.0. Experimental results show that the ultrafast, very fast, and fast mode of the proposed method achieves on average 0.13%/0.34%/0.51%, and 0.10%/0.27%/0.39% BD-rate reduction, under the all intra (AI) and random access (RA) configurations. Especially, our method has friendly time and computational complexity, only 101%/102%-104%/108% time increase with 0.13-0.93 kMACs/pixel, and only 164-1148 KB storage cost for a single model. Our solution may shed light on the journey of practical neural network-based coding tool evolution.
Read more9/12/2024
0
Taming Lookup Tables for Efficient Image Retouching
Sidi Yang, Binxiao Huang, Mingdeng Cao, Yatai Ji, Hanzhong Guo, Ngai Wong, Yujiu Yang
The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Read more7/16/2024
0
Prompt-Guided Image-Adaptive Neural Implicit Lookup Tables for Interpretable Image Enhancement
Satoshi Kosugi
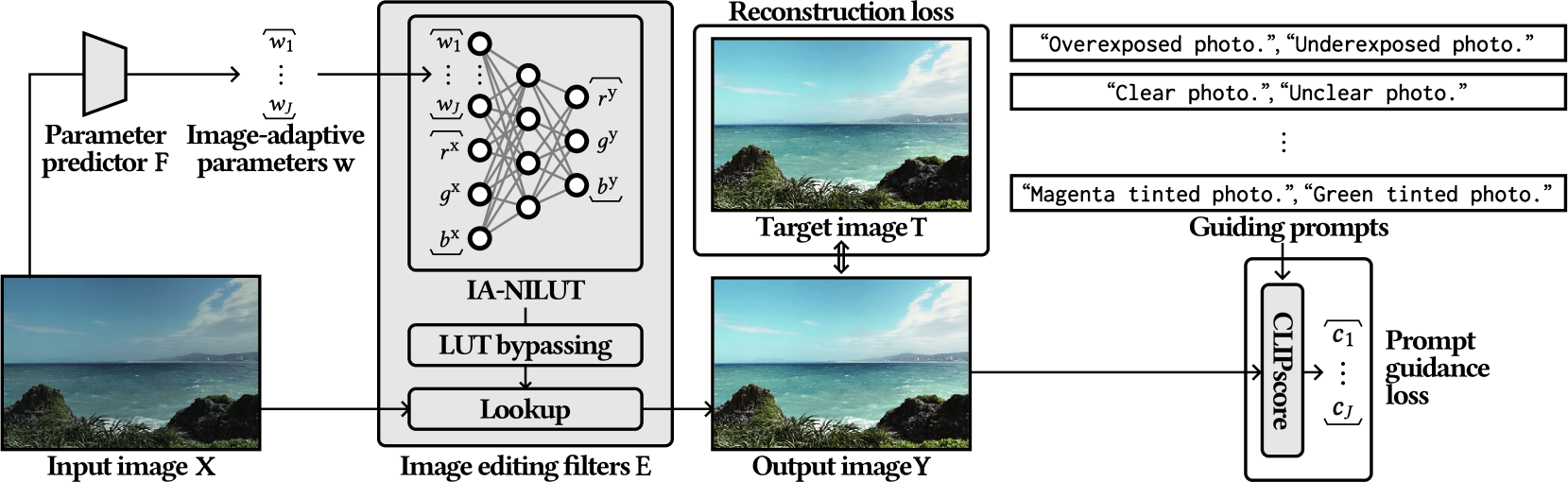
In this paper, we delve into the concept of interpretable image enhancement, a technique that enhances image quality by adjusting filter parameters with easily understandable names such as Exposure and Contrast. Unlike using predefined image editing filters, our framework utilizes learnable filters that acquire interpretable names through training. Our contribution is two-fold. Firstly, we introduce a novel filter architecture called an image-adaptive neural implicit lookup table, which uses a multilayer perceptron to implicitly define the transformation from input feature space to output color space. By incorporating image-adaptive parameters directly into the input features, we achieve highly expressive filters. Secondly, we introduce a prompt guidance loss to assign interpretable names to each filter. We evaluate visual impressions of enhancement results, such as exposure and contrast, using a vision and language model along with guiding prompts. We define a constraint to ensure that each filter affects only the targeted visual impression without influencing other attributes, which allows us to obtain the desired filter effects. Experimental results show that our method outperforms existing predefined filter-based methods, thanks to the filters optimized to predict target results. Our source code is available at https://github.com/satoshi-kosugi/PG-IA-NILUT.
Read more8/21/2024
0
LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation
Jiacheng Li, Chang Chen, Fenglong Song, Youliang Yan, Zhiwei Xiong
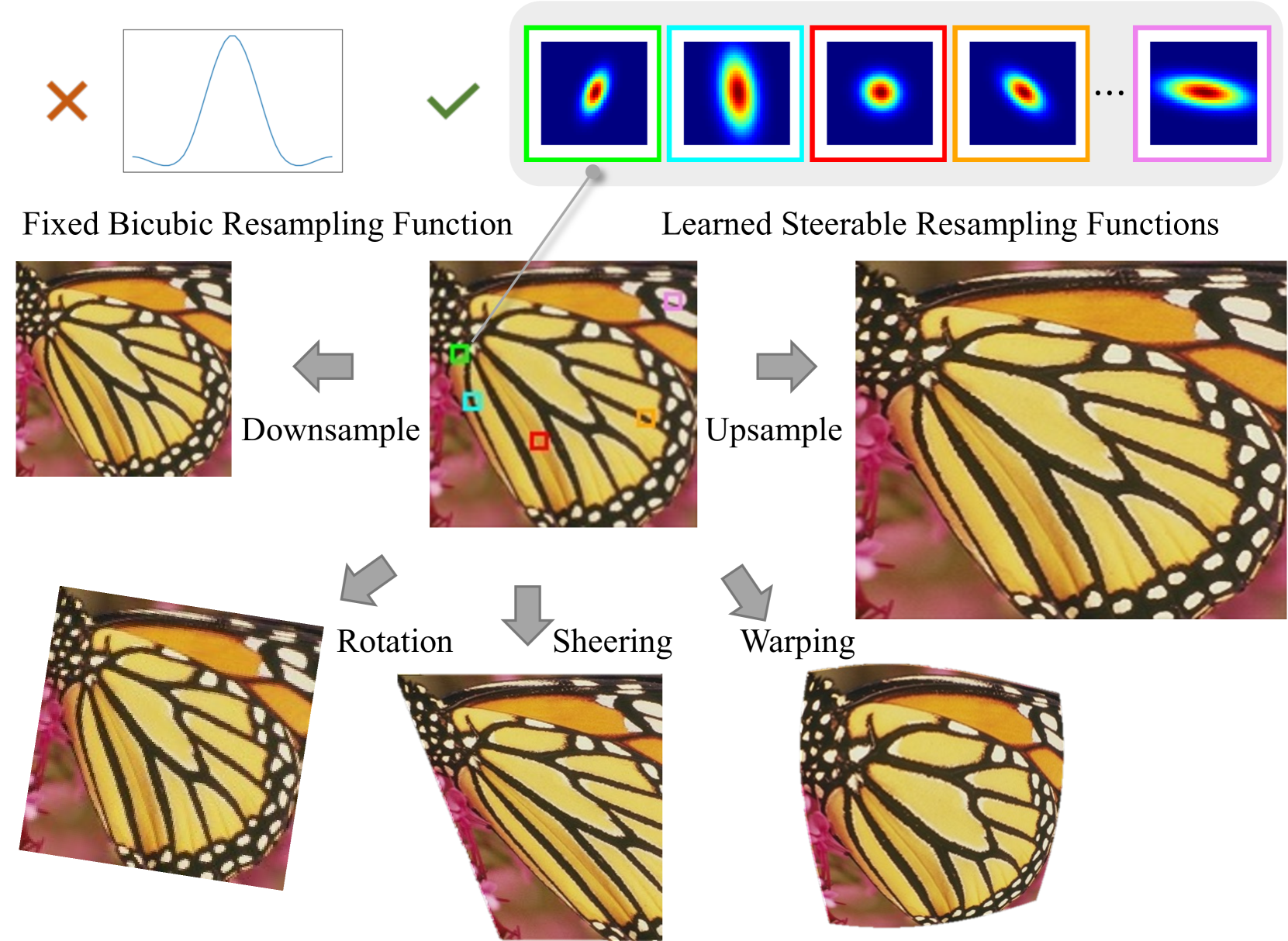
Image resampling is a basic technique that is widely employed in daily applications, such as camera photo editing. Recent deep neural networks (DNNs) have made impressive progress in performance by introducing learned data priors. Still, these methods are not the perfect substitute for interpolation, due to the drawbacks in efficiency and versatility. In this work, we propose a novel method of Learning Resampling Function (termed LeRF), which takes advantage of both the structural priors learned by DNNs and the locally continuous assumption of interpolation. Specifically, LeRF assigns spatially varying resampling functions to input image pixels and learns to predict the hyper-parameters that determine the shapes of these resampling functions with a neural network. Based on the formulation of LeRF, we develop a family of models, including both efficiency-orientated and performance-orientated ones. To achieve interpolation-level efficiency, we adopt look-up tables (LUTs) to accelerate the inference of the learned neural network. Furthermore, we design a directional ensemble strategy and edge-sensitive indexing patterns to better capture local structures. On the other hand, to obtain DNN-level performance, we propose an extension of LeRF to enable it in cooperation with pre-trained upsampling models for cascaded resampling. Extensive experiments show that the efficiency-orientated version of LeRF runs as fast as interpolation, generalizes well to arbitrary transformations, and outperforms interpolation significantly, e.g., up to 3dB PSNR gain over Bicubic for x2 upsampling on Manga109. Besides, the performance-orientated version of LeRF reaches comparable performance with existing DNNs at much higher efficiency, e.g., less than 25% running time on a desktop GPU.
Read more7/16/2024