Less is More: Hop-Wise Graph Attention for Scalable and Generalizable Learning on Circuits
2403.01317
0
0
Abstract
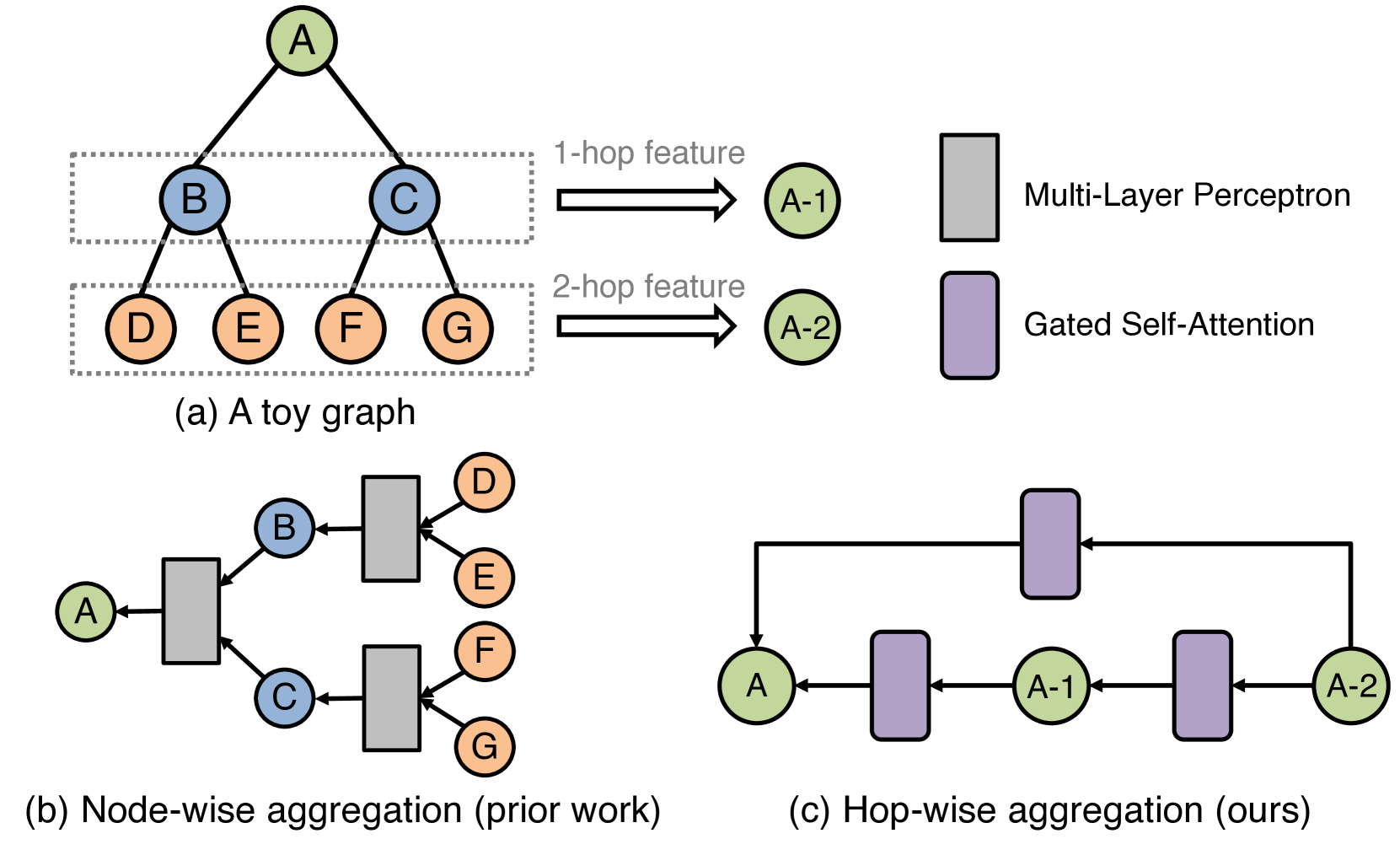
While graph neural networks (GNNs) have gained popularity for learning circuit representations in various electronic design automation (EDA) tasks, they face challenges in scalability when applied to large graphs and exhibit limited generalizability to new designs. These limitations make them less practical for addressing large-scale, complex circuit problems. In this work we propose HOGA, a novel attention-based model for learning circuit representations in a scalable and generalizable manner. HOGA first computes hop-wise features per node prior to model training. Subsequently, the hop-wise features are solely used to produce node representations through a gated self-attention module, which adaptively learns important features among different hops without involving the graph topology. As a result, HOGA is adaptive to various structures across different circuits and can be efficiently trained in a distributed manner. To demonstrate the efficacy of HOGA, we consider two representative EDA tasks: quality of results (QoR) prediction and functional reasoning. Our experimental results indicate that (1) HOGA reduces estimation error over conventional GNNs by 46.76% for predicting QoR after logic synthesis; (2) HOGA improves 10.0% reasoning accuracy over GNNs for identifying functional blocks on unseen gate-level netlists after complex technology mapping; (3) The training time for HOGA almost linearly decreases with an increase in computing resources.
Create account to get full access
Overview
- This paper introduces a new graph attention mechanism called "Hop-Wise Graph Attention" that can improve the scalability and generalizability of learning on circuits.
- The approach focuses on selectively attending to neighbors within a fixed number of hops, rather than considering all neighbors, which can make training and inference more efficient.
- Experiments on circuit design tasks demonstrate that the proposed method outperforms state-of-the-art graph neural network models in terms of both accuracy and inference speed.
Plain English Explanation
The paper presents a new way of analyzing and learning from graphs, which are mathematical structures that can represent complex interconnected systems like electrical circuits. Traditionally, graph neural networks (GNNs) - a type of machine learning model for graphs - have considered all the neighbors of each node when making predictions. However, this can make the models slow and hard to train, especially for large graphs.
The key innovation in this paper is a "hop-wise" attention mechanism, which means the model only pays attention to nodes that are within a fixed number of "hops" or steps away, rather than all neighbors. This selective attention can make the models more efficient and scalable, without sacrificing their ability to learn important patterns in the graph structure.
The authors test their hop-wise attention approach on the task of predicting properties of electrical circuits, such as their behavior or performance. They show that their model outperforms other state-of-the-art GNN models in terms of both accuracy and speed. This suggests the hop-wise attention mechanism is a promising technique for building more practical and generalizable machine learning systems for working with complex interconnected data, like distributed representations of entities in open-world knowledge graphs or heterogeneous graph neural networks for contrastive learning.
Technical Explanation
The paper introduces a new graph attention mechanism called "Hop-Wise Graph Attention" that selectively attends to neighbors within a fixed number of hops, rather than considering all neighbors as done in standard graph attention networks.
The key innovation is that instead of attending to all neighbors of a node, the proposed method only attends to neighbors within a fixed number of hops (e.g., 2-hop neighbors). This reduces the computational complexity of the attention mechanism, making the models more scalable and efficient, while still preserving the ability to capture relevant structural information.
The authors evaluate their Hop-Wise Graph Attention approach on several circuit design tasks, including predicting circuit performance metrics and classifying circuit netlists. They compare their method to state-of-the-art GNN models like GVT: Graph-based Vision Transformer and HEN: Hyperedge Interaction-Aware Hypergraph Neural Network.
The results show that the Hop-Wise Graph Attention model outperforms these baselines in terms of both predictive accuracy and inference speed, demonstrating the benefits of the selective attention mechanism. The authors also provide insights into the importance of different hop-sizes and the trade-offs between model complexity and performance.
Critical Analysis
The paper presents a novel and promising approach to improving the scalability and generalizability of graph neural networks, which is an important challenge in the field of machine learning for graphs and relational data.
One potential limitation of the Hop-Wise Graph Attention mechanism is that it may not be able to capture long-range dependencies in the graph structure, as it only considers a fixed number of hops. This could be addressed by exploring adaptive or multi-scale attention mechanisms that can dynamically adjust the hop-size based on the specific task or graph characteristics.
Additionally, the paper focuses primarily on circuit design tasks, and it would be valuable to evaluate the Hop-Wise Graph Attention approach on a wider range of graph-based problems, such as effective neural models for circuit netlist or contrastive learning on heterogeneous graphs, to further demonstrate its generalizability.
Overall, the paper presents a compelling and well-executed study that introduces a novel graph attention mechanism with practical benefits. The findings suggest that selectively attending to local neighborhoods can be a promising direction for building more efficient and scalable graph neural networks.
Conclusion
This paper introduces a new graph attention mechanism called "Hop-Wise Graph Attention" that can improve the scalability and generalizability of learning on circuits and other graph-structured data. By selectively attending to neighbors within a fixed number of hops, rather than all neighbors, the proposed approach can make training and inference more efficient without sacrificing predictive performance.
The authors demonstrate the effectiveness of their Hop-Wise Graph Attention model on various circuit design tasks, where it outperforms state-of-the-art graph neural network models in terms of both accuracy and inference speed. This work suggests that selective attention mechanisms can be a valuable tool for building more practical and scalable machine learning systems for complex, interconnected data.
The findings of this paper have the potential to advance the field of graph-based machine learning and enable more efficient and generalizable applications in domains like effective neural models for circuit netlist, contrastive learning on heterogeneous graphs, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Advancing Graph Neural Networks with HL-HGAT: A Hodge-Laplacian and Attention Mechanism Approach for Heterogeneous Graph-Structured Data
Jinghan Huang, Qiufeng Chen, Yijun Bian, Pengli Zhu, Nanguang Chen, Moo K. Chung, Anqi Qiu
0
0
Graph neural networks (GNNs) have proven effective in capturing relationships among nodes in a graph. This study introduces a novel perspective by considering a graph as a simplicial complex, encompassing nodes, edges, triangles, and $k$-simplices, enabling the definition of graph-structured data on any $k$-simplices. Our contribution is the Hodge-Laplacian heterogeneous graph attention network (HL-HGAT), designed to learn heterogeneous signal representations across $k$-simplices. The HL-HGAT incorporates three key components: HL convolutional filters (HL-filters), simplicial projection (SP), and simplicial attention pooling (SAP) operators, applied to $k$-simplices. HL-filters leverage the unique topology of $k$-simplices encoded by the Hodge-Laplacian (HL) operator, operating within the spectral domain of the $k$-th HL operator. To address computation challenges, we introduce a polynomial approximation for HL-filters, exhibiting spatial localization properties. Additionally, we propose a pooling operator to coarsen $k$-simplices, combining features through simplicial attention mechanisms of self-attention and cross-attention via transformers and SP operators, capturing topological interconnections across multiple dimensions of simplices. The HL-HGAT is comprehensively evaluated across diverse graph applications, including NP-hard problems, graph multi-label and classification challenges, and graph regression tasks in logistics, computer vision, biology, chemistry, and neuroscience. The results demonstrate the model's efficacy and versatility in handling a wide range of graph-based scenarios.
4/23/2024

Hyperbolic Heterogeneous Graph Attention Networks
Jongmin Park, Seunghoon Han, Soohwan Jeong, Sungsu Lim
0
0
Most previous heterogeneous graph embedding models represent elements in a heterogeneous graph as vector representations in a low-dimensional Euclidean space. However, because heterogeneous graphs inherently possess complex structures, such as hierarchical or power-law structures, distortions can occur when representing them in Euclidean space. To overcome this limitation, we propose Hyperbolic Heterogeneous Graph Attention Networks (HHGAT) that learn vector representations in hyperbolic spaces with meta-path instances. We conducted experiments on three real-world heterogeneous graph datasets, demonstrating that HHGAT outperforms state-of-the-art heterogeneous graph embedding models in node classification and clustering tasks.
4/16/2024
Demystifying Higher-Order Graph Neural Networks
Maciej Besta, Florian Scheidl, Lukas Gianinazzi, Shachar Klaiman, Jurgen Muller, Torsten Hoefler
0
0
Higher-order graph neural networks (HOGNNs) are an important class of GNN models that harness polyadic relations between vertices beyond plain edges. They have been used to eliminate issues such as over-smoothing or over-squashing, to significantly enhance the accuracy of GNN predictions, to improve the expressiveness of GNN architectures, and for numerous other goals. A plethora of HOGNN models have been introduced, and they come with diverse neural architectures, and even with different notions of what the higher-order means. This richness makes it very challenging to appropriately analyze and compare HOGNN models, and to decide in what scenario to use specific ones. To alleviate this, we first design an in-depth taxonomy and a blueprint for HOGNNs. This facilitates designing models that maximize performance. Then, we use our taxonomy to analyze and compare the available HOGNN models. The outcomes of our analysis are synthesized in a set of insights that help to select the most beneficial GNN model in a given scenario, and a comprehensive list of challenges and opportunities for further research into more powerful HOGNNs.
6/19/2024
🌐
Heterophily-Aware Graph Attention Network
Junfu Wang, Yuanfang Guo, Liang Yang, Yunhong Wang
0
0
Graph Neural Networks (GNNs) have shown remarkable success in graph representation learning. Unfortunately, current weight assignment schemes in standard GNNs, such as the calculation based on node degrees or pair-wise representations, can hardly be effective in processing the networks with heterophily, in which the connected nodes usually possess different labels or features. Existing heterophilic GNNs tend to ignore the modeling of heterophily of each edge, which is also a vital part in tackling the heterophily problem. In this paper, we firstly propose a heterophily-aware attention scheme and reveal the benefits of modeling the edge heterophily, i.e., if a GNN assigns different weights to edges according to different heterophilic types, it can learn effective local attention patterns, which enable nodes to acquire appropriate information from distinct neighbors. Then, we propose a novel Heterophily-Aware Graph Attention Network (HA-GAT) by fully exploring and utilizing the local distribution as the underlying heterophily, to handle the networks with different homophily ratios. To demonstrate the effectiveness of the proposed HA-GAT, we analyze the proposed heterophily-aware attention scheme and local distribution exploration, by seeking for an interpretation from their mechanism. Extensive results demonstrate that our HA-GAT achieves state-of-the-art performances on eight datasets with different homophily ratios in both the supervised and semi-supervised node classification tasks.
7/2/2024